 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-MUSED: CLIP-Guided Multi-Subject Visual Neural Information Semantic Decoding
Feb 14, 2024


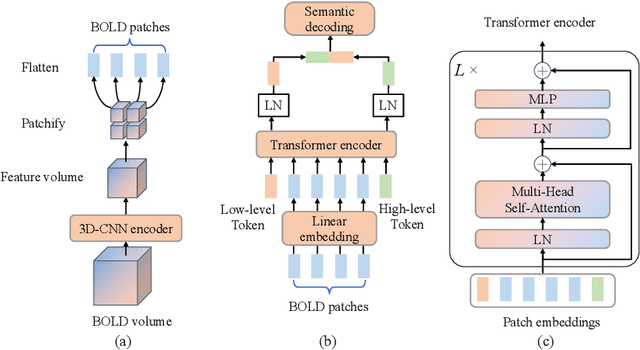
The study of decoding visual neural information faces challenges in generalizing single-subject decoding models to multiple subjects, due to individual differences. Moreover, the limited availability of data from a single subject has a constraining impact on model performance. Although prior multi-subject decoding methods have made significant progress, they still suffer from several limitations, including difficulty in extracting global neural response features, linear scaling of model parameters with the number of subjects, and inadequate characterization of the relationship between neural responses of different subjects to various stimuli. To overcome these limitations, we propose a CLIP-guided Multi-sUbject visual neural information SEmantic Decoding (CLIP-MUSED) method. Our method consists of a Transformer-based feature extractor to effectively model global neural representations. It also incorporates learnable subject-specific tokens that facilitates the aggregation of multi-subject data without a linear increase of parameters. Additionally, we employ representational similarity analysis (RSA) to guide token representation learning based on the topological relationship of visual stimuli in the representation space of CLIP, enabling full characterization of the relationship between neural responses of different subjects under different stimuli. Finally, token representations are used for multi-subject semantic decoding. Our proposed method outperforms single-subject decoding methods and achieves state-of-the-art performance among the existing multi-subject methods on two fMRI datasets. Visualization results provide insights into the effectiveness of our proposed method. Code is available at https://github.com/CLIP-MUSED/CLIP-MUSED.
Auditory Attention Decoding with Task-Related Multi-View Contrastive Learning
Aug 08, 2023The human brain can easily focus on one speaker and suppress others in scenarios such as a cocktail party. Recently, researchers found that auditory attention can be decoded from the electroencephalogram (EEG) data. However, most existing deep learning methods are difficult to use prior knowledge of different views (that is attended speech and EEG are task-related views) and extract an unsatisfactory representation. Inspired by Broadbent's filter model, we decode auditory attention in a multi-view paradigm and extract the most relevant and important information utilizing the missing view. Specifically, we propose an auditory attention decoding (AAD) method based on multi-view VAE with task-related multi-view contrastive (TMC) learning. Employing TMC learning in multi-view VAE can utilize the missing view to accumulate prior knowledge of different views into the fusion of representation, and extract the approximate task-related representation. We examine our method on two popular AAD datasets, and demonstrate the superiority of our method by comparing it to the state-of-the-art method.
Multimodal foundation models are better simulators of the human brain
Aug 17, 2022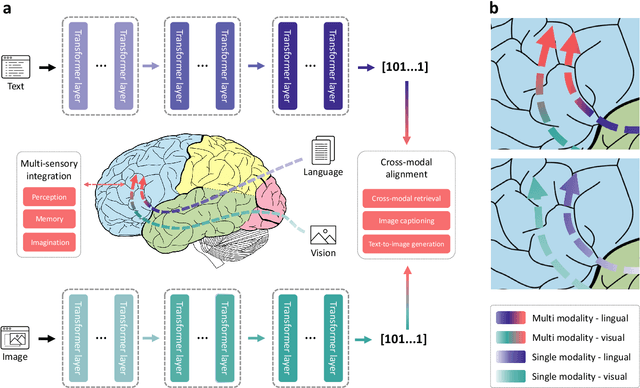
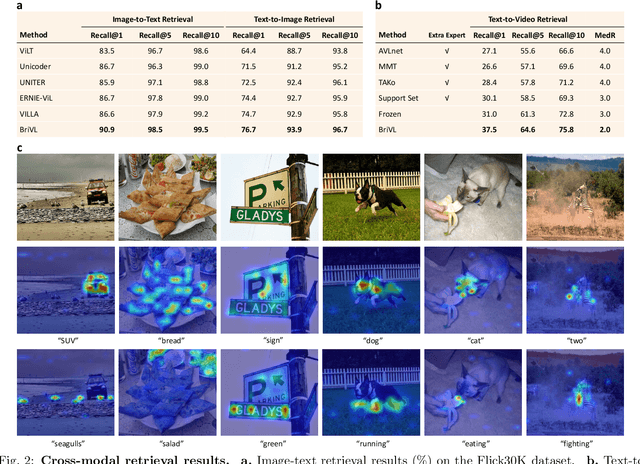

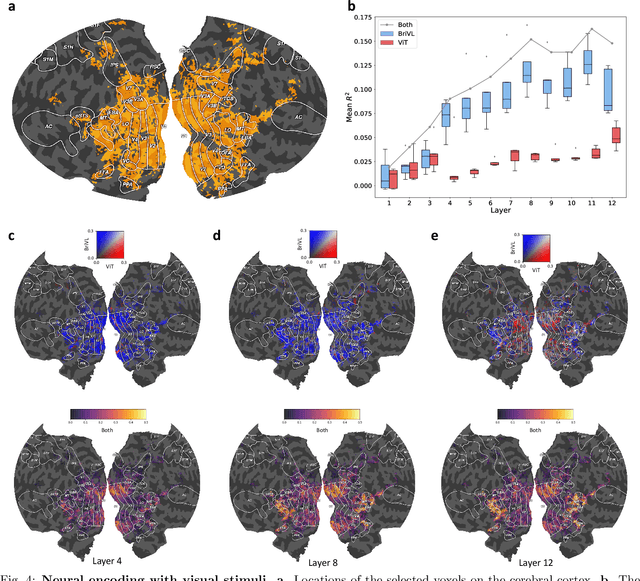
Multimodal learning, especially large-scale multimodal pre-training, has developed rapidly over the past few years and led to the greatest advances in artificial intelligence (AI). Despite its effectiveness, understanding the underlying mechanism of multimodal pre-training models still remains a grand challenge. Revealing the explainability of such models is likely to enable breakthroughs of novel learning paradigms in the AI field. To this end, given the multimodal nature of the human brain, we propose to explore the explainability of multimodal learning models with the aid of non-invasive brain imaging technologies such as functional magnetic resonance imaging (fMRI). Concretely, we first present a newly-designed multimodal foundation model pre-trained on 15 million image-text pairs, which has shown strong multimodal understanding and generalization abilities in a variety of cognitive downstream tasks. Further, from the perspective of neural encoding (based on our foundation model), we find that both visual and lingual encoders trained multimodally are more brain-like compared with unimodal ones. Particularly, we identify a number of brain regions where multimodally-trained encoders demonstrate better neural encoding performance. This is consistent with the findings in existing studies on exploring brain multi-sensory integration. Therefore, we believe that multimodal foundation models are more suitable tools for neuroscientists to study the multimodal signal processing mechanisms in the human brain. Our findings also demonstrate the potential of multimodal foundation models as ideal computational simulators to promote both AI-for-brain and brain-for-AI research.