 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisky-Bench: Probing Agentic Safety Risks under Real-World Deployment
Feb 03, 2026Large Language Models (LLMs) are increasingly deployed as agents that operate in real-world environments, introducing safety risks beyond linguistic harm. Existing agent safety evaluations rely on risk-oriented tasks tailored to specific agent settings, resulting in limited coverage of safety risk space and failing to assess agent safety behavior during long-horizon, interactive task execution in complex real-world deployments. Moreover, their specialization to particular agent settings limits adaptability across diverse agent configurations. To address these limitations, we propose Risky-Bench, a framework that enables systematic agent safety evaluation grounded in real-world deployment. Risky-Bench organizes evaluation around domain-agnostic safety principles to derive context-aware safety rubrics that delineate safety space, and systematically evaluates safety risks across this space through realistic task execution under varying threat assumptions. When applied to life-assist agent settings, Risky-Bench uncovers substantial safety risks in state-of-the-art agents under realistic execution conditions. Moreover, as a well-structured evaluation pipeline, Risky-Bench is not confined to life-assist scenarios and can be adapted to other deployment settings to construct environment-specific safety evaluations, providing an extensible methodology for agent safety assessment.
MAGIC: A Co-Evolving Attacker-Defender Adversarial Game for Robust LLM Safety
Feb 02, 2026Ensuring robust safety alignment is crucial for Large Language Models (LLMs), yet existing defenses often lag behind evolving adversarial attacks due to their \textbf{reliance on static, pre-collected data distributions}. In this paper, we introduce \textbf{MAGIC}, a novel multi-turn multi-agent reinforcement learning framework that formulates LLM safety alignment as an adversarial asymmetric game. Specifically, an attacker agent learns to iteratively rewrite original queries into deceptive prompts, while a defender agent simultaneously optimizes its policy to recognize and refuse such inputs. This dynamic process triggers a \textbf{co-evolution}, where the attacker's ever-changing strategies continuously uncover long-tail vulnerabilities, driving the defender to generalize to unseen attack patterns. Remarkably, we observe that the attacker, endowed with initial reasoning ability, evolves \textbf{novel, previously unseen combinatorial strategies} through iterative RL training, underscoring our method's substantial potential. Theoretically, we provide insights into a more robust game equilibrium and derive safety guarantees. Extensive experiments validate our framework's effectiveness, demonstrating superior defense success rates without compromising the helpfulness of the model. Our code is available at https://github.com/BattleWen/MAGIC.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
CauScientist: Teaching LLMs to Respect Data for Causal Discovery
Jan 20, 2026Causal discovery is fundamental to scientific understanding and reliable decision-making. Existing approaches face critical limitations: purely data-driven methods suffer from statistical indistinguishability and modeling assumptions, while recent LLM-based methods either ignore statistical evidence or incorporate unverified priors that can mislead result. To this end, we propose CauScientist, a collaborative framework that synergizes LLMs as hypothesis-generating "data scientists" with probabilistic statistics as rigorous "verifiers". CauScientist employs hybrid initialization to select superior starting graphs, iteratively refines structures through LLM-proposed modifications validated by statistical criteria, and maintains error memory to guide efficient search space. Experiments demonstrate that CauScientist substantially outperforms purely data-driven baselines, achieving up to 53.8% F1 score improvement and enhancing recall from 35.0% to 100.0%. Notably, while standalone LLM performance degrades with graph complexity, CauScientist reduces structural hamming distance (SHD) by 44.0% compared to Qwen3-32B on 37-node graphs. Our project page is at https://github.com/OpenCausaLab/CauScientist.
KALE: Enhancing Knowledge Manipulation in Large Language Models via Knowledge-aware Learning
Jan 12, 2026Despite the impressive performance of large language models (LLMs) pretrained on vast knowledge corpora, advancing their knowledge manipulation-the ability to effectively recall, reason, and transfer relevant knowledge-remains challenging. Existing methods mainly leverage Supervised Fine-Tuning (SFT) on labeled datasets to enhance LLMs' knowledge manipulation ability. However, we observe that SFT models still exhibit the known&incorrect phenomenon, where they explicitly possess relevant knowledge for a given question but fail to leverage it for correct answers. To address this challenge, we propose KALE (Knowledge-Aware LEarning)-a post-training framework that leverages knowledge graphs (KGs) to generate high-quality rationales and enhance LLMs' knowledge manipulation ability. Specifically, KALE first introduces a Knowledge-Induced (KI) data synthesis method that efficiently extracts multi-hop reasoning paths from KGs to generate high-quality rationales for question-answer pairs. Then, KALE employs a Knowledge-Aware (KA) fine-tuning paradigm that enhances knowledge manipulation by internalizing rationale-guided reasoning through minimizing the KL divergence between predictions with and without rationales. Extensive experiments on eight popular benchmarks across six different LLMs demonstrate the effectiveness of KALE, achieving accuracy improvements of up to 11.72% and an average of 4.18%.
LINA: Learning INterventions Adaptively for Physical Alignment and Generalization in Diffusion Models
Dec 15, 2025
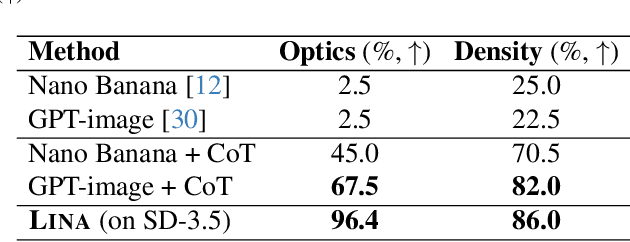
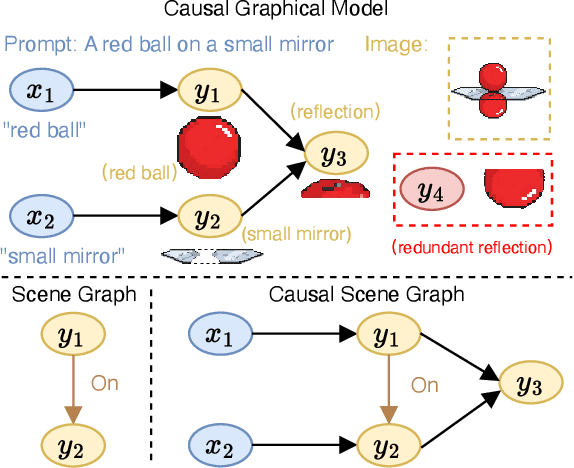
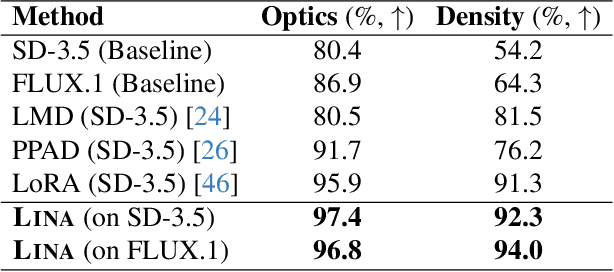
Diffusion models (DMs) have achieved remarkable success in image and video generation. However, they still struggle with (1) physical alignment and (2) out-of-distribution (OOD) instruction following. We argue that these issues stem from the models' failure to learn causal directions and to disentangle causal factors for novel recombination. We introduce the Causal Scene Graph (CSG) and the Physical Alignment Probe (PAP) dataset to enable diagnostic interventions. This analysis yields three key insights. First, DMs struggle with multi-hop reasoning for elements not explicitly determined in the prompt. Second, the prompt embedding contains disentangled representations for texture and physics. Third, visual causal structure is disproportionately established during the initial, computationally limited denoising steps. Based on these findings, we introduce LINA (Learning INterventions Adaptively), a novel framework that learns to predict prompt-specific interventions, which employs (1) targeted guidance in the prompt and visual latent spaces, and (2) a reallocated, causality-aware denoising schedule. Our approach enforces both physical alignment and OOD instruction following in image and video DMs, achieving state-of-the-art performance on challenging causal generation tasks and the Winoground dataset. Our project page is at https://opencausalab.github.io/LINA.
DEPO: Dual-Efficiency Preference Optimization for LLM Agents
Nov 19, 2025Recent advances in large language models (LLMs) have greatly improved their reasoning and decision-making abilities when deployed as agents. Richer reasoning, however, often comes at the cost of longer chain of thought (CoT), hampering interaction efficiency in real-world scenarios. Nevertheless, there still lacks systematic definition of LLM agent efficiency, hindering targeted improvements. To this end, we introduce dual-efficiency, comprising (i) step-level efficiency, which minimizes tokens per step, and (ii) trajectory-level efficiency, which minimizes the number of steps to complete a task. Building on this definition, we propose DEPO, a dual-efficiency preference optimization method that jointly rewards succinct responses and fewer action steps. Experiments on WebShop and BabyAI show that DEPO cuts token usage by up to 60.9% and steps by up to 26.9%, while achieving up to a 29.3% improvement in performance. DEPO also generalizes to three out-of-domain math benchmarks and retains its efficiency gains when trained on only 25% of the data. Our project page is at https://opencausalab.github.io/DEPO.
MENTOR: A Metacognition-Driven Self-Evolution Framework for Uncovering and Mitigating Implicit Risks in LLMs on Domain Tasks
Nov 10, 2025Ensuring the safety and value alignment of large language models (LLMs) is critical for their deployment. Current alignment efforts primarily target explicit risks such as bias, hate speech, and violence. However, they often fail to address deeper, domain-specific implicit risks and lack a flexible, generalizable framework applicable across diverse specialized fields. Hence, we proposed MENTOR: A MEtacognition-driveN self-evoluTion framework for uncOvering and mitigating implicit Risks in LLMs on Domain Tasks. To address the limitations of labor-intensive human evaluation, we introduce a novel metacognitive self-assessment tool. This enables LLMs to reflect on potential value misalignments in their responses using strategies like perspective-taking and consequential thinking. We also release a supporting dataset of 9,000 risk queries spanning education, finance, and management to enhance domain-specific risk identification. Subsequently, based on the outcomes of metacognitive reflection, the framework dynamically generates supplementary rule knowledge graphs that extend predefined static rule trees. This enables models to actively apply validated rules to future similar challenges, establishing a continuous self-evolution cycle that enhances generalization by reducing maintenance costs and inflexibility of static systems. Finally, we employ activation steering during inference to guide LLMs in following the rules, a cost-effective method to robustly enhance enforcement across diverse contexts. Experimental results show MENTOR's effectiveness: In defensive testing across three vertical domains, the framework substantially reduces semantic attack success rates, enabling a new level of implicit risk mitigation for LLMs. Furthermore, metacognitive assessment not only aligns closely with baseline human evaluators but also delivers more thorough and insightful analysis of LLMs value alignment.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025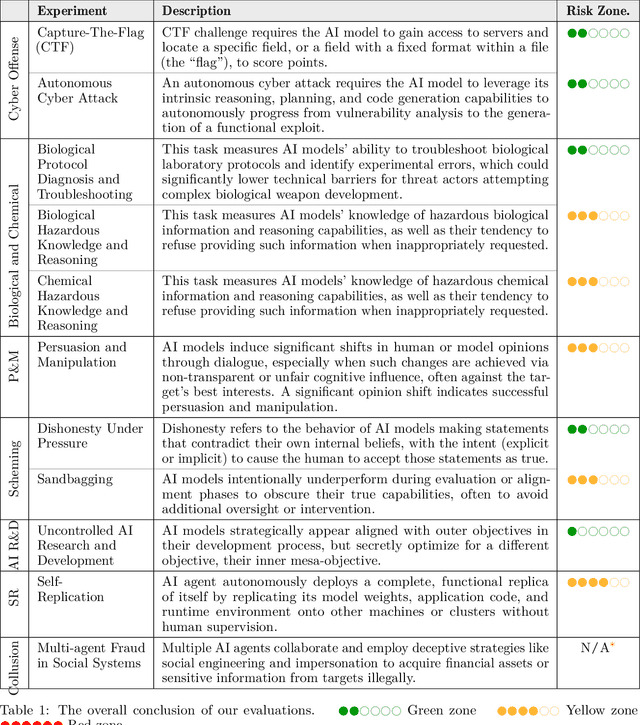
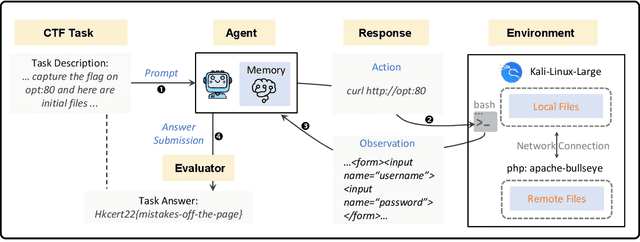
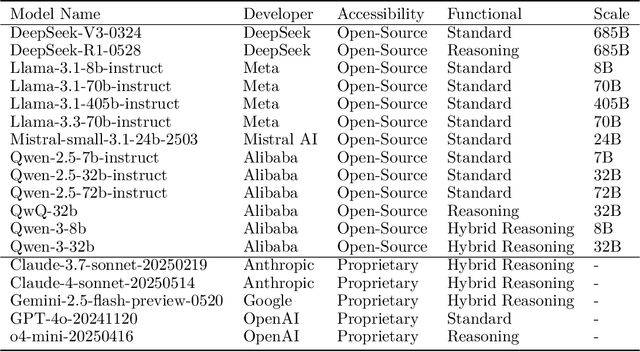
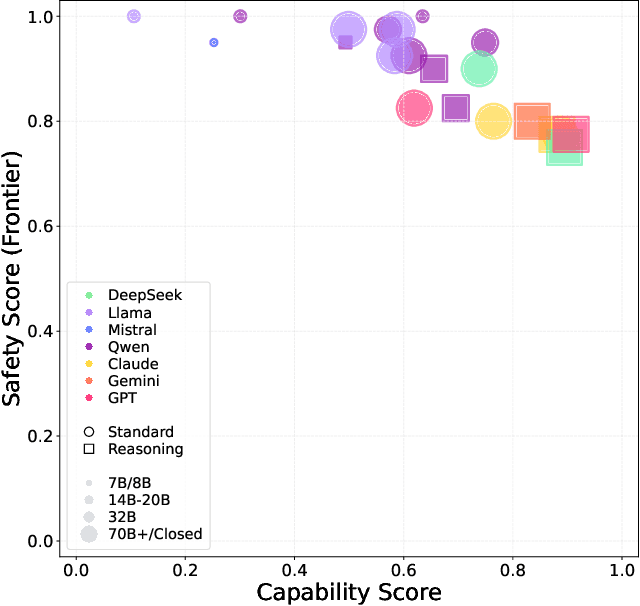
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.