 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Large Recommendation Models: Emerging Trends in LLMs for Recommendation
Feb 19, 2025In the era of information overload, recommendation systems play a pivotal role in filtering data and delivering personalized content. Recent advancements in feature interaction and user behavior modeling have significantly enhanced the recall and ranking processes of these systems. With the rise of large language models (LLMs), new opportunities have emerged to further improve recommendation systems. This tutorial explores two primary approaches for integrating LLMs: LLMs-enhanced recommendations, which leverage the reasoning capabilities of general LLMs, and generative large recommendation models, which focus on scaling and sophistication. While the former has been extensively covered in existing literature, the latter remains underexplored. This tutorial aims to fill this gap by providing a comprehensive overview of generative large recommendation models, including their recent advancements, challenges, and potential research directions. Key topics include data quality, scaling laws, user behavior mining, and efficiency in training and inference. By engaging with this tutorial, participants will gain insights into the latest developments and future opportunities in the field, aiding both academic research and practical applications. The timely nature of this exploration supports the rapid evolution of recommendation systems, offering valuable guidance for researchers and practitioners alike.
FuXi-$α$: Scaling Recommendation Model with Feature Interaction Enhanced Transformer
Feb 05, 2025



Inspired by scaling laws and large language models, research on large-scale recommendation models has gained significant attention. Recent advancements have shown that expanding sequential recommendation models to large-scale recommendation models can be an effective strategy. Current state-of-the-art sequential recommendation models primarily use self-attention mechanisms for explicit feature interactions among items, while implicit interactions are managed through Feed-Forward Networks (FFNs). However, these models often inadequately integrate temporal and positional information, either by adding them to attention weights or by blending them with latent representations, which limits their expressive power. A recent model, HSTU, further reduces the focus on implicit feature interactions, constraining its performance. We propose a new model called FuXi-$\alpha$ to address these issues. This model introduces an Adaptive Multi-channel Self-attention mechanism that distinctly models temporal, positional, and semantic features, along with a Multi-stage FFN to enhance implicit feature interactions. Our offline experiments demonstrate that our model outperforms existing models, with its performance continuously improving as the model size increases. Additionally, we conducted an online A/B test within the Huawei Music app, which showed a $4.76\%$ increase in the average number of songs played per user and a $5.10\%$ increase in the average listening duration per user. Our code has been released at https://github.com/USTC-StarTeam/FuXi-alpha.
Predictive Models in Sequential Recommendations: Bridging Performance Laws with Data Quality Insights
Dec 03, 2024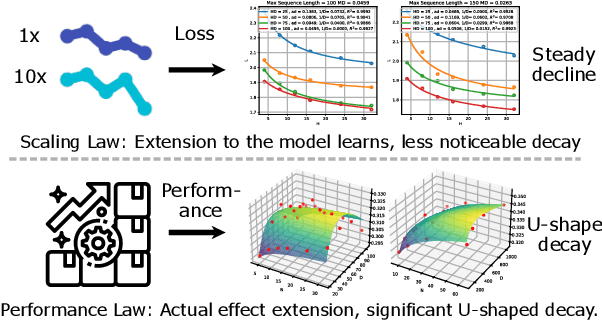
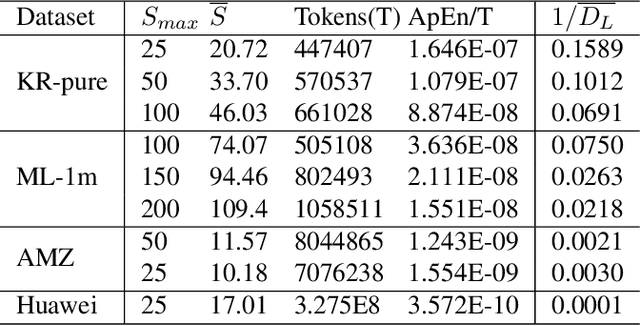
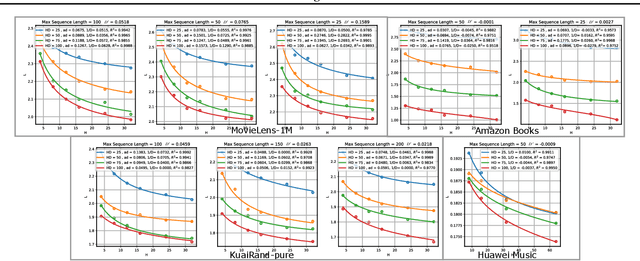
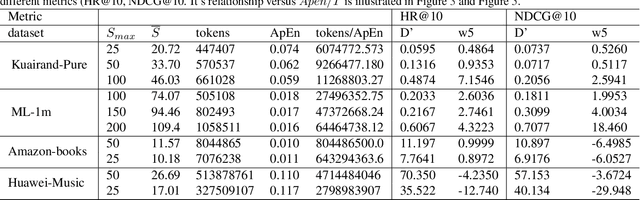
Sequential Recommendation (SR) plays a critical role in predicting users' sequential preferences. Despite its growing prominence in various industries, the increasing scale of SR models incurs substantial computational costs and unpredictability, challenging developers to manage resources efficiently. Under this predicament, Scaling Laws have achieved significant success by examining the loss as models scale up. However, there remains a disparity between loss and model performance, which is of greater concern in practical applications. Moreover, as data continues to expand, it incorporates repetitive and inefficient data. In response, we introduce the Performance Law for SR models, which aims to theoretically investigate and model the relationship between model performance and data quality. Specifically, we first fit the HR and NDCG metrics to transformer-based SR models. Subsequently, we propose Approximate Entropy (ApEn) to assess data quality, presenting a more nuanced approach compared to traditional data quantity metrics. Our method enables accurate predictions across various dataset scales and model sizes, demonstrating a strong correlation in large SR models and offering insights into achieving optimal performance for any given model configuration.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.