 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEOS-Bench: A Comprehensive Benchmark for Earth Observation Satellite Scheduling
Apr 28, 2026Earth observation satellite imaging scheduling is a challenging NP-hard combinatorial optimisation problem central to space mission operations. While next-generation agile Earth observation satellites (EOS) increase operational flexibility, they also significantly raise scheduling complexity. The lack of a unified, open-source benchmark makes it difficult to compare algorithms across studies. This paper introduces EOS-Bench, a comprehensive framework for systematic and reproducible evaluation of scheduling methods. By integrating high-fidelity orbital dynamics and platform constraints, EOS-Bench generates 1,390 scenarios and 13,900 benchmark instances, spanning from small-scale validation cases to large coordination problems with up to 1,000 satellites and 10,000 requests. We further propose a scenario characterisation scheme to quantify structural difficulty based on factors such as opportunity density, task flexibility, conflict intensity, and satellite congestion. A multidimensional evaluation protocol is introduced, assessing performance across five metrics: task profit, completion rate, workload balance, timeliness, and runtime. The framework is evaluated using mixed-integer programming, heuristics, meta-heuristics, and deep reinforcement learning across both agile and non-agile settings. Results show that EOS-Bench effectively distinguishes solver performance across scales and conditions, revealing trade-offs between solution quality and computational efficiency, and providing deeper insight into scenario complexity. EOS-Bench offers a unified and extensible open testbed for advancing research in Earth observation satellite scheduling. The code and data are available at https://github.com/Ethan19YQ/EOS-Bench.
TableVision: A Large-Scale Benchmark for Spatially Grounded Reasoning over Complex Hierarchical Tables
Apr 04, 2026Structured tables are essential for conveying high-density information in professional domains such as finance, healthcare, and scientific research. Despite the progress in Multimodal Large Language Models (MLLMs), reasoning performance remains limited for complex tables with hierarchical layouts. In this paper, we identify a critical Perception Bottleneck through quantitative analysis. We find that as task complexity scales, the number of involved discrete visual regions increases disproportionately. This processing density leads to an internal "Perceptual Overload," where MLLMs struggle to maintain accurate spatial attention during implicit generation. To address this bottleneck, we introduce TableVision, a large-scale, trajectory-aware benchmark designed for spatially grounded reasoning. TableVision stratifies tabular tasks into three cognitive levels (Perception, Reasoning, and Analysis) across 13 sub-categories. By utilizing a rendering-based deterministic grounding pipeline, the dataset explicitly couples multi-step logical deductions with pixel-perfect spatial ground truths, comprising 6,799 high-fidelity reasoning trajectories. Our empirical results, supported by diagnostic probing, demonstrate that explicit spatial constraints significantly recover the reasoning potential of MLLMs. Furthermore, our two-stage decoupled framework achieves a robust 12.3% overall accuracy improvement on the test set. TableVision provides a rigorous testbed and a fresh perspective on the synergy between perception and logic in document understanding.
Learning Additively Compositional Latent Actions for Embodied AI
Apr 03, 2026Latent action learning infers pseudo-action labels from visual transitions, providing an approach to leverage internet-scale video for embodied AI. However, most methods learn latent actions without structural priors that encode the additive, compositional structure of physical motion. As a result, latents often entangle irrelevant scene details or information about future observations with true state changes and miscalibrate motion magnitude. We introduce Additively Compositional Latent Action Model (AC-LAM), which enforces scene-wise additive composition structure over short horizons on the latent action space. These AC constraints encourage simple algebraic structure in the latent action space~(identity, inverse, cycle consistency) and suppress information that does not compose additively. Empirically, AC-LAM learns more structured, motion-specific, and displacement-calibrated latent actions and provides stronger supervision for downstream policy learning, outperforming state-of-the-art LAMs across simulated and real-world tabletop tasks.
UniG2U-Bench: Do Unified Models Advance Multimodal Understanding?
Mar 03, 2026Unified multimodal models have recently demonstrated strong generative capabilities, yet whether and when generation improves understanding remains unclear. Existing benchmarks lack a systematic exploration of the specific tasks where generation facilitates understanding. To this end, we introduce UniG2U-Bench, a comprehensive benchmark categorizing generation-to-understanding (G2U) evaluation into 7 regimes and 30 subtasks, requiring varying degrees of implicit or explicit visual transformations. Extensive evaluation of over 30 models reveals three core findings: 1) Unified models generally underperform their base Vision-Language Models (VLMs), and Generate-then-Answer (GtA) inference typically degrades performance relative to direct inference. 2) Consistent enhancements emerge in spatial intelligence, visual illusions, or multi-round reasoning subtasks, where enhanced spatial and shape perception, as well as multi-step intermediate image states, prove beneficial. 3) Tasks with similar reasoning structures and models sharing architectures exhibit correlated behaviors, suggesting that generation-understanding coupling induces class-consistent inductive biases over tasks, pretraining data, and model architectures. These findings highlight the necessity for more diverse training data and novel paradigms to fully unlock the potential of unified multimodal modeling.
BagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
Feb 11, 2026Equipping embodied agents with the ability to reason about tasks, foresee physical outcomes, and generate precise actions is essential for general-purpose manipulation. While recent Vision-Language-Action (VLA) models have leveraged pre-trained foundation models, they typically focus on either linguistic planning or visual forecasting in isolation. These methods rarely integrate both capabilities simultaneously to guide action generation, leading to suboptimal performance in complex, long-horizon manipulation tasks. To bridge this gap, we propose BagelVLA, a unified model that integrates linguistic planning, visual forecasting, and action generation within a single framework. Initialized from a pretrained unified understanding and generative model, BagelVLA is trained to interleave textual reasoning and visual prediction directly into the action execution loop. To efficiently couple these modalities, we introduce Residual Flow Guidance (RFG), which initializes from current observation and leverages single-step denoising to extract predictive visual features, guiding action generation with minimal latency. Extensive experiments demonstrate that BagelVLA outperforms existing baselines by a significant margin on multiple simulated and real-world benchmarks, particularly in tasks requiring multi-stage reasoning.
VideoAfford: Grounding 3D Affordance from Human-Object-Interaction Videos via Multimodal Large Language Model
Feb 10, 20263D affordance grounding aims to highlight the actionable regions on 3D objects, which is crucial for robotic manipulation. Previous research primarily focused on learning affordance knowledge from static cues such as language and images, which struggle to provide sufficient dynamic interaction context that can reveal temporal and causal cues. To alleviate this predicament, we collect a comprehensive video-based 3D affordance dataset, \textit{VIDA}, which contains 38K human-object-interaction videos covering 16 affordance types, 38 object categories, and 22K point clouds. Based on \textit{VIDA}, we propose a strong baseline: VideoAfford, which activates multimodal large language models with additional affordance segmentation capabilities, enabling both world knowledge reasoning and fine-grained affordance grounding within a unified framework. To enhance action understanding capability, we leverage a latent action encoder to extract dynamic interaction priors from HOI videos. Moreover, we introduce a \textit{spatial-aware} loss function to enable VideoAfford to obtain comprehensive 3D spatial knowledge. Extensive experimental evaluations demonstrate that our model significantly outperforms well-established methods and exhibits strong open-world generalization with affordance reasoning abilities. All datasets and code will be publicly released to advance research in this area.
VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jan 06, 2026Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
How Do VLAs Effectively Inherit from VLMs?
Nov 10, 2025Vision-language-action (VLA) models hold the promise to attain generalizable embodied control. To achieve this, a pervasive paradigm is to leverage the rich vision-semantic priors of large vision-language models (VLMs). However, the fundamental question persists: How do VLAs effectively inherit the prior knowledge from VLMs? To address this critical question, we introduce a diagnostic benchmark, GrinningFace, an emoji tabletop manipulation task where the robot arm is asked to place objects onto printed emojis corresponding to language instructions. This task design is particularly revealing -- knowledge associated with emojis is ubiquitous in Internet-scale datasets used for VLM pre-training, yet emojis themselves are largely absent from standard robotics datasets. Consequently, they provide a clean proxy: successful task completion indicates effective transfer of VLM priors to embodied control. We implement this diagnostic task in both simulated environment and a real robot, and compare various promising techniques for knowledge transfer. Specifically, we investigate the effects of parameter-efficient fine-tuning, VLM freezing, co-training, predicting discretized actions, and predicting latent actions. Through systematic evaluation, our work not only demonstrates the critical importance of preserving VLM priors for the generalization of VLA but also establishes guidelines for future research in developing truly generalizable embodied AI systems.
Align-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025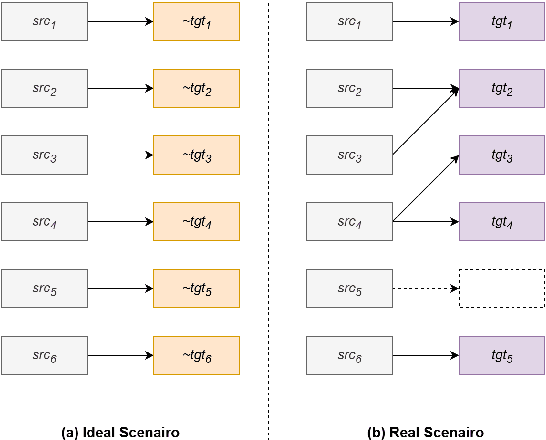
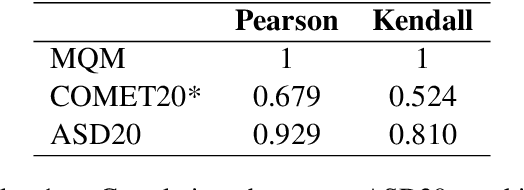
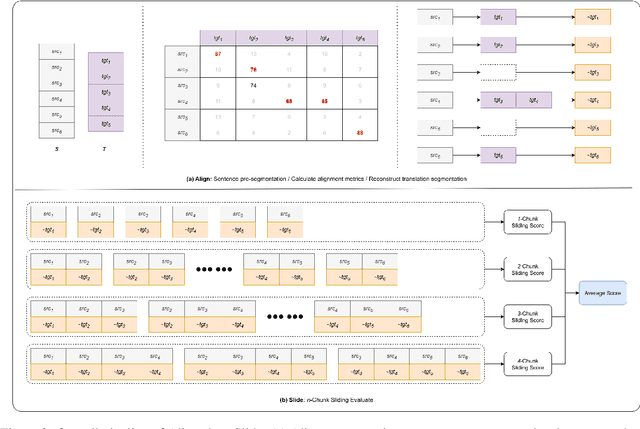
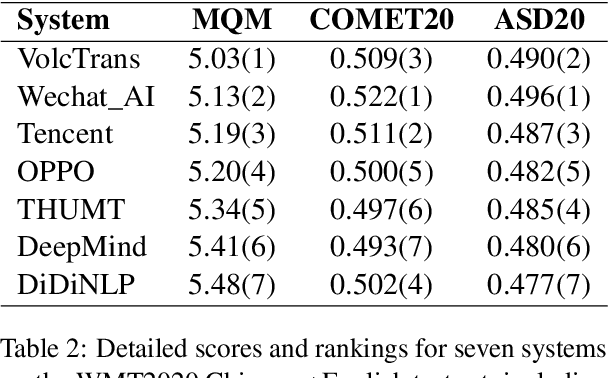
Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.
Generative Annotation for ASR Named Entity Correction
Aug 28, 2025

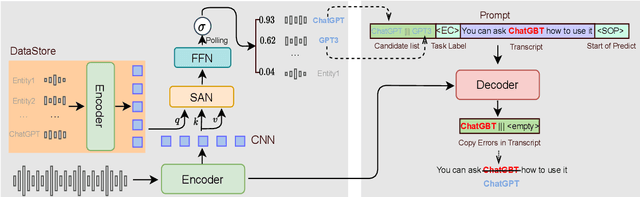

End-to-end automatic speech recognition systems often fail to transcribe domain-specific named entities, causing catastrophic failures in downstream tasks. Numerous fast and lightweight named entity correction (NEC) models have been proposed in recent years. These models, mainly leveraging phonetic-level edit distance algorithms, have shown impressive performances. However, when the forms of the wrongly-transcribed words(s) and the ground-truth entity are significantly different, these methods often fail to locate the wrongly transcribed words in hypothesis, thus limiting their usage. We propose a novel NEC method that utilizes speech sound features to retrieve candidate entities. With speech sound features and candidate entities, we inovatively design a generative method to annotate entity errors in ASR transcripts and replace the text with correct entities. This method is effective in scenarios of word form difference. We test our method using open-source and self-constructed test sets. The results demonstrate that our NEC method can bring significant improvement to entity accuracy. We will open source our self-constructed test set and training data.