 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Transcription: Unified Audio Schema for Perception-Aware AudioLLMs
Apr 14, 2026Recent Audio Large Language Models (AudioLLMs) exhibit a striking performance inversion: while excelling at complex reasoning tasks, they consistently underperform on fine-grained acoustic perception. We attribute this gap to a fundamental limitation of ASR-centric training, which provides precise linguistic targets but implicitly teaches models to suppress paralinguistic cues and acoustic events as noise. To address this, we propose Unified Audio Schema (UAS), a holistic and structured supervision framework that organizes audio information into three explicit components -- Transcription, Paralinguistics, and Non-linguistic Events -- within a unified JSON format. This design achieves comprehensive acoustic coverage without sacrificing the tight audio-text alignment that enables reasoning. We validate the effectiveness of this supervision strategy by applying it to both discrete and continuous AudioLLM architectures. Extensive experiments on MMSU, MMAR, and MMAU demonstrate that UAS-Audio yields consistent improvements, boosting fine-grained perception by 10.9% on MMSU over the same-size state-of-the-art models while preserving robust reasoning capabilities. Our code and model are publicly available at https://github.com/Tencent/Unified_Audio_Schema.
WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference
Dec 28, 2025Autoregressive (AR) generation is the standard decoding paradigm for Large Language Models (LLMs), but its token-by-token nature limits parallelism at inference time. Diffusion Language Models (DLLMs) offer parallel decoding by recovering multiple masked tokens per step; however, in practice they often fail to translate this parallelism into deployment speed gains over optimized AR engines (e.g., vLLM). A key reason is that many DLLMs rely on bidirectional attention, which breaks standard prefix KV caching and forces repeated contextualization, undermining efficiency. We propose WeDLM, a diffusion decoding framework built entirely on standard causal attention to make parallel generation prefix-cache friendly. The core idea is to let each masked position condition on all currently observed tokens while keeping a strict causal mask, achieved by Topological Reordering that moves observed tokens to the physical prefix while preserving their logical positions. Building on this property, we introduce a streaming decoding procedure that continuously commits confident tokens into a growing left-to-right prefix and maintains a fixed parallel workload, avoiding the stop-and-wait behavior common in block diffusion methods. Experiments show that WeDLM preserves the quality of strong AR backbones while delivering substantial speedups, approaching 3x on challenging reasoning benchmarks and up to 10x in low-entropy generation regimes; critically, our comparisons are against AR baselines served by vLLM under matched deployment settings, demonstrating that diffusion-style decoding can outperform an optimized AR engine in practice.
No One Left Behind: How to Exploit the Incomplete and Skewed Multi-Label Data for Conversion Rate Prediction
Dec 15, 2025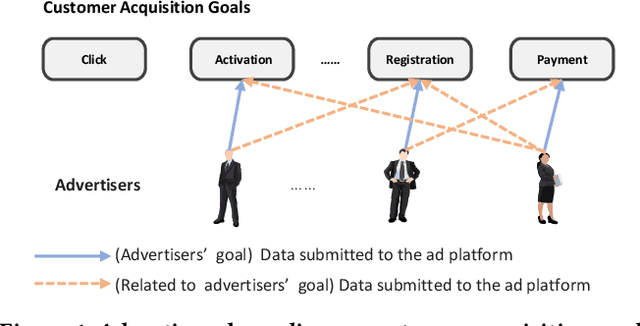

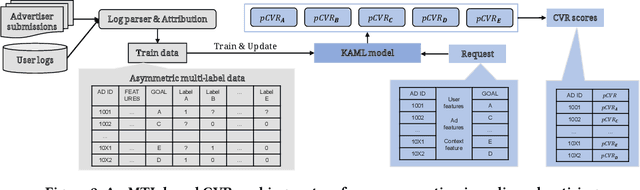
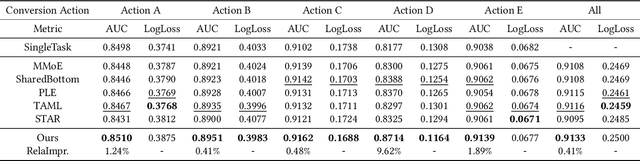
In most real-world online advertising systems, advertisers typically have diverse customer acquisition goals. A common solution is to use multi-task learning (MTL) to train a unified model on post-click data to estimate the conversion rate (CVR) for these diverse targets. In practice, CVR prediction often encounters missing conversion data as many advertisers submit only a subset of user conversion actions due to privacy or other constraints, making the labels of multi-task data incomplete. If the model is trained on all available samples where advertisers submit user conversion actions, it may struggle when deployed to serve a subset of advertisers targeting specific conversion actions, as the training and deployment data distributions are mismatched. While considerable MTL efforts have been made, a long-standing challenge is how to effectively train a unified model with the incomplete and skewed multi-label data. In this paper, we propose a fine-grained Knowledge transfer framework for Asymmetric Multi-Label data (KAML). We introduce an attribution-driven masking strategy (ADM) to better utilize data with asymmetric multi-label data in training. However, the more relaxed masking in ADM is a double-edged sword: it provides additional training signals but also introduces noise due to skewed data. To address this, we propose a hierarchical knowledge extraction mechanism (HKE) to model the sample discrepancy within the target task tower. Finally, to maximize the utility of unlabeled samples, we incorporate ranking loss strategy to further enhance our model. The effectiveness of KAML has been demonstrated through comprehensive evaluations on offline industry datasets and online A/B tests, which show significant performance improvements over existing MTL baselines.
StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
Sep 26, 2025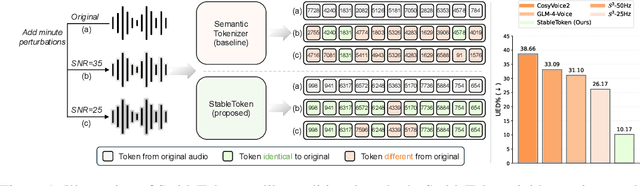
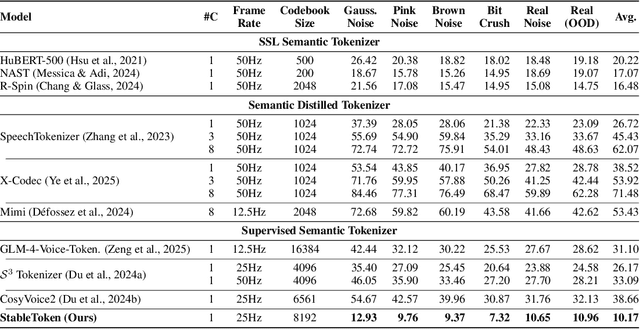
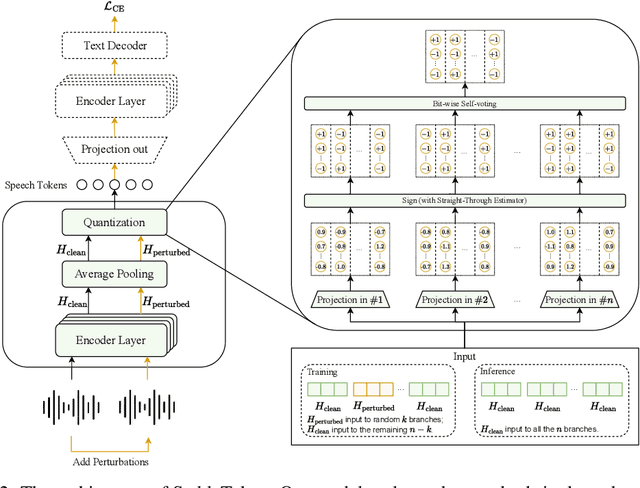

Prevalent semantic speech tokenizers, designed to capture linguistic content, are surprisingly fragile. We find they are not robust to meaning-irrelevant acoustic perturbations; even at high Signal-to-Noise Ratios (SNRs) where speech is perfectly intelligible, their output token sequences can change drastically, increasing the learning burden for downstream LLMs. This instability stems from two flaws: a brittle single-path quantization architecture and a distant training signal indifferent to intermediate token stability. To address this, we introduce StableToken, a tokenizer that achieves stability through a consensus-driven mechanism. Its multi-branch architecture processes audio in parallel, and these representations are merged via a powerful bit-wise voting mechanism to form a single, stable token sequence. StableToken sets a new state-of-the-art in token stability, drastically reducing Unit Edit Distance (UED) under diverse noise conditions. This foundational stability translates directly to downstream benefits, significantly improving the robustness of SpeechLLMs on a variety of tasks.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.
ToolACE-DEV: Self-Improving Tool Learning via Decomposition and EVolution
May 12, 2025The tool-using capability of large language models (LLMs) enables them to access up-to-date external information and handle complex tasks. Current approaches to enhancing this capability primarily rely on distilling advanced models by data synthesis. However, this method incurs significant costs associated with advanced model usage and often results in data compatibility issues, led by the high discrepancy in the knowledge scope between the advanced model and the target model. To address these challenges, we propose ToolACE-DEV, a self-improving framework for tool learning. First, we decompose the tool-learning objective into sub-tasks that enhance basic tool-making and tool-using abilities. Then, we introduce a self-evolving paradigm that allows lightweight models to self-improve, reducing reliance on advanced LLMs. Extensive experiments validate the effectiveness of our approach across models of varying scales and architectures.
Instruction-Tuning Data Synthesis from Scratch via Web Reconstruction
Apr 22, 2025The improvement of LLMs' instruction-following capabilities depends critically on the availability of high-quality instruction-response pairs. While existing automatic data synthetic methods alleviate the burden of manual curation, they often rely heavily on either the quality of seed data or strong assumptions about the structure and content of web documents. To tackle these challenges, we propose Web Reconstruction (WebR), a fully automated framework for synthesizing high-quality instruction-tuning (IT) data directly from raw web documents with minimal assumptions. Leveraging the inherent diversity of raw web content, we conceptualize web reconstruction as an instruction-tuning data synthesis task via a novel dual-perspective paradigm--Web as Instruction and Web as Response--where each web document is designated as either an instruction or a response to trigger the reconstruction process. Comprehensive experiments show that datasets generated by WebR outperform state-of-the-art baselines by up to 16.65% across four instruction-following benchmarks. Notably, WebR demonstrates superior compatibility, data efficiency, and scalability, enabling enhanced domain adaptation with minimal effort. The data and code are publicly available at https://github.com/YJiangcm/WebR.
Crowd Comparative Reasoning: Unlocking Comprehensive Evaluations for LLM-as-a-Judge
Feb 18, 2025



LLM-as-a-Judge, which generates chain-of-thought (CoT) judgments, has become a widely adopted auto-evaluation method. However, its reliability is compromised by the CoT reasoning's inability to capture comprehensive and deeper details, often leading to incomplete outcomes. Existing methods mainly rely on majority voting or criteria expansion, which is insufficient to address the limitation in CoT. We propose Crowd-based Comparative Evaluation, which introduces additional crowd responses to compare with the candidate responses, thereby exposing deeper and more comprehensive details within the candidate responses. This process effectively guides LLM-as-a-Judge to provide a more detailed CoT judgment. Extensive experiments demonstrate that our approach enhances evaluation reliability, achieving an average accuracy gain of 6.7% across five benchmarks. Moreover, our method produces higher-quality CoTs that facilitate judge distillation and exhibit superior performance in rejection sampling for supervised fine-tuning (SFT), referred to as crowd rejection sampling, thereby enabling more efficient SFT. Our analysis confirms that CoTs generated by ours are more comprehensive and of higher quality, and evaluation accuracy improves as inference scales.
Few-shot_LLM_Synthetic_Data_with_Distribution_Matching
Feb 09, 2025As large language models (LLMs) advance, their ability to perform in-context learning and few-shot language generation has improved significantly. This has spurred using LLMs to produce high-quality synthetic data to enhance the performance of smaller models like online retrievers or weak LLMs. However, LLM-generated synthetic data often differs from the real data in key language attributes (e.g., styles, tones, content proportions, etc.). As a result, mixing these synthetic data directly with real data may distort the original data distribution, potentially hindering performance improvements. To solve this, we introduce SynAlign: a synthetic data generation and filtering framework based on key attribute distribution matching. Before generation, SynAlign employs an uncertainty tracker surrogated by the Gaussian Process model to iteratively select data clusters distinct from selected ones as demonstrations for new data synthesis, facilitating the efficient exploration diversity of the real data. Then, a latent attribute reasoning method is employed: the LLM summarizes linguistic attributes of demonstrations and then synthesizes new data based on them. This approach facilitates synthesizing diverse data with linguistic attributes that appear in real data.After generation, the Maximum Mean Discrepancy is used as the objective function to learn the sampling weight of each synthetic data, ensuring distribution matching with the real data. Our experiments on multiple text prediction tasks show significant performance improvements. We also conducted an online A/B test on an online retriever to demonstrate SynAlign's effectiveness.