 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Design Space of Visual Context Representation in Video MLLMs
Paper and Code
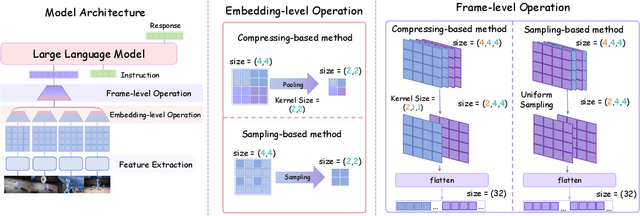
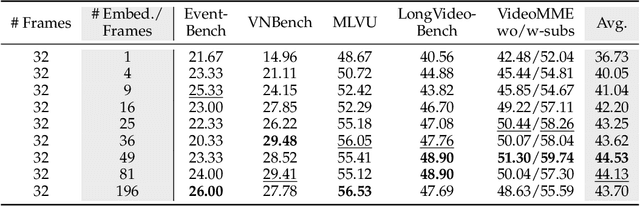
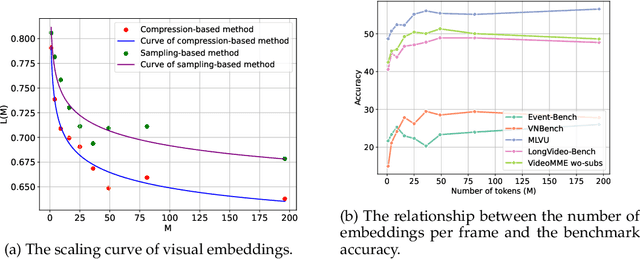
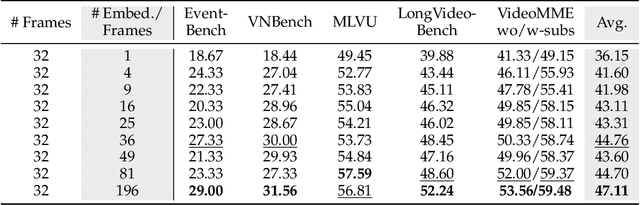
Video Multimodal Large Language Models (MLLMs) have shown remarkable capability of understanding the video semantics on various downstream tasks. Despite the advancements, there is still a lack of systematic research on visual context representation, which refers to the scheme to select frames from a video and further select the tokens from a frame. In this paper, we explore the design space for visual context representation, and aim to improve the performance of video MLLMs by finding more effective representation schemes. Firstly, we formulate the task of visual context representation as a constrained optimization problem, and model the language modeling loss as a function of the number of frames and the number of embeddings (or tokens) per frame, given the maximum visual context window size. Then, we explore the scaling effects in frame selection and token selection respectively, and fit the corresponding function curve by conducting extensive empirical experiments. We examine the effectiveness of typical selection strategies and present empirical findings to determine the two factors. Furthermore, we study the joint effect of frame selection and token selection, and derive the optimal formula for determining the two factors. We demonstrate that the derived optimal settings show alignment with the best-performed results of empirical experiments. Our code and model are available at: https://github.com/RUCAIBox/Opt-Visor.