 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-MUSED: CLIP-Guided Multi-Subject Visual Neural Information Semantic Decoding
Paper and Code



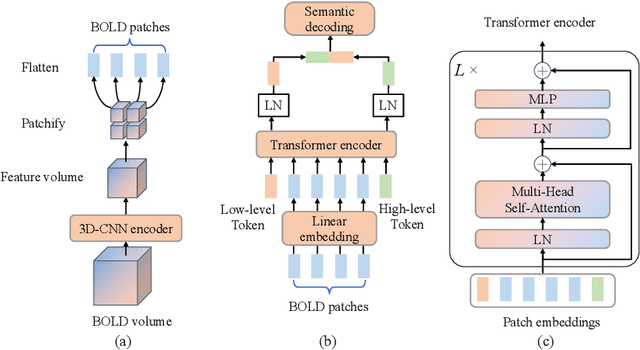
The study of decoding visual neural information faces challenges in generalizing single-subject decoding models to multiple subjects, due to individual differences. Moreover, the limited availability of data from a single subject has a constraining impact on model performance. Although prior multi-subject decoding methods have made significant progress, they still suffer from several limitations, including difficulty in extracting global neural response features, linear scaling of model parameters with the number of subjects, and inadequate characterization of the relationship between neural responses of different subjects to various stimuli. To overcome these limitations, we propose a CLIP-guided Multi-sUbject visual neural information SEmantic Decoding (CLIP-MUSED) method. Our method consists of a Transformer-based feature extractor to effectively model global neural representations. It also incorporates learnable subject-specific tokens that facilitates the aggregation of multi-subject data without a linear increase of parameters. Additionally, we employ representational similarity analysis (RSA) to guide token representation learning based on the topological relationship of visual stimuli in the representation space of CLIP, enabling full characterization of the relationship between neural responses of different subjects under different stimuli. Finally, token representations are used for multi-subject semantic decoding. Our proposed method outperforms single-subject decoding methods and achieves state-of-the-art performance among the existing multi-subject methods on two fMRI datasets. Visualization results provide insights into the effectiveness of our proposed method. Code is available at https://github.com/CLIP-MUSED/CLIP-MUSED.