 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarder Is Better: Boosting Mathematical Reasoning via Difficulty-Aware GRPO and Multi-Aspect Question Reformulation
Jan 28, 2026Reinforcement Learning with Verifiable Rewards (RLVR) offers a robust mechanism for enhancing mathematical reasoning in large models. However, we identify a systematic lack of emphasis on more challenging questions in existing methods from both algorithmic and data perspectives, despite their importance for refining underdeveloped capabilities. Algorithmically, widely used Group Relative Policy Optimization (GRPO) suffers from an implicit imbalance where the magnitude of policy updates is lower for harder questions. Data-wise, augmentation approaches primarily rephrase questions to enhance diversity without systematically increasing intrinsic difficulty. To address these issues, we propose a two-dual MathForge framework to improve mathematical reasoning by targeting harder questions from both perspectives, which comprises a Difficulty-Aware Group Policy Optimization (DGPO) algorithm and a Multi-Aspect Question Reformulation (MQR) strategy. Specifically, DGPO first rectifies the implicit imbalance in GRPO via difficulty-balanced group advantage estimation, and further prioritizes harder questions by difficulty-aware question-level weighting. Meanwhile, MQR reformulates questions across multiple aspects to increase difficulty while maintaining the original gold answer. Overall, MathForge forms a synergistic loop: MQR expands the data frontier, and DGPO effectively learns from the augmented data. Extensive experiments show that MathForge significantly outperforms existing methods on various mathematical reasoning tasks. The code and augmented data are all available at https://github.com/AMAP-ML/MathForge.
Say Cheese! Detail-Preserving Portrait Collection Generation via Natural Language Edits
Jan 28, 2026As social media platforms proliferate, users increasingly demand intuitive ways to create diverse, high-quality portrait collections. In this work, we introduce Portrait Collection Generation (PCG), a novel task that generates coherent portrait collections by editing a reference portrait image through natural language instructions. This task poses two unique challenges to existing methods: (1) complex multi-attribute modifications such as pose, spatial layout, and camera viewpoint; and (2) high-fidelity detail preservation including identity, clothing, and accessories. To address these challenges, we propose CHEESE, the first large-scale PCG dataset containing 24K portrait collections and 573K samples with high-quality modification text annotations, constructed through an Large Vison-Language Model-based pipeline with inversion-based verification. We further propose SCheese, a framework that combines text-guided generation with hierarchical identity and detail preservation. SCheese employs adaptive feature fusion mechanism to maintain identity consistency, and ConsistencyNet to inject fine-grained features for detail consistency. Comprehensive experiments validate the effectiveness of CHEESE in advancing PCG, with SCheese achieving state-of-the-art performance.
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
May 22, 2025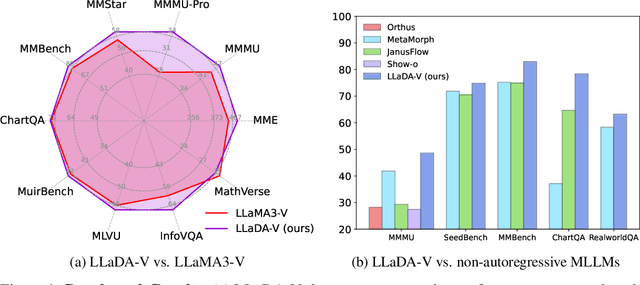
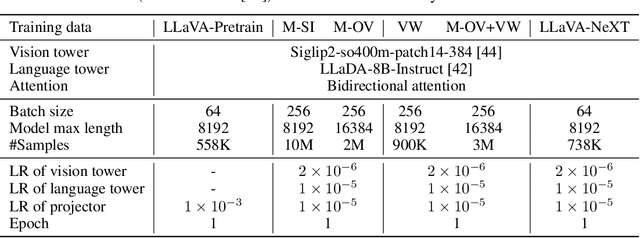
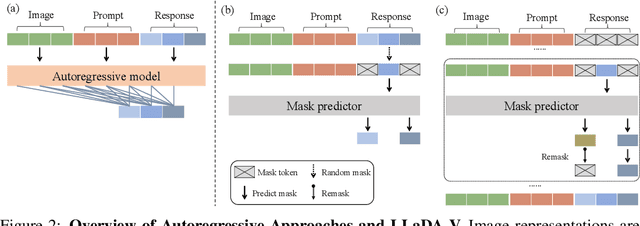
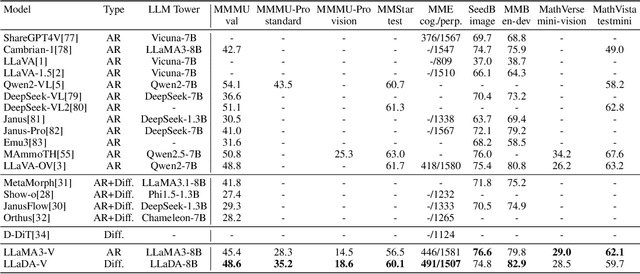
In this work, we introduce LLaDA-V, a purely diffusion-based Multimodal Large Language Model (MLLM) that integrates visual instruction tuning with masked diffusion models, representing a departure from the autoregressive paradigms dominant in current multimodal approaches. Built upon LLaDA, a representative large language diffusion model, LLaDA-V incorporates a vision encoder and MLP connector that projects visual features into the language embedding space, enabling effective multimodal alignment. Our empirical investigation reveals several intriguing results: First, LLaDA-V demonstrates promising multimodal performance despite its language model being weaker on purely textual tasks than counterparts like LLaMA3-8B and Qwen2-7B. When trained on the same instruction data, LLaDA-V is highly competitive to LLaMA3-V across multimodal tasks with better data scalability. It also narrows the performance gap to Qwen2-VL, suggesting the effectiveness of its architecture for multimodal tasks. Second, LLaDA-V achieves state-of-the-art performance in multimodal understanding compared to existing hybrid autoregressive-diffusion and purely diffusion-based MLLMs. Our findings suggest that large language diffusion models show promise in multimodal contexts and warrant further investigation in future research. Project page and codes: https://ml-gsai.github.io/LLaDA-V-demo/.
Incentivizing Multimodal Reasoning in Large Models for Direct Robot Manipulation
May 19, 2025Recent Large Multimodal Models have demonstrated remarkable reasoning capabilities, especially in solving complex mathematical problems and realizing accurate spatial perception. Our key insight is that these emerging abilities can naturally extend to robotic manipulation by enabling LMMs to directly infer the next goal in language via reasoning, rather than relying on a separate action head. However, this paradigm meets two main challenges: i) How to make LMMs understand the spatial action space, and ii) How to fully exploit the reasoning capacity of LMMs in solving these tasks. To tackle the former challenge, we propose a novel task formulation, which inputs the current states of object parts and the gripper, and reformulates rotation by a new axis representation instead of traditional Euler angles. This representation is more compatible with spatial reasoning and easier to interpret within a unified language space. For the latter challenge, we design a pipeline to utilize cutting-edge LMMs to generate a small but high-quality reasoning dataset of multi-round dialogues that successfully solve manipulation tasks for supervised fine-tuning. Then, we perform reinforcement learning by trial-and-error interactions in simulation to further enhance the model's reasoning abilities for robotic manipulation. Our resulting reasoning model built upon a 7B backbone, named ReasonManip, demonstrates three notable advantages driven by its system-2 level reasoning capabilities: i) exceptional generalizability to out-of-distribution environments, objects, and tasks; ii) inherent sim-to-real transfer ability enabled by the unified language representation shared across domains; iii) transparent interpretability connecting high-level reasoning and low-level control. Extensive experiments demonstrate the effectiveness of the proposed paradigm and its potential to advance LMM-driven robotic manipulation.
CoTMR: Chain-of-Thought Multi-Scale Reasoning for Training-Free Zero-Shot Composed Image Retrieval
Feb 28, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve target images by integrating information from a composed query (reference image and modification text) without training samples. Existing methods primarily combine caption models and large language models (LLMs) to generate target captions based on composed queries but face various issues such as incompatibility, visual information loss, and insufficient reasoning. In this work, we propose CoTMR, a training-free framework crafted for ZS-CIR with novel Chain-of-thought (CoT) and Multi-scale Reasoning. Instead of relying on caption models for modality transformation, CoTMR employs the Large Vision-Language Model (LVLM) to achieve unified understanding and reasoning for composed queries. To enhance the reasoning reliability, we devise CIRCoT, which guides the LVLM through a step-by-step inference process using predefined subtasks. Considering that existing approaches focus solely on global-level reasoning, our CoTMR incorporates multi-scale reasoning to achieve more comprehensive inference via fine-grained predictions about the presence or absence of key elements at the object scale. Further, we design a Multi-Grained Scoring (MGS) mechanism, which integrates CLIP similarity scores of the above reasoning outputs with candidate images to realize precise retrieval. Extensive experiments demonstrate that our CoTMR not only drastically outperforms previous methods across four prominent benchmarks but also offers appealing interpretability.
Leveraging Large Vision-Language Model as User Intent-aware Encoder for Composed Image Retrieval
Dec 15, 2024Composed Image Retrieval (CIR) aims to retrieve target images from candidate set using a hybrid-modality query consisting of a reference image and a relative caption that describes the user intent. Recent studies attempt to utilize Vision-Language Pre-training Models (VLPMs) with various fusion strategies for addressing the task.However, these methods typically fail to simultaneously meet two key requirements of CIR: comprehensively extracting visual information and faithfully following the user intent. In this work, we propose CIR-LVLM, a novel framework that leverages the large vision-language model (LVLM) as the powerful user intent-aware encoder to better meet these requirements. Our motivation is to explore the advanced reasoning and instruction-following capabilities of LVLM for accurately understanding and responding the user intent. Furthermore, we design a novel hybrid intent instruction module to provide explicit intent guidance at two levels: (1) The task prompt clarifies the task requirement and assists the model in discerning user intent at the task level. (2) The instance-specific soft prompt, which is adaptively selected from the learnable prompt pool, enables the model to better comprehend the user intent at the instance level compared to a universal prompt for all instances. CIR-LVLM achieves state-of-the-art performance across three prominent benchmarks with acceptable inference efficiency. We believe this study provides fundamental insights into CIR-related fields.
Awaker2.5-VL: Stably Scaling MLLMs with Parameter-Efficient Mixture of Experts
Nov 16, 2024As the research of Multimodal Large Language Models (MLLMs) becomes popular, an advancing MLLM model is typically required to handle various textual and visual tasks (e.g., VQA, Detection, OCR, and ChartQA) simultaneously for real-world applications. However, due to the significant differences in representation and distribution among data from various tasks, simply mixing data of all tasks together leads to the well-known``multi-task conflict" issue, resulting in performance degradation across various tasks. To address this issue, we propose Awaker2.5-VL, a Mixture of Experts~(MoE) architecture suitable for MLLM, which acquires the multi-task capabilities through multiple sparsely activated experts. To speed up the training and inference of Awaker2.5-VL, each expert in our model is devised as a low-rank adaptation (LoRA) structure. Extensive experiments on multiple latest benchmarks demonstrate the effectiveness of Awaker2.5-VL. The code and model weight are released in our Project Page: https://github.com/MetabrainAGI/Awaker.
MMRole: A Comprehensive Framework for Developing and Evaluating Multimodal Role-Playing Agents
Aug 08, 2024



Recently, Role-Playing Agents (RPAs) have garnered increasing attention for their potential to deliver emotional value and facilitate sociological research. However, existing studies are primarily confined to the textual modality, unable to simulate humans' multimodal perceptual capabilities. To bridge this gap, we introduce the concept of Multimodal Role-Playing Agents (MRPAs), and propose a comprehensive framework, MMRole, for their development and evaluation, which comprises a personalized multimodal dataset and a robust evaluation method. Specifically, we construct a large-scale, high-quality dataset, MMRole-Data, consisting of 85 characters, 11K images, and 14K single or multi-turn dialogues. Additionally, we present a robust evaluation method, MMRole-Eval, encompassing eight metrics across three dimensions, where a reward model is trained to score MRPAs with the constructed ground-truth data for comparison. Moreover, we develop the first specialized MRPA, MMRole-Agent. Extensive evaluation results demonstrate the improved performance of MMRole-Agent and highlight the primary challenges in developing MRPAs, emphasizing the need for enhanced multimodal understanding and role-playing consistency. The data, code, and models will be available at https://github.com/YanqiDai/MMRole.
CoTBal: Comprehensive Task Balancing for Multi-Task Visual Instruction Tuning
Mar 07, 2024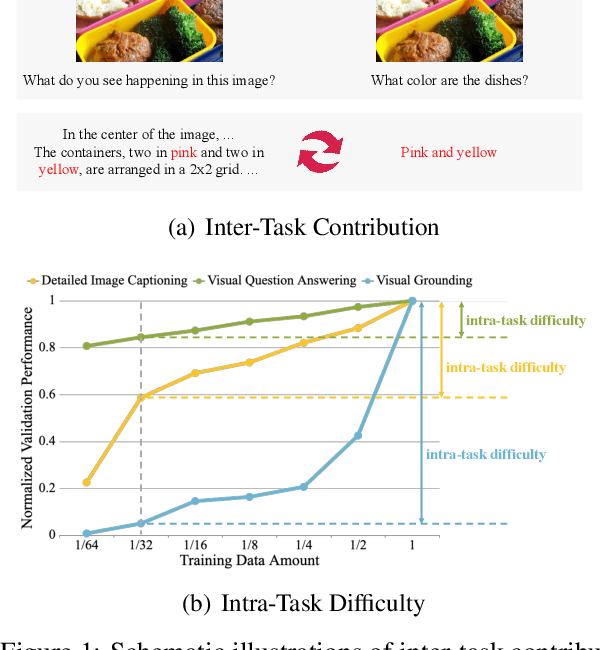



Visual instruction tuning is a key training stage of large multimodal models (LMMs). Nevertheless, the common practice of indiscriminately mixing instruction-following data from various tasks may result in suboptimal overall performance due to different instruction formats and knowledge domains across tasks. To mitigate this issue, we propose a novel Comprehensive Task Balancing (CoTBal) algorithm for multi-task visual instruction tuning of LMMs. To our knowledge, this is the first work that explores multi-task optimization in visual instruction tuning. Specifically, we consider two key dimensions for task balancing: (1) Inter-Task Contribution, the phenomenon where learning one task potentially enhances the performance in other tasks, attributable to the overlapping knowledge domains, and (2) Intra-Task Difficulty, which refers to the learning difficulty within a single task. By quantifying these two dimensions with performance-based metrics, task balancing is thus enabled by assigning more weights to tasks that offer substantial contributions to others, receive minimal contributions from others, and also have great intra-task difficulties. Experiments show that our CoTBal leads to superior overall performance in multi-task visual instruction tuning.
Improvable Gap Balancing for Multi-Task Learning
Jul 28, 2023In multi-task learning (MTL), gradient balancing has recently attracted more research interest than loss balancing since it often leads to better performance. However, loss balancing is much more efficient than gradient balancing, and thus it is still worth further exploration in MTL. Note that prior studies typically ignore that there exist varying improvable gaps across multiple tasks, where the improvable gap per task is defined as the distance between the current training progress and desired final training progress. Therefore, after loss balancing, the performance imbalance still arises in many cases. In this paper, following the loss balancing framework, we propose two novel improvable gap balancing (IGB) algorithms for MTL: one takes a simple heuristic, and the other (for the first time) deploys deep reinforcement learning for MTL. Particularly, instead of directly balancing the losses in MTL, both algorithms choose to dynamically assign task weights for improvable gap balancing. Moreover, we combine IGB and gradient balancing to show the complementarity between the two types of algorithms. Extensive experiments on two benchmark datasets demonstrate that our IGB algorithms lead to the best results in MTL via loss balancing and achieve further improvements when combined with gradient balancing. Code is available at https://github.com/YanqiDai/IGB4MTL.