 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising distances beyond the volumetric barrier
Apr 01, 2026We study the problem of reconstructing the latent geometry of a $d$-dimensional Riemannian manifold from a random geometric graph. While recent works have made significant progress in manifold recovery from random geometric graphs, and more generally from noisy distances, the precision of pairwise distance estimation has been fundamentally constrained by the volumetric barrier, namely the natural sample-spacing scale $n^{-1/d}$ coming from the fact that a generic point of the manifold typically lies at distance of order $n^{-1/d}$ from the nearest sampled point. In this paper, we introduce a novel approach, Orthogonal Ring Distance Estimation Routine (ORDER), which achieves a pointwise distance estimation precision of order $n^{-2/(d+5)}$ up to polylogarithmic factors in $n$ in polynomial time. This strictly beats the volumetric barrier for dimensions $d > 5$. As a consequence of obtaining pointwise precision better than $n^{-1/d}$, we prove that the Gromov--Wasserstein distance between the reconstructed metric measure space and the true latent manifold is of order $n^{-1/d}$. This matches the Wasserstein convergence rate of empirical measures, demonstrating that our reconstructed graph metric is asymptotically as good as having access to the full pairwise distance matrix of the sampled points. Our results are proven in a very general setting which includes general models of noisy pairwise distances, sparse random geometric graphs, and unknown connection probability functions.
Efficient Generative AI Boosts Probabilistic Forecasting of Sudden Stratospheric Warmings
Oct 30, 2025Sudden Stratospheric Warmings (SSWs) are key sources of subseasonal predictability and major drivers of extreme winter weather. Yet, their accurate and efficient forecast remains a persistent challenge for numerical weather prediction (NWP) systems due to limitations in physical representation, initialization, and the immense computational demands of ensemble forecasts. While data-driven forecasting is rapidly evolving, its application to the complex, three-dimensional dynamics of SSWs, particularly for probabilistic forecast, remains underexplored. Here, we bridge this gap by developing a Flow Matching-based generative AI model (FM-Cast) for efficient and skillful probabilistic forecasting of the spatiotemporal evolution of stratospheric circulation. Evaluated across 18 major SSW events (1998-2024), FM-Cast skillfully forecasts the onset, intensity, and morphology of 10 events up to 20 days in advance, achieving ensemble accuracies above 50%. Its performance is comparable to or exceeds leading NWP systems while requiring only two minutes for a 50-member, 30-day forecast on a consumer GPU. Furthermore, leveraging FM-Cast as a scientific tool, we demonstrate through idealized experiments that SSW predictability is fundamentally linked to its underlying physical drivers, distinguishing between events forced from the troposphere and those driven by internal stratospheric dynamics. Our work thus establishes a computationally efficient paradigm for probabilistic forecasting stratospheric anomalies and showcases generative AI's potential to deepen the physical understanding of atmosphere-climate dynamics.
SliceSemOcc: Vertical Slice Based Multimodal 3D Semantic Occupancy Representation
Sep 04, 2025Driven by autonomous driving's demands for precise 3D perception, 3D semantic occupancy prediction has become a pivotal research topic. Unlike bird's-eye-view (BEV) methods, which restrict scene representation to a 2D plane, occupancy prediction leverages a complete 3D voxel grid to model spatial structures in all dimensions, thereby capturing semantic variations along the vertical axis. However, most existing approaches overlook height-axis information when processing voxel features. And conventional SENet-style channel attention assigns uniform weight across all height layers, limiting their ability to emphasize features at different heights. To address these limitations, we propose SliceSemOcc, a novel vertical slice based multimodal framework for 3D semantic occupancy representation. Specifically, we extract voxel features along the height-axis using both global and local vertical slices. Then, a global local fusion module adaptively reconciles fine-grained spatial details with holistic contextual information. Furthermore, we propose the SEAttention3D module, which preserves height-wise resolution through average pooling and assigns dynamic channel attention weights to each height layer. Extensive experiments on nuScenes-SurroundOcc and nuScenes-OpenOccupancy datasets verify that our method significantly enhances mean IoU, achieving especially pronounced gains on most small-object categories. Detailed ablation studies further validate the effectiveness of the proposed SliceSemOcc framework.
An Experimental Approach for Running-Time Estimation of Multi-objective Evolutionary Algorithms in Numerical Optimization
Jul 03, 2025Multi-objective evolutionary algorithms (MOEAs) have become essential tools for solving multi-objective optimization problems (MOPs), making their running time analysis crucial for assessing algorithmic efficiency and guiding practical applications. While significant theoretical advances have been achieved for combinatorial optimization, existing studies for numerical optimization primarily rely on algorithmic or problem simplifications, limiting their applicability to real-world scenarios. To address this gap, we propose an experimental approach for estimating upper bounds on the running time of MOEAs in numerical optimization without simplification assumptions. Our approach employs an average gain model that characterizes algorithmic progress through the Inverted Generational Distance metric. To handle the stochastic nature of MOEAs, we use statistical methods to estimate the probabilistic distribution of gains. Recognizing that gain distributions in numerical optimization exhibit irregular patterns with varying densities across different regions, we introduce an adaptive sampling method that dynamically adjusts sampling density to ensure accurate surface fitting for running time estimation. We conduct comprehensive experiments on five representative MOEAs (NSGA-II, MOEA/D, AR-MOEA, AGEMOEA-II, and PREA) using the ZDT and DTLZ benchmark suites. The results demonstrate the effectiveness of our approach in estimating upper bounds on the running time without requiring algorithmic or problem simplifications. Additionally, we provide a web-based implementation to facilitate broader adoption of our methodology. This work provides a practical complement to theoretical research on MOEAs in numerical optimization.
Running-time Analysis of ($μ+λ$) Evolutionary Combinatorial Optimization Based on Multiple-gain Estimation
Jul 03, 2025The running-time analysis of evolutionary combinatorial optimization is a fundamental topic in evolutionary computation. However, theoretical results regarding the $(\mu+\lambda)$ evolutionary algorithm (EA) for combinatorial optimization problems remain relatively scarce compared to those for simple pseudo-Boolean problems. This paper proposes a multiple-gain model to analyze the running time of EAs for combinatorial optimization problems. The proposed model is an improved version of the average gain model, which is a fitness-difference drift approach under the sigma-algebra condition to estimate the running time of evolutionary numerical optimization. The improvement yields a framework for estimating the expected first hitting time of a stochastic process in both average-case and worst-case scenarios. It also introduces novel running-time results of evolutionary combinatorial optimization, including two tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the knapsack problem with favorably correlated weights, a closed-form expression of time complexity upper bound in the case of ($\mu+\lambda$) EA for general $k$-MAX-SAT problems and a tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the traveling salesperson problem. Experimental results indicate that the practical running time aligns with the theoretical results, verifying that the multiple-gain model is an effective tool for running-time analysis of ($\mu+\lambda$) EA for combinatorial optimization problems.
Depth3DLane: Monocular 3D Lane Detection via Depth Prior Distillation
Apr 25, 2025



Monocular 3D lane detection is challenging due to the difficulty in capturing depth information from single-camera images. A common strategy involves transforming front-view (FV) images into bird's-eye-view (BEV) space through inverse perspective mapping (IPM), facilitating lane detection using BEV features. However, IPM's flat-ground assumption and loss of contextual information lead to inaccuracies in reconstructing 3D information, especially height. In this paper, we introduce a BEV-based framework to address these limitations and improve 3D lane detection accuracy. Our approach incorporates a Hierarchical Depth-Aware Head that provides multi-scale depth features, mitigating the flat-ground assumption by enhancing spatial awareness across varying depths. Additionally, we leverage Depth Prior Distillation to transfer semantic depth knowledge from a teacher model, capturing richer structural and contextual information for complex lane structures. To further refine lane continuity and ensure smooth lane reconstruction, we introduce a Conditional Random Field module that enforces spatial coherence in lane predictions. Extensive experiments validate that our method achieves state-of-the-art performance in terms of z-axis error and outperforms other methods in the field in overall performance. The code is released at: https://anonymous.4open.science/r/Depth3DLane-DCDD.
NExT-Mol: 3D Diffusion Meets 1D Language Modeling for 3D Molecule Generation
Feb 18, 20253D molecule generation is crucial for drug discovery and material design. While prior efforts focus on 3D diffusion models for their benefits in modeling continuous 3D conformers, they overlook the advantages of 1D SELFIES-based Language Models (LMs), which can generate 100% valid molecules and leverage the billion-scale 1D molecule datasets. To combine these advantages for 3D molecule generation, we propose a foundation model -- NExT-Mol: 3D Diffusion Meets 1D Language Modeling for 3D Molecule Generation. NExT-Mol uses an extensively pretrained molecule LM for 1D molecule generation, and subsequently predicts the generated molecule's 3D conformers with a 3D diffusion model. We enhance NExT-Mol's performance by scaling up the LM's model size, refining the diffusion neural architecture, and applying 1D to 3D transfer learning. Notably, our 1D molecule LM significantly outperforms baselines in distributional similarity while ensuring validity, and our 3D diffusion model achieves leading performances in conformer prediction. Given these improvements in 1D and 3D modeling, NExT-Mol achieves a 26% relative improvement in 3D FCD for de novo 3D generation on GEOM-DRUGS, and a 13% average relative gain for conditional 3D generation on QM9-2014. Our codes and pretrained checkpoints are available at https://github.com/acharkq/NExT-Mol.
Multiple-gain Estimation for Running Time of Evolutionary Combinatorial Optimization
Jan 13, 2025



The running-time analysis of evolutionary combinatorial optimization is a fundamental topic in evolutionary computation. Its current research mainly focuses on specific algorithms for simplified problems due to the challenge posed by fluctuating fitness values. This paper proposes a multiple-gain model to estimate the fitness trend of population during iterations. The proposed model is an improved version of the average gain model, which is the approach to estimate the running time of evolutionary algorithms for numerical optimization. The improvement yields novel results of evolutionary combinatorial optimization, including a briefer proof for the time complexity upper bound in the case of (1+1) EA for the Onemax problem, two tighter time complexity upper bounds than the known results in the case of (1+$\lambda$) EA for the knapsack problem with favorably correlated weights and a closed-form expression of time complexity upper bound in the case of (1+$\lambda$) EA for general $k$-MAX-SAT problems. The results indicate that the practical running time aligns with the theoretical results, verifying that the multiple-gain model is more general for running-time analysis of evolutionary combinatorial optimization than state-of-the-art methods.
FatesGS: Fast and Accurate Sparse-View Surface Reconstruction using Gaussian Splatting with Depth-Feature Consistency
Jan 08, 2025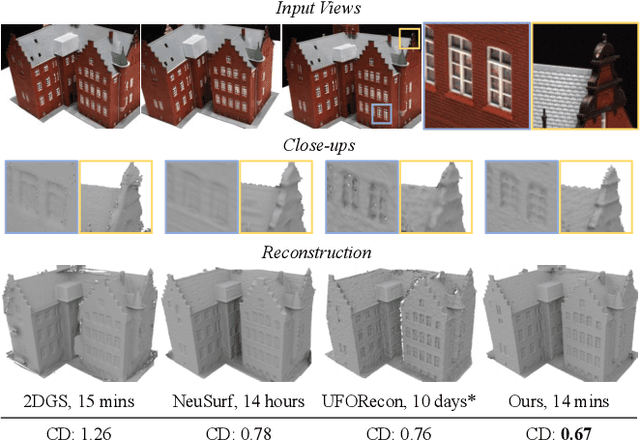

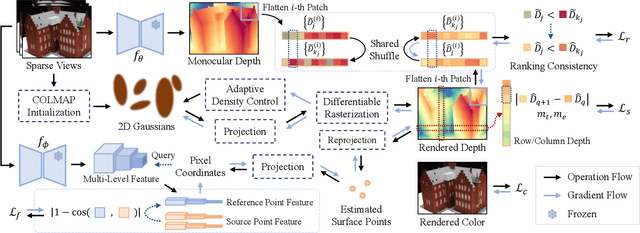
Recently, Gaussian Splatting has sparked a new trend in the field of computer vision. Apart from novel view synthesis, it has also been extended to the area of multi-view reconstruction. The latest methods facilitate complete, detailed surface reconstruction while ensuring fast training speed. However, these methods still require dense input views, and their output quality significantly degrades with sparse views. We observed that the Gaussian primitives tend to overfit the few training views, leading to noisy floaters and incomplete reconstruction surfaces. In this paper, we present an innovative sparse-view reconstruction framework that leverages intra-view depth and multi-view feature consistency to achieve remarkably accurate surface reconstruction. Specifically, we utilize monocular depth ranking information to supervise the consistency of depth distribution within patches and employ a smoothness loss to enhance the continuity of the distribution. To achieve finer surface reconstruction, we optimize the absolute position of depth through multi-view projection features. Extensive experiments on DTU and BlendedMVS demonstrate that our method outperforms state-of-the-art methods with a speedup of 60x to 200x, achieving swift and fine-grained mesh reconstruction without the need for costly pre-training.
Sparis: Neural Implicit Surface Reconstruction of Indoor Scenes from Sparse Views
Jan 02, 2025



In recent years, reconstructing indoor scene geometry from multi-view images has achieved encouraging accomplishments. Current methods incorporate monocular priors into neural implicit surface models to achieve high-quality reconstructions. However, these methods require hundreds of images for scene reconstruction. When only a limited number of views are available as input, the performance of monocular priors deteriorates due to scale ambiguity, leading to the collapse of the reconstructed scene geometry. In this paper, we propose a new method, named Sparis, for indoor surface reconstruction from sparse views. Specifically, we investigate the impact of monocular priors on sparse scene reconstruction, introducing a novel prior based on inter-image matching information. Our prior offers more accurate depth information while ensuring cross-view matching consistency. Additionally, we employ an angular filter strategy and an epipolar matching weight function, aiming to reduce errors due to view matching inaccuracies, thereby refining the inter-image prior for improved reconstruction accuracy. The experiments conducted on widely used benchmarks demonstrate superior performance in sparse-view scene reconstruction.