 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Motion-Aware Video MLLM
Mar 17, 2025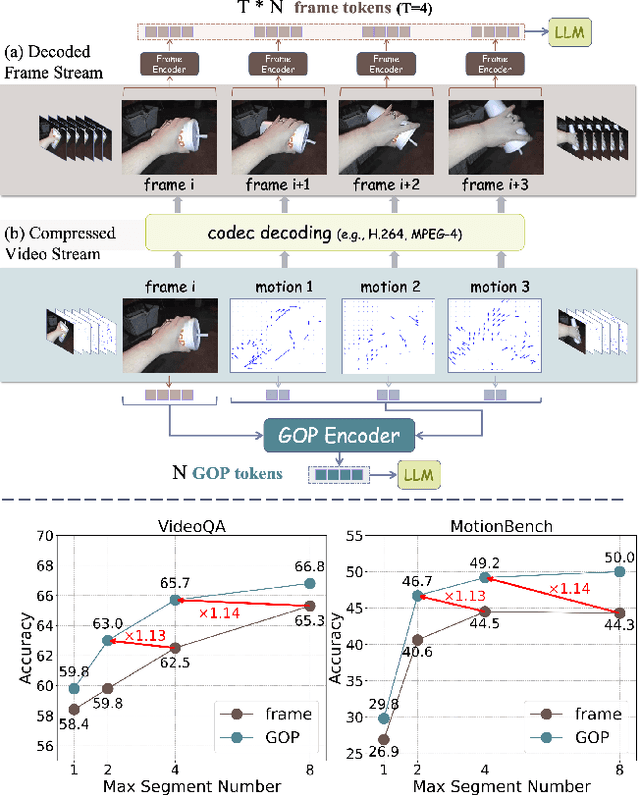
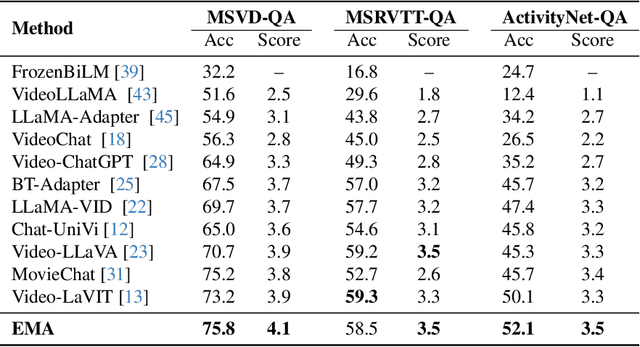
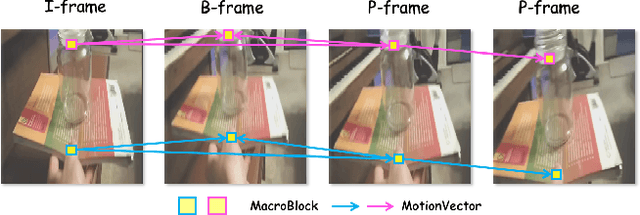
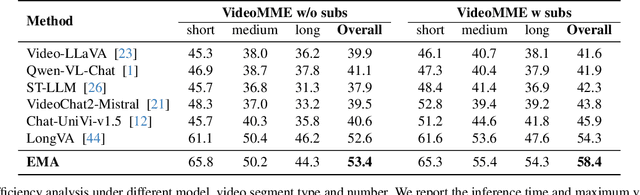
Most current video MLLMs rely on uniform frame sampling and image-level encoders, resulting in inefficient data processing and limited motion awareness. To address these challenges, we introduce EMA, an Efficient Motion-Aware video MLLM that utilizes compressed video structures as inputs. We propose a motion-aware GOP (Group of Pictures) encoder that fuses spatial and motion information within a GOP unit in the compressed video stream, generating compact, informative visual tokens. By integrating fewer but denser RGB frames with more but sparser motion vectors in this native slow-fast input architecture, our approach reduces redundancy and enhances motion representation. Additionally, we introduce MotionBench, a benchmark for evaluating motion understanding across four motion types: linear, curved, rotational, and contact-based. Experimental results show that EMA achieves state-of-the-art performance on both MotionBench and popular video question answering benchmarks, while reducing inference costs. Moreover, EMA demonstrates strong scalability, as evidenced by its competitive performance on long video understanding benchmarks.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Virgo: A Preliminary Exploration on Reproducing o1-like MLLM
Jan 03, 2025Recently, slow-thinking reasoning systems, built upon large language models (LLMs), have garnered widespread attention by scaling the thinking time during inference. There is also growing interest in adapting this capability to multimodal large language models (MLLMs). Given that MLLMs handle more complex data semantics across different modalities, it is intuitively more challenging to implement multimodal slow-thinking systems. To address this issue, in this paper, we explore a straightforward approach by fine-tuning a capable MLLM with a small amount of textual long-form thought data, resulting in a multimodal slow-thinking system, Virgo (Visual reasoning with long thought). We find that these long-form reasoning processes, expressed in natural language, can be effectively transferred to MLLMs. Moreover, it seems that such textual reasoning data can be even more effective than visual reasoning data in eliciting the slow-thinking capacities of MLLMs. While this work is preliminary, it demonstrates that slow-thinking capacities are fundamentally associated with the language model component, which can be transferred across modalities or domains. This finding can be leveraged to guide the development of more powerful slow-thinking reasoning systems. We release our resources at https://github.com/RUCAIBox/Virgo.
Beyond Filtering: Adaptive Image-Text Quality Enhancement for MLLM Pretraining
Oct 21, 2024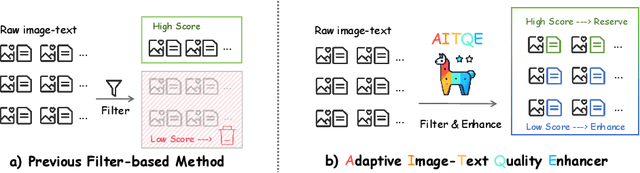



Multimodal large language models (MLLMs) have made significant strides by integrating visual and textual modalities. A critical factor in training MLLMs is the quality of image-text pairs within multimodal pretraining datasets. However, $\textit {de facto}$ filter-based data quality enhancement paradigms often discard a substantial portion of high-quality image data due to inadequate semantic alignment between images and texts, leading to inefficiencies in data utilization and scalability. In this paper, we propose the Adaptive Image-Text Quality Enhancer (AITQE), a model that dynamically assesses and enhances the quality of image-text pairs. AITQE employs a text rewriting mechanism for low-quality pairs and incorporates a negative sample learning strategy to improve evaluative capabilities by integrating deliberately selected low-quality samples during training. Unlike prior approaches that significantly alter text distributions, our method minimally adjusts text to preserve data volume while enhancing quality. Experimental results demonstrate that AITQE surpasses existing methods on various benchmark, effectively leveraging raw data and scaling efficiently with increasing data volumes. We hope our work will inspire future works. The code and model are available at: https://github.com/hanhuang22/AITQE.
Exploring the Design Space of Visual Context Representation in Video MLLMs
Oct 17, 2024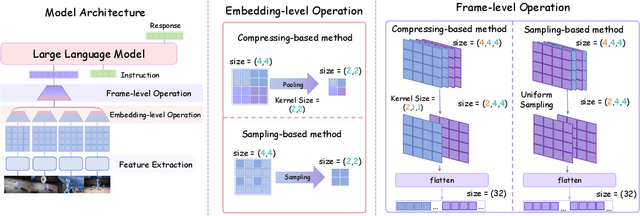
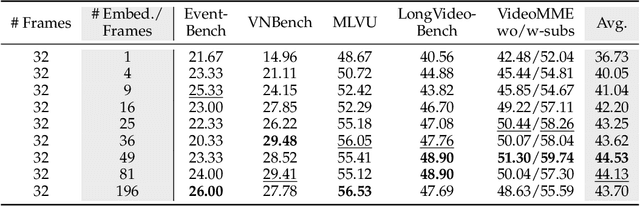
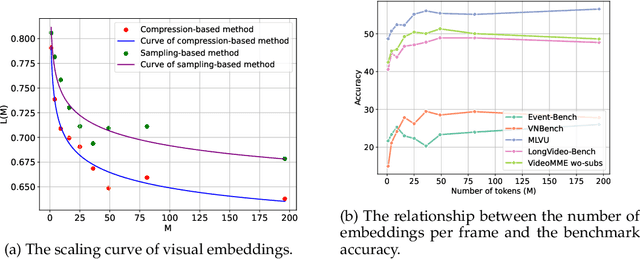
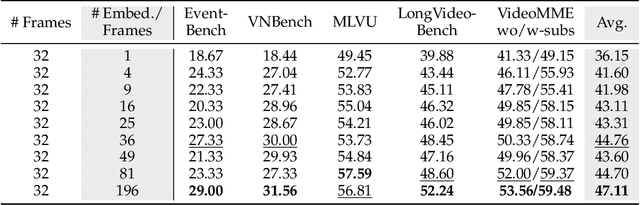
Video Multimodal Large Language Models (MLLMs) have shown remarkable capability of understanding the video semantics on various downstream tasks. Despite the advancements, there is still a lack of systematic research on visual context representation, which refers to the scheme to select frames from a video and further select the tokens from a frame. In this paper, we explore the design space for visual context representation, and aim to improve the performance of video MLLMs by finding more effective representation schemes. Firstly, we formulate the task of visual context representation as a constrained optimization problem, and model the language modeling loss as a function of the number of frames and the number of embeddings (or tokens) per frame, given the maximum visual context window size. Then, we explore the scaling effects in frame selection and token selection respectively, and fit the corresponding function curve by conducting extensive empirical experiments. We examine the effectiveness of typical selection strategies and present empirical findings to determine the two factors. Furthermore, we study the joint effect of frame selection and token selection, and derive the optimal formula for determining the two factors. We demonstrate that the derived optimal settings show alignment with the best-performed results of empirical experiments. Our code and model are available at: https://github.com/RUCAIBox/Opt-Visor.
Baichuan-Omni Technical Report
Oct 11, 2024



The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
Towards Event-oriented Long Video Understanding
Jun 20, 2024



With the rapid development of video Multimodal Large Language Models (MLLMs), numerous benchmarks have been proposed to assess their video understanding capability. However, due to the lack of rich events in the videos, these datasets may suffer from the short-cut bias that the answers can be deduced from a few frames, without the need to watch the entire video. To address this issue, we introduce Event-Bench, an event-oriented long video understanding benchmark built on existing datasets and human annotations. Event-Bench includes six event-related tasks and 2,190 test instances to comprehensively evaluate video event understanding ability. Additionally, we propose Video Instruction Merging~(VIM), a cost-effective method that enhances video MLLMs using merged, event-intensive video instructions, addressing the scarcity of human-annotated, event-intensive data. Extensive experiments show that the best-performing model, GPT-4o, achieves an overall accuracy of 53.33, significantly outperforming the best open-source model by 41.42%. Leveraging an effective instruction synthesis method and an adaptive model architecture, VIM surpasses both state-of-the-art open-source models and GPT-4V on the Event-Bench. All code, data, and models are publicly available at https://github.com/RUCAIBox/Event-Bench.
Needle In A Video Haystack: A Scalable Synthetic Framework for Benchmarking Video MLLMs
Jun 13, 2024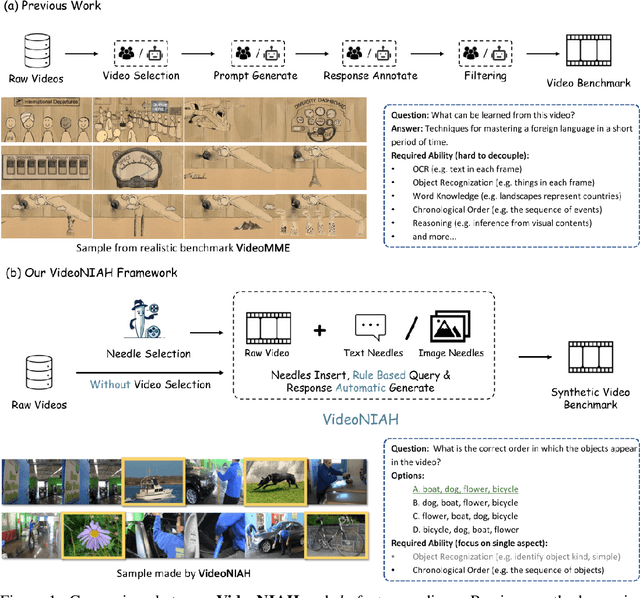
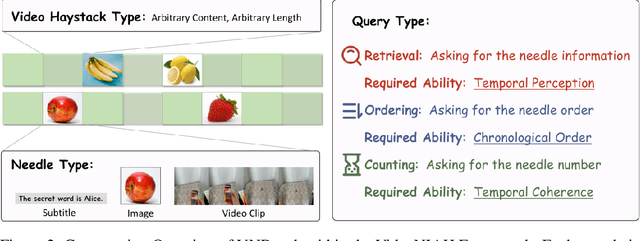
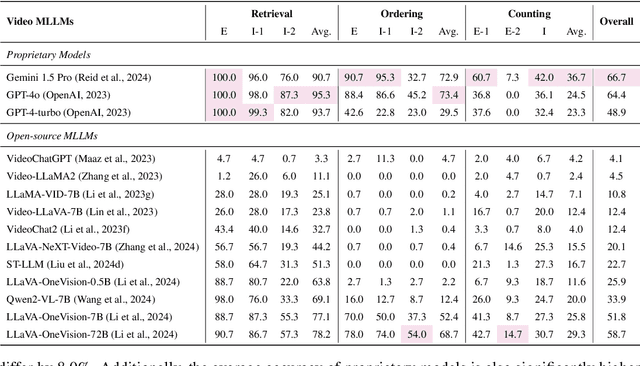
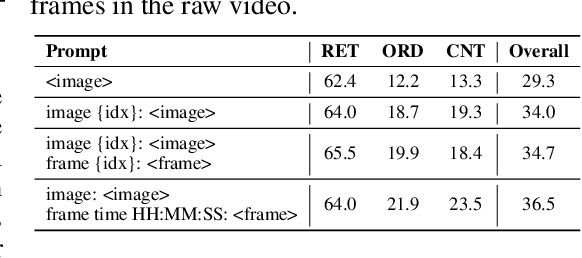
Video understanding is a crucial next step for multimodal large language models (MLLMs). To probe specific aspects of video understanding ability, existing video benchmarks typically require careful video selection based on the target capability, along with laborious annotation of query-response pairs to match the specific video content. This process is both challenging and resource-intensive. In this paper, we propose VideoNIAH (Video Needle In A Haystack), a benchmark construction framework through synthetic video generation. VideoNIAH decouples test video content from their query-responses by inserting unrelated image/text 'needles' into original videos. It generates annotations solely from these needles, ensuring diversity in video sources and a variety of query-responses. Additionally, by inserting multiple needles, VideoNIAH rigorously evaluates the temporal understanding capabilities of models. We utilized VideoNIAH to compile a video benchmark VNBench, including tasks such as retrieval, ordering, and counting. VNBench can efficiently evaluate the fine-grained understanding ability and spatio-temporal modeling ability of a video model, while also supporting the long-context evaluation. Additionally, we evaluated recent video-centric multimodal large language models (MLLMs), both open-source and proprietary, providing a comprehensive analysis. We found that although proprietary models have significant advantages over open-source models, all existing video models still perform poorly on long-distance dependency tasks. VideoNIAH is a simple yet highly scalable benchmark construction framework, and we believe it will inspire future video benchmark works. The code and data are available at https://github.com/joez17/VideoNIAH.
VDT: An Empirical Study on Video Diffusion with Transformers
May 22, 2023This work introduces Video Diffusion Transformer (VDT), which pioneers the use of transformers in diffusion-based video generation. It features transformer blocks with modularized temporal and spatial attention modules, allowing separate optimization of each component and leveraging the rich spatial-temporal representation inherited from transformers. VDT offers several appealing benefits. 1) It excels at capturing temporal dependencies to produce temporally consistent video frames and even simulate the dynamics of 3D objects over time. 2) It enables flexible conditioning information through simple concatenation in the token space, effectively unifying video generation and prediction tasks. 3) Its modularized design facilitates a spatial-temporal decoupled training strategy, leading to improved efficiency. Extensive experiments on video generation, prediction, and dynamics modeling (i.e., physics-based QA) tasks have been conducted to demonstrate the effectiveness of VDT in various scenarios, including autonomous driving, human action, and physics-based simulation. We hope our study on the capabilities of transformer-based video diffusion in capturing accurate temporal dependencies, handling conditioning information, and achieving efficient training will benefit future research and advance the field. Codes and models are available at https://github.com/RERV/VDT.