 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBP-GPT: Auditory Neural Decoding Using fMRI-prompted LLM
Feb 21, 2025Decoding language information from brain signals represents a vital research area within brain-computer interfaces, particularly in the context of deciphering the semantic information from the fMRI signal. Although existing work uses LLM to achieve this goal, their method does not use an end-to-end approach and avoids the LLM in the mapping of fMRI-to-text, leaving space for the exploration of the LLM in auditory decoding. In this paper, we introduce a novel method, the Brain Prompt GPT (BP-GPT). By using the brain representation that is extracted from the fMRI as a prompt, our method can utilize GPT-2 to decode fMRI signals into stimulus text. Further, we introduce the text prompt and align the fMRI prompt to it. By introducing the text prompt, our BP-GPT can extract a more robust brain prompt and promote the decoding of pre-trained LLM. We evaluate our BP-GPT on the open-source auditory semantic decoding dataset and achieve a significant improvement up to 4.61 on METEOR and 2.43 on BERTScore across all the subjects compared to the state-of-the-art method. The experimental results demonstrate that using brain representation as a prompt to further drive LLM for auditory neural decoding is feasible and effective. The code is available at https://github.com/1994cxy/BP-GPT.
Integrating Language-Image Prior into EEG Decoding for Cross-Task Zero-Calibration RSVP-BCI
Jan 06, 2025



Rapid Serial Visual Presentation (RSVP)-based Brain-Computer Interface (BCI) is an effective technology used for information detection by detecting Event-Related Potentials (ERPs). The current RSVP decoding methods can perform well in decoding EEG signals within a single RSVP task, but their decoding performance significantly decreases when directly applied to different RSVP tasks without calibration data from the new tasks. This limits the rapid and efficient deployment of RSVP-BCI systems for detecting different categories of targets in various scenarios. To overcome this limitation, this study aims to enhance the cross-task zero-calibration RSVP decoding performance. First, we design three distinct RSVP tasks for target image retrieval and build an open-source dataset containing EEG signals and corresponding stimulus images. Then we propose an EEG with Language-Image Prior fusion Transformer (ELIPformer) for cross-task zero-calibration RSVP decoding. Specifically, we propose a prompt encoder based on the language-image pre-trained model to extract language-image features from task-specific prompts and stimulus images as prior knowledge for enhancing EEG decoding. A cross bidirectional attention mechanism is also adopted to facilitate the effective feature fusion and alignment between the EEG and language-image features. Extensive experiments demonstrate that the proposed model achieves superior performance in cross-task zero-calibration RSVP decoding, which promotes the RSVP-BCI system from research to practical application.
NeuralOOD: Improving Out-of-Distribution Generalization Performance with Brain-machine Fusion Learning Framework
Aug 27, 2024



Deep Neural Networks (DNNs) have demonstrated exceptional recognition capabilities in traditional computer vision (CV) tasks. However, existing CV models often suffer a significant decrease in accuracy when confronted with out-of-distribution (OOD) data. In contrast to these DNN models, human can maintain a consistently low error rate when facing OOD scenes, partly attributed to the rich prior cognitive knowledge stored in the human brain. Previous OOD generalization researches only focus on the single modal, overlooking the advantages of multimodal learning method. In this paper, we utilize the multimodal learning method to improve the OOD generalization and propose a novel Brain-machine Fusion Learning (BMFL) framework. We adopt the cross-attention mechanism to fuse the visual knowledge from CV model and prior cognitive knowledge from the human brain. Specially, we employ a pre-trained visual neural encoding model to predict the functional Magnetic Resonance Imaging (fMRI) from visual features which eliminates the need for the fMRI data collection and pre-processing, effectively reduces the workload associated with conventional BMFL methods. Furthermore, we construct a brain transformer to facilitate the extraction of knowledge inside the fMRI data. Moreover, we introduce the Pearson correlation coefficient maximization regularization method into the training process, which improves the fusion capability with better constrains. Our model outperforms the DINOv2 and baseline models on the ImageNet-1k validation dataset as well as six curated OOD datasets, showcasing its superior performance in diverse scenarios.
Identifying the Hierarchical Emotional Areas in the Human Brain Through Information Fusion
Aug 01, 2024



The brain basis of emotion has consistently received widespread attention, attracting a large number of studies to explore this cutting-edge topic. However, the methods employed in these studies typically only model the pairwise relationship between two brain regions, while neglecting the interactions and information fusion among multiple brain regions$\unicode{x2014}$one of the key ideas of the psychological constructionist hypothesis. To overcome the limitations of traditional methods, this study provides an in-depth theoretical analysis of how to maximize interactions and information fusion among brain regions. Building on the results of this analysis, we propose to identify the hierarchical emotional areas in the human brain through multi-source information fusion and graph machine learning methods. Comprehensive experiments reveal that the identified hierarchical emotional areas, from lower to higher levels, primarily facilitate the fundamental process of emotion perception, the construction of basic psychological operations, and the coordination and integration of these operations. Overall, our findings provide unique insights into the brain mechanisms underlying specific emotions based on the psychological constructionist hypothesis.
Human-like object concept representations emerge naturally in multimodal large language models
Jul 01, 2024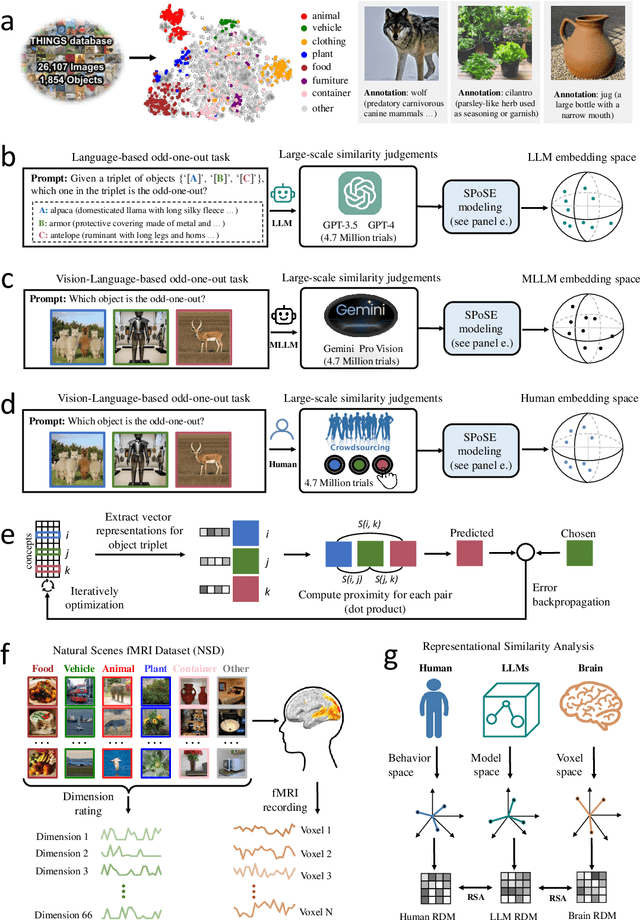
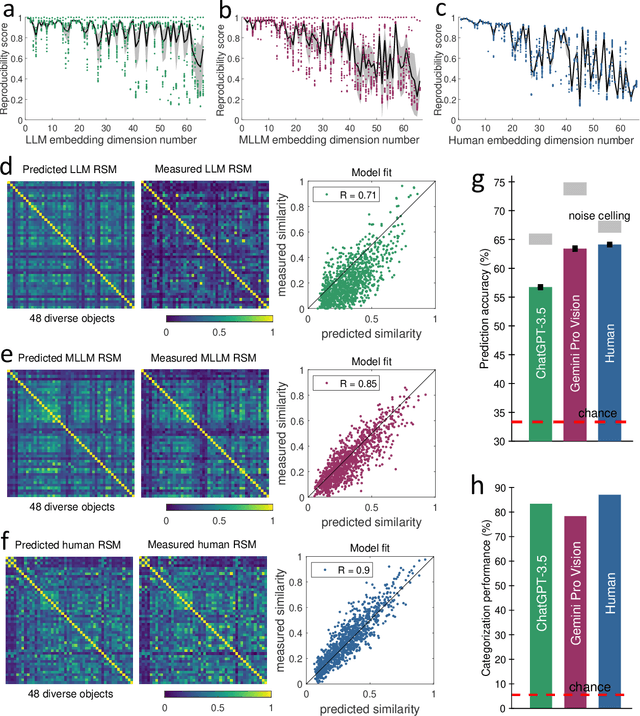

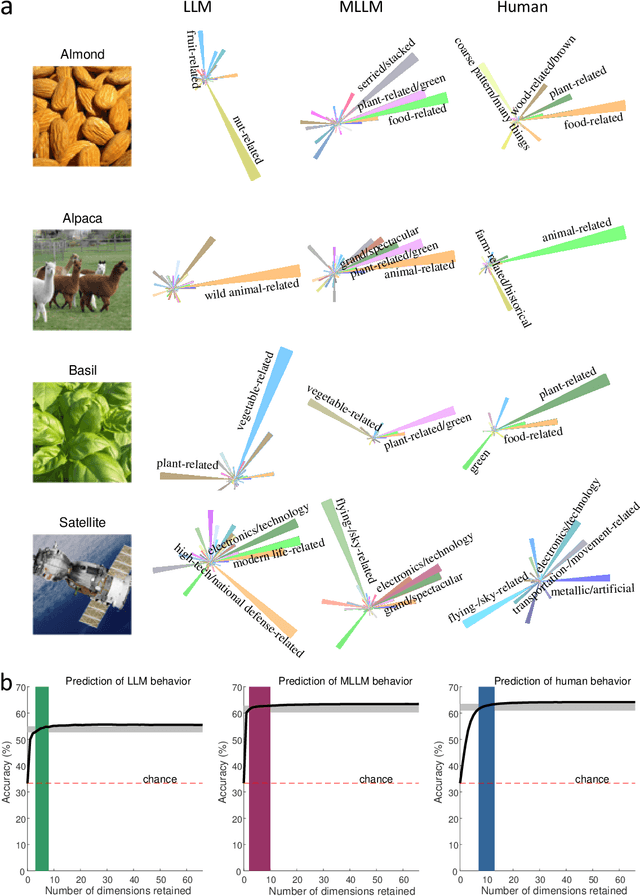
The conceptualization and categorization of natural objects in the human mind have long intrigued cognitive scientists and neuroscientists, offering crucial insights into human perception and cognition. Recently, the rapid development of Large Language Models (LLMs) has raised the attractive question of whether these models can also develop human-like object representations through exposure to vast amounts of linguistic and multimodal data. In this study, we combined behavioral and neuroimaging analysis methods to uncover how the object concept representations in LLMs correlate with those of humans. By collecting large-scale datasets of 4.7 million triplet judgments from LLM and Multimodal LLM (MLLM), we were able to derive low-dimensional embeddings that capture the underlying similarity structure of 1,854 natural objects. The resulting 66-dimensional embeddings were found to be highly stable and predictive, and exhibited semantic clustering akin to human mental representations. Interestingly, the interpretability of the dimensions underlying these embeddings suggests that LLM and MLLM have developed human-like conceptual representations of natural objects. Further analysis demonstrated strong alignment between the identified model embeddings and neural activity patterns in many functionally defined brain ROIs (e.g., EBA, PPA, RSC and FFA). This provides compelling evidence that the object representations in LLMs, while not identical to those in the human, share fundamental commonalities that reflect key schemas of human conceptual knowledge. This study advances our understanding of machine intelligence and informs the development of more human-like artificial cognitive systems.
Multi-label Class Incremental Emotion Decoding with Augmented Emotional Semantics Learning
May 31, 2024



Emotion decoding plays an important role in affective human-computer interaction. However, previous studies ignored the dynamic real-world scenario, where human experience a blend of multiple emotions which are incrementally integrated into the model, leading to the multi-label class incremental learning (MLCIL) problem. Existing methods have difficulty in solving MLCIL issue due to notorious catastrophic forgetting caused by partial label problem and inadequate label semantics mining. In this paper, we propose an augmented emotional semantics learning framework for multi-label class incremental emotion decoding. Specifically, we design an augmented emotional relation graph module with label disambiguation to handle the past-missing partial label problem. Then, we leverage domain knowledge from affective dimension space to alleviate future-missing partial label problem by knowledge distillation. Besides, an emotional semantics learning module is constructed with a graph autoencoder to obtain emotion embeddings in order to guide the semantic-specific feature decoupling for better multi-label learning. Extensive experiments on three datasets show the superiority of our method for improving emotion decoding performance and mitigating forgetting on MLCIL problem.
Reverse the auditory processing pathway: Coarse-to-fine audio reconstruction from fMRI
May 29, 2024



Drawing inspiration from the hierarchical processing of the human auditory system, which transforms sound from low-level acoustic features to high-level semantic understanding, we introduce a novel coarse-to-fine audio reconstruction method. Leveraging non-invasive functional Magnetic Resonance Imaging (fMRI) data, our approach mimics the inverse pathway of auditory processing. Initially, we utilize CLAP to decode fMRI data coarsely into a low-dimensional semantic space, followed by a fine-grained decoding into the high-dimensional AudioMAE latent space guided by semantic features. These fine-grained neural features serve as conditions for audio reconstruction through a Latent Diffusion Model (LDM). Validation on three public fMRI datasets-Brain2Sound, Brain2Music, and Brain2Speech-underscores the superiority of our coarse-to-fine decoding method over stand-alone fine-grained approaches, showcasing state-of-the-art performance in metrics like FD, FAD, and KL. Moreover, by employing semantic prompts during decoding, we enhance the quality of reconstructed audio when semantic features are suboptimal. The demonstrated versatility of our model across diverse stimuli highlights its potential as a universal brain-to-audio framework. This research contributes to the comprehension of the human auditory system, pushing boundaries in neural decoding and audio reconstruction methodologies.
Open-vocabulary Auditory Neural Decoding Using fMRI-prompted LLM
May 13, 2024
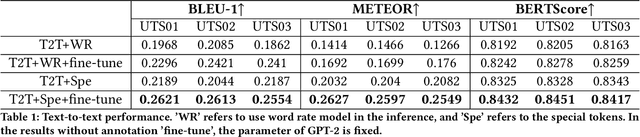


Decoding language information from brain signals represents a vital research area within brain-computer interfaces, particularly in the context of deciphering the semantic information from the fMRI signal. However, many existing efforts concentrate on decoding small vocabulary sets, leaving space for the exploration of open vocabulary continuous text decoding. In this paper, we introduce a novel method, the \textbf{Brain Prompt GPT (BP-GPT)}. By using the brain representation that is extracted from the fMRI as a prompt, our method can utilize GPT-2 to decode fMRI signals into stimulus text. Further, we introduce a text-to-text baseline and align the fMRI prompt to the text prompt. By introducing the text-to-text baseline, our BP-GPT can extract a more robust brain prompt and promote the decoding of pre-trained LLM. We evaluate our BP-GPT on the open-source auditory semantic decoding dataset and achieve a significant improvement up to $4.61\%$ on METEOR and $2.43\%$ on BERTScore across all the subjects compared to the state-of-the-art method. The experimental results demonstrate that using brain representation as a prompt to further drive LLM for auditory neural decoding is feasible and effective.
Animate Your Thoughts: Decoupled Reconstruction of Dynamic Natural Vision from Slow Brain Activity
May 06, 2024Reconstructing human dynamic vision from brain activity is a challenging task with great scientific significance. The difficulty stems from two primary issues: (1) vision-processing mechanisms in the brain are highly intricate and not fully revealed, making it challenging to directly learn a mapping between fMRI and video; (2) the temporal resolution of fMRI is significantly lower than that of natural videos. To overcome these issues, this paper propose a two-stage model named Mind-Animator, which achieves state-of-the-art performance on three public datasets. Specifically, during the fMRI-to-feature stage, we decouple semantic, structural, and motion features from fMRI through fMRI-vision-language tri-modal contrastive learning and sparse causal attention. In the feature-to-video stage, these features are merged to videos by an inflated Stable Diffusion. We substantiate that the reconstructed video dynamics are indeed derived from fMRI, rather than hallucinations of the generative model, through permutation tests. Additionally, the visualization of voxel-wise and ROI-wise importance maps confirms the neurobiological interpretability of our model.
CLIP-MUSED: CLIP-Guided Multi-Subject Visual Neural Information Semantic Decoding
Feb 14, 2024


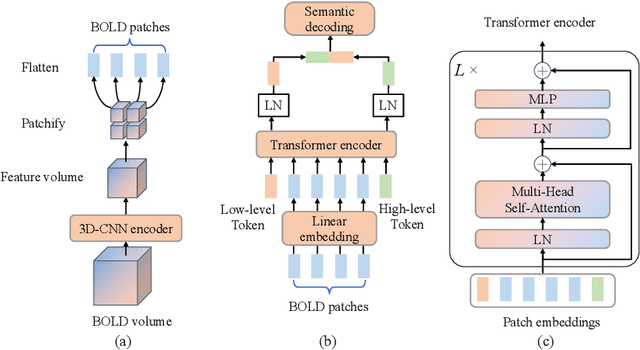
The study of decoding visual neural information faces challenges in generalizing single-subject decoding models to multiple subjects, due to individual differences. Moreover, the limited availability of data from a single subject has a constraining impact on model performance. Although prior multi-subject decoding methods have made significant progress, they still suffer from several limitations, including difficulty in extracting global neural response features, linear scaling of model parameters with the number of subjects, and inadequate characterization of the relationship between neural responses of different subjects to various stimuli. To overcome these limitations, we propose a CLIP-guided Multi-sUbject visual neural information SEmantic Decoding (CLIP-MUSED) method. Our method consists of a Transformer-based feature extractor to effectively model global neural representations. It also incorporates learnable subject-specific tokens that facilitates the aggregation of multi-subject data without a linear increase of parameters. Additionally, we employ representational similarity analysis (RSA) to guide token representation learning based on the topological relationship of visual stimuli in the representation space of CLIP, enabling full characterization of the relationship between neural responses of different subjects under different stimuli. Finally, token representations are used for multi-subject semantic decoding. Our proposed method outperforms single-subject decoding methods and achieves state-of-the-art performance among the existing multi-subject methods on two fMRI datasets. Visualization results provide insights into the effectiveness of our proposed method. Code is available at https://github.com/CLIP-MUSED/CLIP-MUSED.