 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwaker2.5-VL: Stably Scaling MLLMs with Parameter-Efficient Mixture of Experts
Nov 16, 2024As the research of Multimodal Large Language Models (MLLMs) becomes popular, an advancing MLLM model is typically required to handle various textual and visual tasks (e.g., VQA, Detection, OCR, and ChartQA) simultaneously for real-world applications. However, due to the significant differences in representation and distribution among data from various tasks, simply mixing data of all tasks together leads to the well-known``multi-task conflict" issue, resulting in performance degradation across various tasks. To address this issue, we propose Awaker2.5-VL, a Mixture of Experts~(MoE) architecture suitable for MLLM, which acquires the multi-task capabilities through multiple sparsely activated experts. To speed up the training and inference of Awaker2.5-VL, each expert in our model is devised as a low-rank adaptation (LoRA) structure. Extensive experiments on multiple latest benchmarks demonstrate the effectiveness of Awaker2.5-VL. The code and model weight are released in our Project Page: https://github.com/MetabrainAGI/Awaker.
How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs
Jan 23, 2024



Most traditional AI safety research has approached AI models as machines and centered on algorithm-focused attacks developed by security experts. As large language models (LLMs) become increasingly common and competent, non-expert users can also impose risks during daily interactions. This paper introduces a new perspective to jailbreak LLMs as human-like communicators, to explore this overlooked intersection between everyday language interaction and AI safety. Specifically, we study how to persuade LLMs to jailbreak them. First, we propose a persuasion taxonomy derived from decades of social science research. Then, we apply the taxonomy to automatically generate interpretable persuasive adversarial prompts (PAP) to jailbreak LLMs. Results show that persuasion significantly increases the jailbreak performance across all risk categories: PAP consistently achieves an attack success rate of over $92\%$ on Llama 2-7b Chat, GPT-3.5, and GPT-4 in $10$ trials, surpassing recent algorithm-focused attacks. On the defense side, we explore various mechanisms against PAP and, found a significant gap in existing defenses, and advocate for more fundamental mitigation for highly interactive LLMs
TikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat
Jan 14, 2023
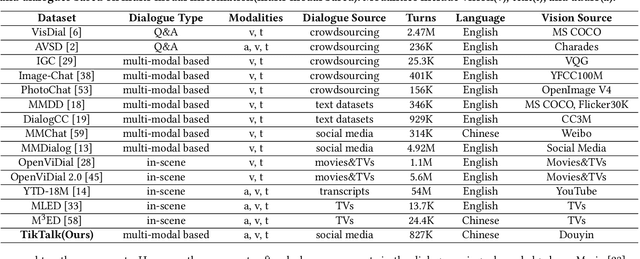

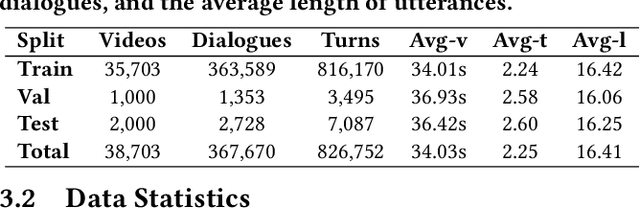
We present a novel multi-modal chitchat dialogue dataset-TikTalk aimed at facilitating the research of intelligent chatbots. It consists of the videos and corresponding dialogues users generate on video social applications. In contrast to existing multi-modal dialogue datasets, we construct dialogue corpora based on video comment-reply pairs, which is more similar to chitchat in real-world dialogue scenarios. Our dialogue context includes three modalities: text, vision, and audio. Compared with previous image-based dialogue datasets, the richer sources of context in TikTalk lead to a greater diversity of conversations. TikTalk contains over 38K videos and 367K dialogues. Data analysis shows that responses in TikTalk are in correlation with various contexts and external knowledge. It poses a great challenge for the deep understanding of multi-modal information and the generation of responses. We evaluate several baselines on three types of automatic metrics and conduct case studies. Experimental results demonstrate that there is still a large room for future improvement on TikTalk. Our dataset is available at \url{https://github.com/RUC-AIMind/TikTalk}.