 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Vision-Language Model as User Intent-aware Encoder for Composed Image Retrieval
Dec 15, 2024Composed Image Retrieval (CIR) aims to retrieve target images from candidate set using a hybrid-modality query consisting of a reference image and a relative caption that describes the user intent. Recent studies attempt to utilize Vision-Language Pre-training Models (VLPMs) with various fusion strategies for addressing the task.However, these methods typically fail to simultaneously meet two key requirements of CIR: comprehensively extracting visual information and faithfully following the user intent. In this work, we propose CIR-LVLM, a novel framework that leverages the large vision-language model (LVLM) as the powerful user intent-aware encoder to better meet these requirements. Our motivation is to explore the advanced reasoning and instruction-following capabilities of LVLM for accurately understanding and responding the user intent. Furthermore, we design a novel hybrid intent instruction module to provide explicit intent guidance at two levels: (1) The task prompt clarifies the task requirement and assists the model in discerning user intent at the task level. (2) The instance-specific soft prompt, which is adaptively selected from the learnable prompt pool, enables the model to better comprehend the user intent at the instance level compared to a universal prompt for all instances. CIR-LVLM achieves state-of-the-art performance across three prominent benchmarks with acceptable inference efficiency. We believe this study provides fundamental insights into CIR-related fields.
Awaker2.5-VL: Stably Scaling MLLMs with Parameter-Efficient Mixture of Experts
Nov 16, 2024As the research of Multimodal Large Language Models (MLLMs) becomes popular, an advancing MLLM model is typically required to handle various textual and visual tasks (e.g., VQA, Detection, OCR, and ChartQA) simultaneously for real-world applications. However, due to the significant differences in representation and distribution among data from various tasks, simply mixing data of all tasks together leads to the well-known``multi-task conflict" issue, resulting in performance degradation across various tasks. To address this issue, we propose Awaker2.5-VL, a Mixture of Experts~(MoE) architecture suitable for MLLM, which acquires the multi-task capabilities through multiple sparsely activated experts. To speed up the training and inference of Awaker2.5-VL, each expert in our model is devised as a low-rank adaptation (LoRA) structure. Extensive experiments on multiple latest benchmarks demonstrate the effectiveness of Awaker2.5-VL. The code and model weight are released in our Project Page: https://github.com/MetabrainAGI/Awaker.
CoTBal: Comprehensive Task Balancing for Multi-Task Visual Instruction Tuning
Mar 07, 2024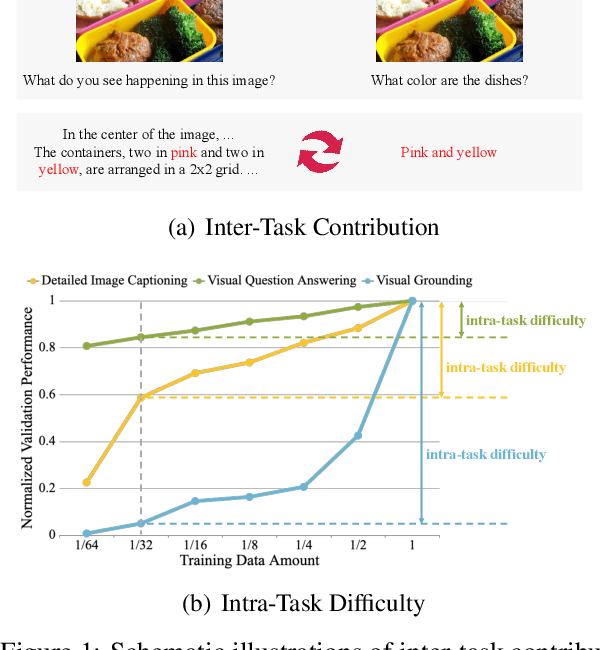



Visual instruction tuning is a key training stage of large multimodal models (LMMs). Nevertheless, the common practice of indiscriminately mixing instruction-following data from various tasks may result in suboptimal overall performance due to different instruction formats and knowledge domains across tasks. To mitigate this issue, we propose a novel Comprehensive Task Balancing (CoTBal) algorithm for multi-task visual instruction tuning of LMMs. To our knowledge, this is the first work that explores multi-task optimization in visual instruction tuning. Specifically, we consider two key dimensions for task balancing: (1) Inter-Task Contribution, the phenomenon where learning one task potentially enhances the performance in other tasks, attributable to the overlapping knowledge domains, and (2) Intra-Task Difficulty, which refers to the learning difficulty within a single task. By quantifying these two dimensions with performance-based metrics, task balancing is thus enabled by assigning more weights to tasks that offer substantial contributions to others, receive minimal contributions from others, and also have great intra-task difficulties. Experiments show that our CoTBal leads to superior overall performance in multi-task visual instruction tuning.
Improvable Gap Balancing for Multi-Task Learning
Jul 28, 2023In multi-task learning (MTL), gradient balancing has recently attracted more research interest than loss balancing since it often leads to better performance. However, loss balancing is much more efficient than gradient balancing, and thus it is still worth further exploration in MTL. Note that prior studies typically ignore that there exist varying improvable gaps across multiple tasks, where the improvable gap per task is defined as the distance between the current training progress and desired final training progress. Therefore, after loss balancing, the performance imbalance still arises in many cases. In this paper, following the loss balancing framework, we propose two novel improvable gap balancing (IGB) algorithms for MTL: one takes a simple heuristic, and the other (for the first time) deploys deep reinforcement learning for MTL. Particularly, instead of directly balancing the losses in MTL, both algorithms choose to dynamically assign task weights for improvable gap balancing. Moreover, we combine IGB and gradient balancing to show the complementarity between the two types of algorithms. Extensive experiments on two benchmark datasets demonstrate that our IGB algorithms lead to the best results in MTL via loss balancing and achieve further improvements when combined with gradient balancing. Code is available at https://github.com/YanqiDai/IGB4MTL.
VDT: An Empirical Study on Video Diffusion with Transformers
May 22, 2023This work introduces Video Diffusion Transformer (VDT), which pioneers the use of transformers in diffusion-based video generation. It features transformer blocks with modularized temporal and spatial attention modules, allowing separate optimization of each component and leveraging the rich spatial-temporal representation inherited from transformers. VDT offers several appealing benefits. 1) It excels at capturing temporal dependencies to produce temporally consistent video frames and even simulate the dynamics of 3D objects over time. 2) It enables flexible conditioning information through simple concatenation in the token space, effectively unifying video generation and prediction tasks. 3) Its modularized design facilitates a spatial-temporal decoupled training strategy, leading to improved efficiency. Extensive experiments on video generation, prediction, and dynamics modeling (i.e., physics-based QA) tasks have been conducted to demonstrate the effectiveness of VDT in various scenarios, including autonomous driving, human action, and physics-based simulation. We hope our study on the capabilities of transformer-based video diffusion in capturing accurate temporal dependencies, handling conditioning information, and achieving efficient training will benefit future research and advance the field. Codes and models are available at https://github.com/RERV/VDT.
LGDN: Language-Guided Denoising Network for Video-Language Modeling
Oct 03, 2022
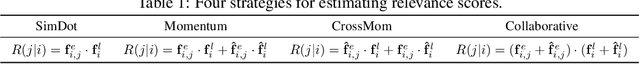
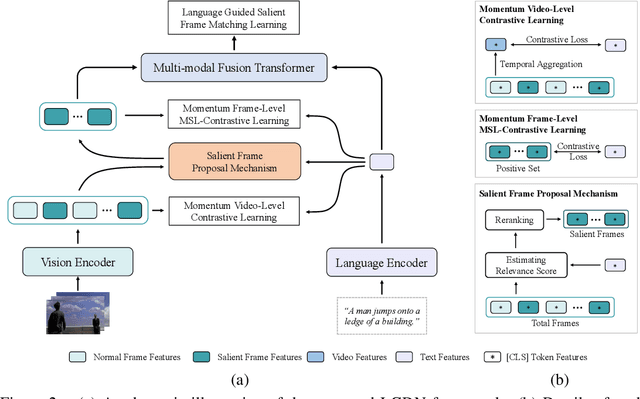
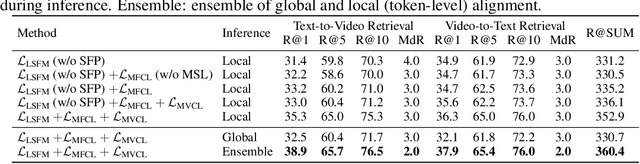
Video-language modeling has attracted much attention with the rapid growth of web videos. Most existing methods assume that the video frames and text description are semantically correlated, and focus on video-language modeling at video level. However, this hypothesis often fails for two reasons: (1) With the rich semantics of video contents, it is difficult to cover all frames with a single video-level description; (2) A raw video typically has noisy/meaningless information (e.g., scenery shot, transition or teaser). Although a number of recent works deploy attention mechanism to alleviate this problem, the irrelevant/noisy information still makes it very difficult to address. To overcome such challenge, we thus propose an efficient and effective model, termed Language-Guided Denoising Network (LGDN), for video-language modeling. Different from most existing methods that utilize all extracted video frames, LGDN dynamically filters out the misaligned or redundant frames under the language supervision and obtains only 2--4 salient frames per video for cross-modal token-level alignment. Extensive experiments on five public datasets show that our LGDN outperforms the state-of-the-arts by large margins. We also provide detailed ablation study to reveal the critical importance of solving the noise issue, in hope of inspiring future video-language work.
Multimodal foundation models are better simulators of the human brain
Aug 17, 2022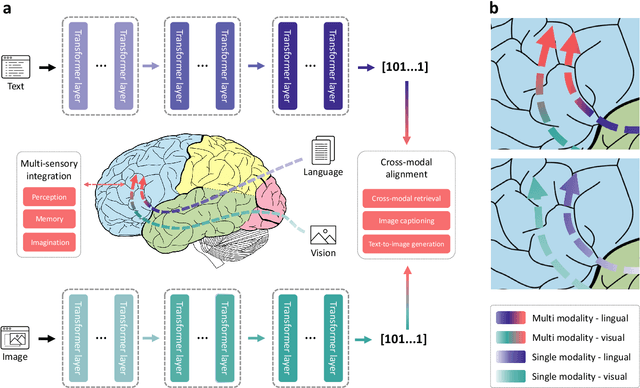
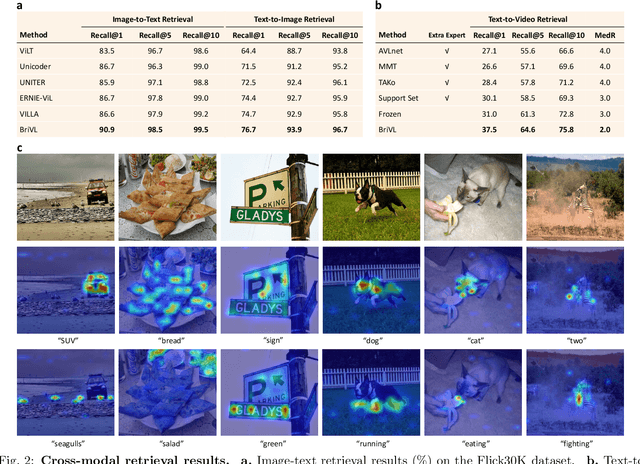

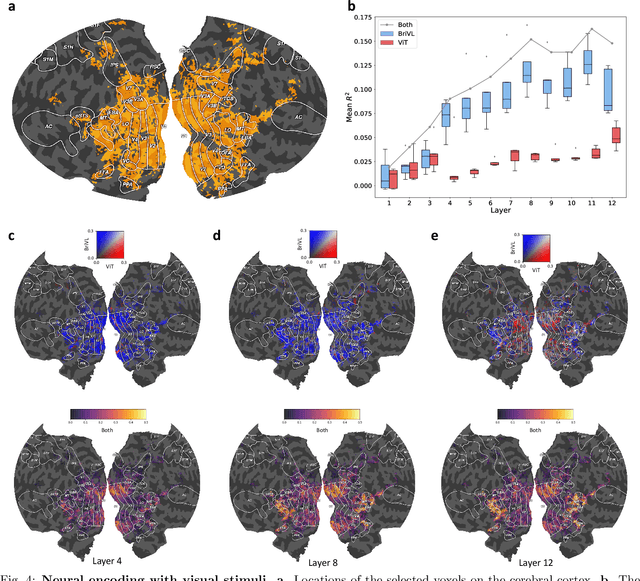
Multimodal learning, especially large-scale multimodal pre-training, has developed rapidly over the past few years and led to the greatest advances in artificial intelligence (AI). Despite its effectiveness, understanding the underlying mechanism of multimodal pre-training models still remains a grand challenge. Revealing the explainability of such models is likely to enable breakthroughs of novel learning paradigms in the AI field. To this end, given the multimodal nature of the human brain, we propose to explore the explainability of multimodal learning models with the aid of non-invasive brain imaging technologies such as functional magnetic resonance imaging (fMRI). Concretely, we first present a newly-designed multimodal foundation model pre-trained on 15 million image-text pairs, which has shown strong multimodal understanding and generalization abilities in a variety of cognitive downstream tasks. Further, from the perspective of neural encoding (based on our foundation model), we find that both visual and lingual encoders trained multimodally are more brain-like compared with unimodal ones. Particularly, we identify a number of brain regions where multimodally-trained encoders demonstrate better neural encoding performance. This is consistent with the findings in existing studies on exploring brain multi-sensory integration. Therefore, we believe that multimodal foundation models are more suitable tools for neuroscientists to study the multimodal signal processing mechanisms in the human brain. Our findings also demonstrate the potential of multimodal foundation models as ideal computational simulators to promote both AI-for-brain and brain-for-AI research.
COTS: Collaborative Two-Stream Vision-Language Pre-Training Model for Cross-Modal Retrieval
Apr 15, 2022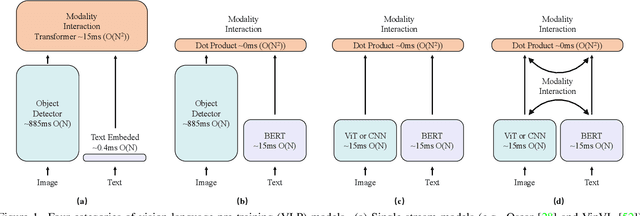
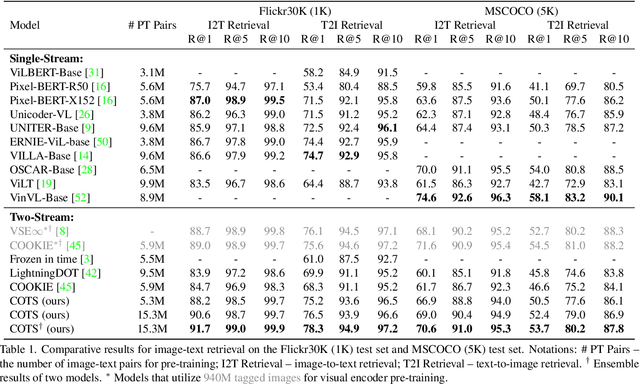
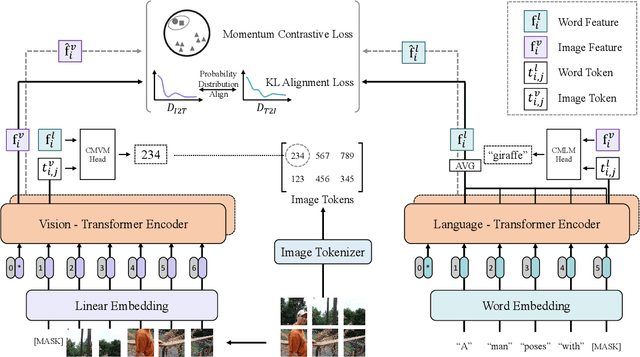
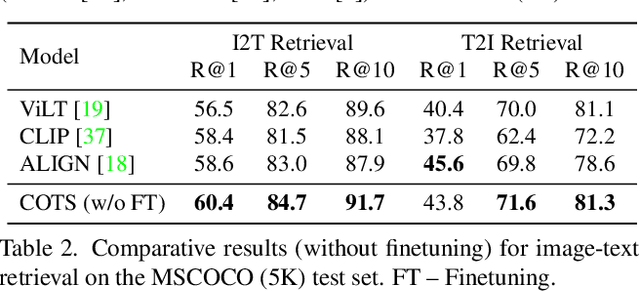
Large-scale single-stream pre-training has shown dramatic performance in image-text retrieval. Regrettably, it faces low inference efficiency due to heavy attention layers. Recently, two-stream methods like CLIP and ALIGN with high inference efficiency have also shown promising performance, however, they only consider instance-level alignment between the two streams (thus there is still room for improvement). To overcome these limitations, we propose a novel COllaborative Two-Stream vision-language pretraining model termed COTS for image-text retrieval by enhancing cross-modal interaction. In addition to instance level alignment via momentum contrastive learning, we leverage two extra levels of cross-modal interactions in our COTS: (1) Token-level interaction - a masked visionlanguage modeling (MVLM) learning objective is devised without using a cross-stream network module, where variational autoencoder is imposed on the visual encoder to generate visual tokens for each image. (2) Task-level interaction - a KL-alignment learning objective is devised between text-to-image and image-to-text retrieval tasks, where the probability distribution per task is computed with the negative queues in momentum contrastive learning. Under a fair comparison setting, our COTS achieves the highest performance among all two-stream methods and comparable performance (but with 10,800X faster in inference) w.r.t. the latest single-stream methods. Importantly, our COTS is also applicable to text-to-video retrieval, yielding new state-ofthe-art on the widely-used MSR-VTT dataset.
A Roadmap for Big Model
Apr 02, 2022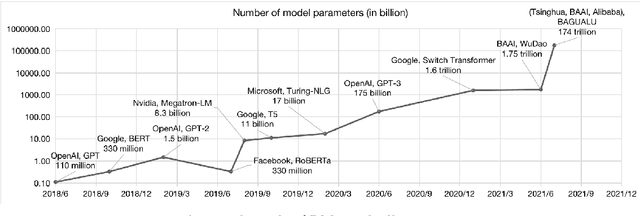
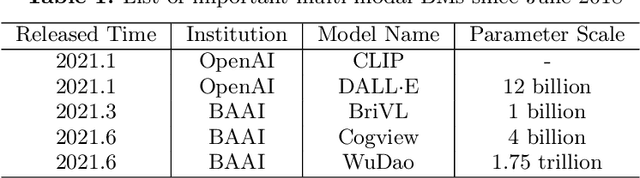
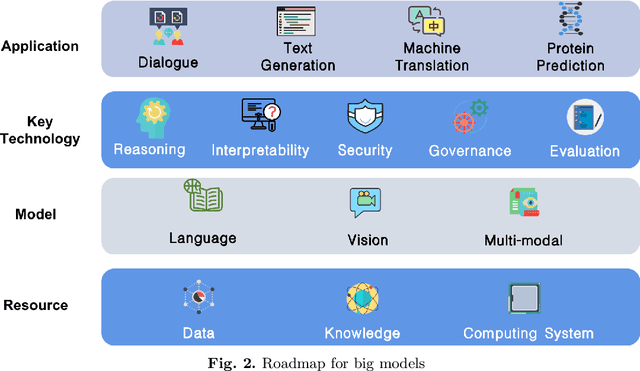
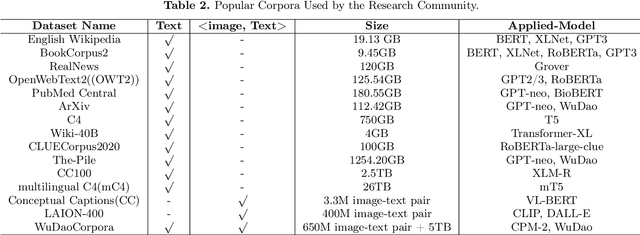
With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model
Oct 27, 2021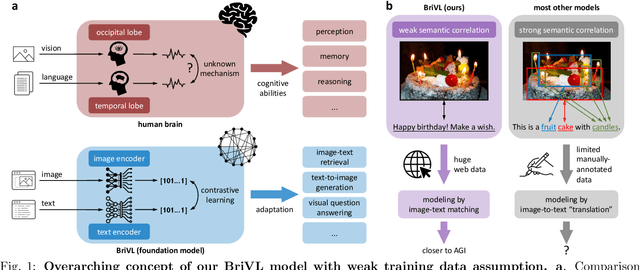


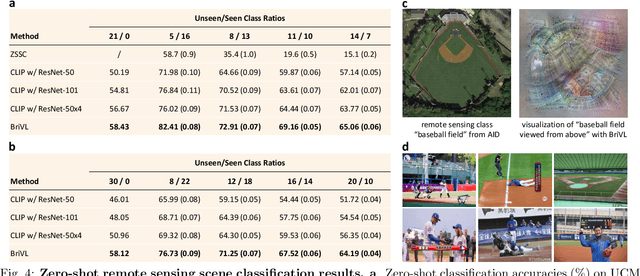
The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception, memory, and reasoning. Although tremendous success has been achieved in various AI research fields (e.g., computer vision and natural language processing), the majority of existing works only focus on acquiring single cognitive ability (e.g., image classification, reading comprehension, or visual commonsense reasoning). To overcome this limitation and take a solid step to artificial general intelligence (AGI), we develop a novel foundation model pre-trained with huge multimodal (visual and textual) data, which is able to be quickly adapted for a broad class of downstream cognitive tasks. Such a model is fundamentally different from the multimodal foundation models recently proposed in the literature that typically make strong semantic correlation assumption and expect exact alignment between image and text modalities in their pre-training data, which is often hard to satisfy in practice thus limiting their generalization abilities. To resolve this issue, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that state-of-the-art results can be obtained on a wide range of downstream tasks (both single-modal and cross-modal). Particularly, with novel model-interpretability tools developed in this work, we demonstrate that strong imagination ability (even with hints of commonsense) is now possessed by our foundation model. We believe our work makes a transformative stride towards AGI and will have broad impact on various AI+ fields (e.g., neuroscience and healthcare).