 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuXi-Linear: Unleashing the Power of Linear Attention in Long-term Time-aware Sequential Recommendation
Feb 27, 2026Modern recommendation systems primarily rely on attention mechanisms with quadratic complexity, which limits their ability to handle long user sequences and slows down inference. While linear attention is a promising alternative, existing research faces three critical challenges: (1) temporal signals are often overlooked or integrated via naive coupling that causes mutual interference between temporal and semantic signals while neglecting behavioral periodicity; (2) insufficient positional information provided by existing linear frameworks; and (3) a primary focus on short sequences and shallow architectures. To address these issues, we propose FuXi-Linear, a linear-complexity model designed for efficient long-sequence recommendation. Our approach introduces two key components: (1) a Temporal Retention Channel that independently computes periodic attention weights using temporal data, preventing crosstalk between temporal and semantic signals; (2) a Linear Positional Channel that integrates positional information through learnable kernels within linear complexity. Moreover, we demonstrate that FuXi-Linear exhibits a robust power-law scaling property at a thousand-length scale, a characteristic largely unexplored in prior linear recommendation studies. Extensive experiments on sequences of several thousand tokens demonstrate that FuXi-Linear outperforms state-of-the-art models in recommendation quality, while achieving up to 10$\times$ speedup in the prefill stage and up to 21$\times$ speedup in the decode stage compared to competitive baselines. Our code has been released in a public repository https://github.com/USTC-StarTeam/fuxi-linear.
Generative Data Transformation: From Mixed to Unified Data
Feb 26, 2026Recommendation model performance is intrinsically tied to the quality, volume, and relevance of their training data. To address common challenges like data sparsity and cold start, recent researchs have leveraged data from multiple auxiliary domains to enrich information within the target domain. However, inherent domain gaps can degrade the quality of mixed-domain data, leading to negative transfer and diminished model performance. Existing prevailing \emph{model-centric} paradigm -- which relies on complex, customized architectures -- struggles to capture the subtle, non-structural sequence dependencies across domains, leading to poor generalization and high demands on computational resources. To address these shortcomings, we propose \textsc{Taesar}, a \emph{data-centric} framework for \textbf{t}arget-\textbf{a}lign\textbf{e}d \textbf{s}equenti\textbf{a}l \textbf{r}egeneration, which employs a contrastive decoding mechanism to adaptively encode cross-domain context into target-domain sequences. It employs contrastive decoding to encode cross-domain context into target sequences, enabling standard models to learn intricate dependencies without complex fusion architectures. Experiments show \textsc{Taesar} outperforms model-centric solutions and generalizes to various sequential models. By generating enriched datasets, \textsc{Taesar} effectively combines the strengths of data- and model-centric paradigms. The code accompanying this paper is available at~ \textcolor{blue}{https://github.com/USTC-StarTeam/Taesar}.
BlossomRec: Block-level Fused Sparse Attention Mechanism for Sequential Recommendations
Dec 15, 2025Transformer structures have been widely used in sequential recommender systems (SRS). However, as user interaction histories increase, computational time and memory requirements also grow. This is mainly caused by the standard attention mechanism. Although there exist many methods employing efficient attention and SSM-based models, these approaches struggle to effectively model long sequences and may exhibit unstable performance on short sequences. To address these challenges, we design a sparse attention mechanism, BlossomRec, which models both long-term and short-term user interests through attention computation to achieve stable performance across sequences of varying lengths. Specifically, we categorize user interests in recommendation systems into long-term and short-term interests, and compute them using two distinct sparse attention patterns, with the results combined through a learnable gated output. Theoretically, it significantly reduces the number of interactions participating in attention computation. Extensive experiments on four public datasets demonstrate that BlossomRec, when integrated with state-of-the-art Transformer-based models, achieves comparable or even superior performance while significantly reducing memory usage, providing strong evidence of BlossomRec's efficiency and effectiveness.The code is available at https://github.com/ronineume/BlossomRec.
Preference Trajectory Modeling via Flow Matching for Sequential Recommendation
Aug 25, 2025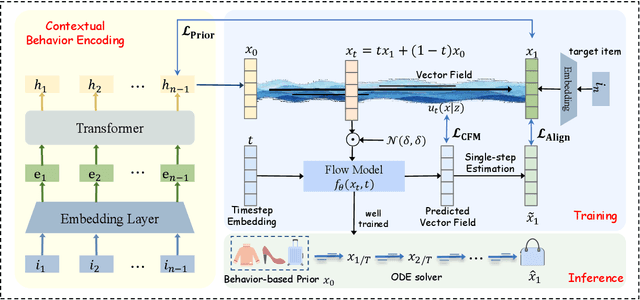
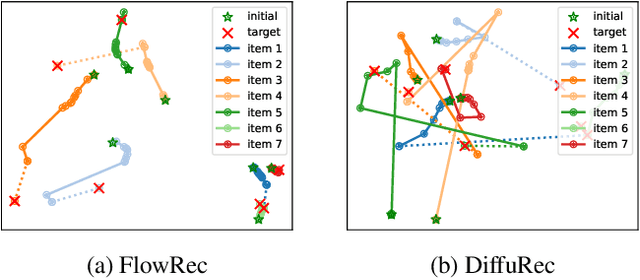
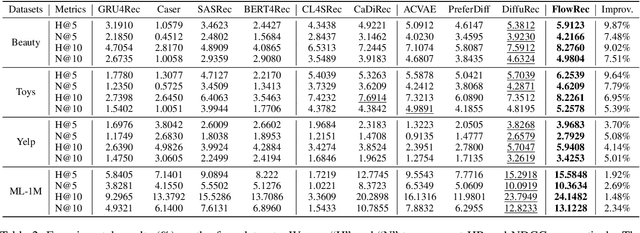
Sequential recommendation predicts each user's next item based on their historical interaction sequence. Recently, diffusion models have attracted significant attention in this area due to their strong ability to model user interest distributions. They typically generate target items by denoising Gaussian noise conditioned on historical interactions. However, these models face two critical limitations. First, they exhibit high sensitivity to the condition, making it difficult to recover target items from pure Gaussian noise. Second, the inference process is computationally expensive, limiting practical deployment. To address these issues, we propose FlowRec, a simple yet effective sequential recommendation framework which leverages flow matching to explicitly model user preference trajectories from current states to future interests. Flow matching is an emerging generative paradigm, which offers greater flexibility in initial distributions and enables more efficient sampling. Based on this, we construct a personalized behavior-based prior distribution to replace Gaussian noise and learn a vector field to model user preference trajectories. To better align flow matching with the recommendation objective, we further design a single-step alignment loss incorporating both positive and negative samples, improving sampling efficiency and generation quality. Extensive experiments on four benchmark datasets verify the superiority of FlowRec over the state-of-the-art baselines.
SAFER: A Calibrated Risk-Aware Multimodal Recommendation Model for Dynamic Treatment Regimes
Jun 07, 2025



Dynamic treatment regimes (DTRs) are critical to precision medicine, optimizing long-term outcomes through personalized, real-time decision-making in evolving clinical contexts, but require careful supervision for unsafe treatment risks. Existing efforts rely primarily on clinician-prescribed gold standards despite the absence of a known optimal strategy, and predominantly using structured EHR data without extracting valuable insights from clinical notes, limiting their reliability for treatment recommendations. In this work, we introduce SAFER, a calibrated risk-aware tabular-language recommendation framework for DTR that integrates both structured EHR and clinical notes, enabling them to learn from each other, and addresses inherent label uncertainty by assuming ambiguous optimal treatment solution for deceased patients. Moreover, SAFER employs conformal prediction to provide statistical guarantees, ensuring safe treatment recommendations while filtering out uncertain predictions. Experiments on two publicly available sepsis datasets demonstrate that SAFER outperforms state-of-the-art baselines across multiple recommendation metrics and counterfactual mortality rate, while offering robust formal assurances. These findings underscore SAFER potential as a trustworthy and theoretically grounded solution for high-stakes DTR applications.
How to Unlock Time Series Editing? Diffusion-Driven Approach with Multi-Grained Control
Jun 05, 2025Recent advances in time series generation have shown promise, yet controlling properties in generated sequences remains challenging. Time Series Editing (TSE) - making precise modifications while preserving temporal coherence - consider both point-level constraints and segment-level controls that current methods struggle to provide. We introduce the CocktailEdit framework to enable simultaneous, flexible control across different types of constraints. This framework combines two key mechanisms: a confidence-weighted anchor control for point-wise constraints and a classifier-based control for managing statistical properties such as sums and averages over segments. Our methods achieve precise local control during the denoising inference stage while maintaining temporal coherence and integrating seamlessly, with any conditionally trained diffusion-based time series models. Extensive experiments across diverse datasets and models demonstrate its effectiveness. Our work bridges the gap between pure generative modeling and real-world time series editing needs, offering a flexible solution for human-in-the-loop time series generation and editing. The code and demo are provided for validation.
TD3: Tucker Decomposition Based Dataset Distillation Method for Sequential Recommendation
Feb 06, 2025



In the era of data-centric AI, the focus of recommender systems has shifted from model-centric innovations to data-centric approaches. The success of modern AI models is built on large-scale datasets, but this also results in significant training costs. Dataset distillation has emerged as a key solution, condensing large datasets to accelerate model training while preserving model performance. However, condensing discrete and sequentially correlated user-item interactions, particularly with extensive item sets, presents considerable challenges. This paper introduces \textbf{TD3}, a novel \textbf{T}ucker \textbf{D}ecomposition based \textbf{D}ataset \textbf{D}istillation method within a meta-learning framework, designed for sequential recommendation. TD3 distills a fully expressive \emph{synthetic sequence summary} from original data. To efficiently reduce computational complexity and extract refined latent patterns, Tucker decomposition decouples the summary into four factors: \emph{synthetic user latent factor}, \emph{temporal dynamics latent factor}, \emph{shared item latent factor}, and a \emph{relation core} that models their interconnections. Additionally, a surrogate objective in bi-level optimization is proposed to align feature spaces extracted from models trained on both original data and synthetic sequence summary beyond the na\"ive performance matching approach. In the \emph{inner-loop}, an augmentation technique allows the learner to closely fit the synthetic summary, ensuring an accurate update of it in the \emph{outer-loop}. To accelerate the optimization process and address long dependencies, RaT-BPTT is employed for bi-level optimization. Experiments and analyses on multiple public datasets have confirmed the superiority and cross-architecture generalizability of the proposed designs. Codes are released at https://github.com/USTC-StarTeam/TD3.
FuXi-$α$: Scaling Recommendation Model with Feature Interaction Enhanced Transformer
Feb 05, 2025



Inspired by scaling laws and large language models, research on large-scale recommendation models has gained significant attention. Recent advancements have shown that expanding sequential recommendation models to large-scale recommendation models can be an effective strategy. Current state-of-the-art sequential recommendation models primarily use self-attention mechanisms for explicit feature interactions among items, while implicit interactions are managed through Feed-Forward Networks (FFNs). However, these models often inadequately integrate temporal and positional information, either by adding them to attention weights or by blending them with latent representations, which limits their expressive power. A recent model, HSTU, further reduces the focus on implicit feature interactions, constraining its performance. We propose a new model called FuXi-$\alpha$ to address these issues. This model introduces an Adaptive Multi-channel Self-attention mechanism that distinctly models temporal, positional, and semantic features, along with a Multi-stage FFN to enhance implicit feature interactions. Our offline experiments demonstrate that our model outperforms existing models, with its performance continuously improving as the model size increases. Additionally, we conducted an online A/B test within the Huawei Music app, which showed a $4.76\%$ increase in the average number of songs played per user and a $5.10\%$ increase in the average listening duration per user. Our code has been released at https://github.com/USTC-StarTeam/FuXi-alpha.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation
Aug 20, 2024



Recent advances in Large Language Models (LLMs) have demonstrated significant potential in the field of Recommendation Systems (RSs). Most existing studies have focused on converting user behavior logs into textual prompts and leveraging techniques such as prompt tuning to enable LLMs for recommendation tasks. Meanwhile, research interest has recently grown in multimodal recommendation systems that integrate data from images, text, and other sources using modality fusion techniques. This introduces new challenges to the existing LLM-based recommendation paradigm which relies solely on text modality information. Moreover, although Multimodal Large Language Models (MLLMs) capable of processing multi-modal inputs have emerged, how to equip MLLMs with multi-modal recommendation capabilities remains largely unexplored. To this end, in this paper, we propose the Multimodal Large Language Model-enhanced Multimodaln Sequential Recommendation (MLLM-MSR) model. To capture the dynamic user preference, we design a two-stage user preference summarization method. Specifically, we first utilize an MLLM-based item-summarizer to extract image feature given an item and convert the image into text. Then, we employ a recurrent user preference summarization generation paradigm to capture the dynamic changes in user preferences based on an LLM-based user-summarizer. Finally, to enable the MLLM for multi-modal recommendation task, we propose to fine-tune a MLLM-based recommender using Supervised Fine-Tuning (SFT) techniques. Extensive evaluations across various datasets validate the effectiveness of MLLM-MSR, showcasing its superior ability to capture and adapt to the evolving dynamics of user preferences.