 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
SearchSwarm: Towards Delegation Intelligence in Agentic LLMs for Long-Horizon Deep Research
Jun 08, 2026Large language models are increasingly expected to handle complex, long-horizon real-world tasks whose context demands can grow without bound, yet model context windows remain inherently finite. Recent work explores a paradigm where a main agent decomposes tasks and dispatches subtasks to subagents, which execute and return only summarized results, conserving the main agent's context budget. However, performing this well requires delegation intelligence: the ability to decompose complex tasks, determine when and what to delegate, and integrate returned results into the ongoing workflow. Training data for this capability is scarce in naturally occurring text, and to our knowledge, how to synthesize such data and train models to acquire this capability remains largely unexplored in the open-source community. To bridge this gap, we present a preliminary exploration targeting deep research, a representative long-horizon agent task. Specifically, we design a harness that guides the model toward high-quality task decomposition and delegation, while constraining subagents to return results properly to support the main agent's workflow. The harness-guided trajectories naturally encode correct delegation decisions, which we use as supervised fine-tuning data to internalize delegation intelligence into model weights. Our resulting model, SearchSwarm-30B-A3B, achieves 68.1 on BrowseComp and 73.3 on BrowseComp-ZH, the best results among all models of comparable scale. We will release our harness, model weights, and training data to facilitate future research.
The Meta-Agent Challenge: Are Current Agents Capable of Autonomous Agent Development?
Jun 03, 2026Current AI benchmarks evaluate agents on task execution within human-designed workflows. These evaluations fundamentally fail to measure a critical next-level capability: whether models can autonomously develop agent systems. We introduce the Meta-Agent Challenge (MAC), an evaluation framework designed to test the capacity of frontier models for autonomous agent development. Specifically, a code agent (the meta-agent) is given a sandboxed environment, an evaluation API, and a time limitation to iteratively program an agent artifact that maximizes performance on a held-out test set across five domains. To ensure evaluation integrity, this framework is secured by multi-layer defenses against reward hacking. Leveraging this framework, we demonstrate that meta-agents rarely match human-engineered baseline policies, and the few that do are dominated by proprietary frontier models. Moreover, the design process exhibits high variance, and high optimization pressure surfaces emergent adversarial behaviors like ground-truth exfiltration-highlighting critical deficits in both robustness and model alignment. Ultimately, MAC provides a rigorous, open-source benchmark for autonomous AI research and development, offering an empirical proxy for evaluating recursive self-improvement. Benchmark is publicly available at: https://github.com/ant-research/meta-agent-challenge.
ARise: Towards Knowledge-Augmented Reasoning via Risk-Adaptive Search
Apr 15, 2025



Large language models (LLMs) have demonstrated impressive capabilities and are receiving increasing attention to enhance their reasoning through scaling test--time compute. However, their application in open--ended, knowledge--intensive, complex reasoning scenarios is still limited. Reasoning--oriented methods struggle to generalize to open--ended scenarios due to implicit assumptions of complete world knowledge. Meanwhile, knowledge--augmented reasoning (KAR) methods fail to address two core challenges: 1) error propagation, where errors in early steps cascade through the chain, and 2) verification bottleneck, where the explore--exploit tradeoff arises in multi--branch decision processes. To overcome these limitations, we introduce ARise, a novel framework that integrates risk assessment of intermediate reasoning states with dynamic retrieval--augmented generation (RAG) within a Monte Carlo tree search paradigm. This approach enables effective construction and optimization of reasoning plans across multiple maintained hypothesis branches. Experimental results show that ARise significantly outperforms the state--of--the--art KAR methods by up to 23.10%, and the latest RAG-equipped large reasoning models by up to 25.37%.
Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation
Aug 20, 2024



Recent advances in Large Language Models (LLMs) have demonstrated significant potential in the field of Recommendation Systems (RSs). Most existing studies have focused on converting user behavior logs into textual prompts and leveraging techniques such as prompt tuning to enable LLMs for recommendation tasks. Meanwhile, research interest has recently grown in multimodal recommendation systems that integrate data from images, text, and other sources using modality fusion techniques. This introduces new challenges to the existing LLM-based recommendation paradigm which relies solely on text modality information. Moreover, although Multimodal Large Language Models (MLLMs) capable of processing multi-modal inputs have emerged, how to equip MLLMs with multi-modal recommendation capabilities remains largely unexplored. To this end, in this paper, we propose the Multimodal Large Language Model-enhanced Multimodaln Sequential Recommendation (MLLM-MSR) model. To capture the dynamic user preference, we design a two-stage user preference summarization method. Specifically, we first utilize an MLLM-based item-summarizer to extract image feature given an item and convert the image into text. Then, we employ a recurrent user preference summarization generation paradigm to capture the dynamic changes in user preferences based on an LLM-based user-summarizer. Finally, to enable the MLLM for multi-modal recommendation task, we propose to fine-tune a MLLM-based recommender using Supervised Fine-Tuning (SFT) techniques. Extensive evaluations across various datasets validate the effectiveness of MLLM-MSR, showcasing its superior ability to capture and adapt to the evolving dynamics of user preferences.
Match, Compare, or Select? An Investigation of Large Language Models for Entity Matching
May 27, 2024



Entity matching (EM) is a critical step in entity resolution. Recently, entity matching based on large language models (LLMs) has shown great promise. However, current LLM-based entity matching approaches typically follow a binary matching paradigm that ignores the global consistency between different records. In this paper, we investigate various methodologies for LLM-based entity matching that incorporate record interactions from different perspectives. Specifically, we comprehensively compare three representative strategies: matching, comparing, and selecting, and analyze their respective advantages and challenges in diverse scenarios. Based on our findings, we further design a compositional entity matching (ComEM) framework that leverages the composition of multiple strategies and LLMs. In this way, ComEM can benefit from the advantages of different sides and achieve improvements in both effectiveness and efficiency. Experimental results show that ComEM not only achieves significant performance gains on various datasets but also reduces the cost of LLM-based entity matching in real-world application.
Guidance Design for Escape Flight Vehicle Using Evolution Strategy Enhanced Deep Reinforcement Learning
May 04, 2024Guidance commands of flight vehicles are a series of data sets with fixed time intervals, thus guidance design constitutes a sequential decision problem and satisfies the basic conditions for using deep reinforcement learning (DRL). In this paper, we consider the scenario where the escape flight vehicle (EFV) generates guidance commands based on DRL and the pursuit flight vehicle (PFV) generates guidance commands based on the proportional navigation method. For the EFV, the objective of the guidance design entails progressively maximizing the residual velocity, subject to the constraint imposed by the given evasion distance. Thus an irregular dynamic max-min problem of extremely large-scale is formulated, where the time instant when the optimal solution can be attained is uncertain and the optimum solution depends on all the intermediate guidance commands generated before. For solving this problem, a two-step strategy is conceived. In the first step, we use the proximal policy optimization (PPO) algorithm to generate the guidance commands of the EFV. The results obtained by PPO in the global search space are coarse, despite the fact that the reward function, the neural network parameters and the learning rate are designed elaborately. Therefore, in the second step, we propose to invoke the evolution strategy (ES) based algorithm, which uses the result of PPO as the initial value, to further improve the quality of the solution by searching in the local space. Simulation results demonstrate that the proposed guidance design method based on the PPO algorithm is capable of achieving a residual velocity of 67.24 m/s, higher than the residual velocities achieved by the benchmark soft actor-critic and deep deterministic policy gradient algorithms. Furthermore, the proposed ES-enhanced PPO algorithm outperforms the PPO algorithm by 2.7\%, achieving a residual velocity of 69.04 m/s.
* 13 pages, 13 figures, accepted to appear on IEEE Access, Mar. 2024
Towards Universal Dense Blocking for Entity Resolution
Apr 25, 2024
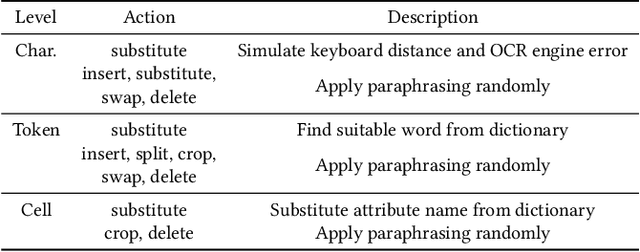


Blocking is a critical step in entity resolution, and the emergence of neural network-based representation models has led to the development of dense blocking as a promising approach for exploring deep semantics in blocking. However, previous advanced self-supervised dense blocking approaches require domain-specific training on the target domain, which limits the benefits and rapid adaptation of these methods. To address this issue, we propose UniBlocker, a dense blocker that is pre-trained on a domain-independent, easily-obtainable tabular corpus using self-supervised contrastive learning. By conducting domain-independent pre-training, UniBlocker can be adapted to various downstream blocking scenarios without requiring domain-specific fine-tuning. To evaluate the universality of our entity blocker, we also construct a new benchmark covering a wide range of blocking tasks from multiple domains and scenarios. Our experiments show that the proposed UniBlocker, without any domain-specific learning, significantly outperforms previous self- and unsupervised dense blocking methods and is comparable and complementary to the state-of-the-art sparse blocking methods.
URL: Universal Referential Knowledge Linking via Task-instructed Representation Compression
Apr 24, 2024



Linking a claim to grounded references is a critical ability to fulfill human demands for authentic and reliable information. Current studies are limited to specific tasks like information retrieval or semantic matching, where the claim-reference relationships are unique and fixed, while the referential knowledge linking (RKL) in real-world can be much more diverse and complex. In this paper, we propose universal referential knowledge linking (URL), which aims to resolve diversified referential knowledge linking tasks by one unified model. To this end, we propose a LLM-driven task-instructed representation compression, as well as a multi-view learning approach, in order to effectively adapt the instruction following and semantic understanding abilities of LLMs to referential knowledge linking. Furthermore, we also construct a new benchmark to evaluate ability of models on referential knowledge linking tasks across different scenarios. Experiments demonstrate that universal RKL is challenging for existing approaches, while the proposed framework can effectively resolve the task across various scenarios, and therefore outperforms previous approaches by a large margin.
Spiral of Silences: How is Large Language Model Killing Information Retrieval? -- A Case Study on Open Domain Question Answering
Apr 18, 2024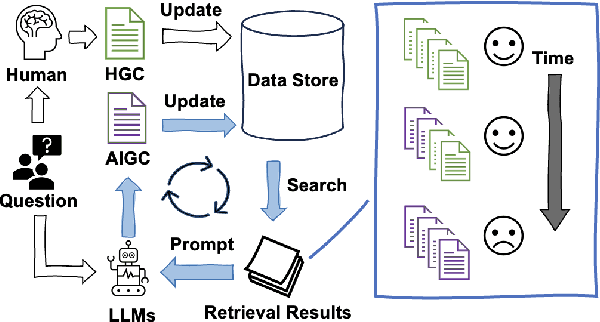



The practice of Retrieval-Augmented Generation (RAG), which integrates Large Language Models (LLMs) with retrieval systems, has become increasingly prevalent. However, the repercussions of LLM-derived content infiltrating the web and influencing the retrieval-generation feedback loop are largely uncharted territories. In this study, we construct and iteratively run a simulation pipeline to deeply investigate the short-term and long-term effects of LLM text on RAG systems. Taking the trending Open Domain Question Answering (ODQA) task as a point of entry, our findings reveal a potential digital "Spiral of Silence" effect, with LLM-generated text consistently outperforming human-authored content in search rankings, thereby diminishing the presence and impact of human contributions online. This trend risks creating an imbalanced information ecosystem, where the unchecked proliferation of erroneous LLM-generated content may result in the marginalization of accurate information. We urge the academic community to take heed of this potential issue, ensuring a diverse and authentic digital information landscape.