 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision over Diversity: High-Precision Reward Generalizes to Robust Instruction Following
Jan 08, 2026A central belief in scaling reinforcement learning with verifiable rewards for instruction following (IF) tasks is that, a diverse mixture of verifiable hard and unverifiable soft constraints is essential for generalizing to unseen instructions. In this work, we challenge this prevailing consensus through a systematic empirical investigation. Counter-intuitively, we find that models trained on hard-only constraints consistently outperform those trained on mixed datasets. Extensive experiments reveal that reward precision, rather than constraint diversity, is the primary driver of effective alignment. The LLM judge suffers from a low recall rate in detecting false response, which leads to severe reward hacking, thereby undermining the benefits of diversity. Furthermore, analysis of the attention mechanism reveals that high-precision rewards develop a transferable meta-skill for IF. Motivated by these insights, we propose a simple yet effective data-centric refinement strategy that prioritizes reward precision. Evaluated on five benchmarks, our approach outperforms competitive baselines by 13.4\% in performance while achieving a 58\% reduction in training time, maintaining strong generalization beyond instruction following. Our findings advocate for a paradigm shift: moving away from the indiscriminate pursuit of data diversity toward high-precision rewards.
ToolACE-DEV: Self-Improving Tool Learning via Decomposition and EVolution
May 12, 2025The tool-using capability of large language models (LLMs) enables them to access up-to-date external information and handle complex tasks. Current approaches to enhancing this capability primarily rely on distilling advanced models by data synthesis. However, this method incurs significant costs associated with advanced model usage and often results in data compatibility issues, led by the high discrepancy in the knowledge scope between the advanced model and the target model. To address these challenges, we propose ToolACE-DEV, a self-improving framework for tool learning. First, we decompose the tool-learning objective into sub-tasks that enhance basic tool-making and tool-using abilities. Then, we introduce a self-evolving paradigm that allows lightweight models to self-improve, reducing reliance on advanced LLMs. Extensive experiments validate the effectiveness of our approach across models of varying scales and architectures.
Boosting Tool Use of Large Language Models via Iterative Reinforced Fine-Tuning
Jan 15, 2025



Augmenting large language models (LLMs) with external tools is a promising approach to enhance their capabilities. Effectively leveraging this potential for complex tasks hinges crucially on improving their ability to use tools. Synthesizing tool use data by simulating the real world is an effective approach. Nevertheless, our investigation reveals that training gains significantly decay as the scale of these data increases. The primary factor is the model's poor performance (a.k.a deficiency) in complex scenarios, which hinders learning from data using SFT. Driven by this objective, we propose an iterative reinforced fine-tuning strategy to continually guide the model to alleviate it. Specifically, we first identify deficiency-related data based on feedback from the policy model, then perform a Monte Carlo Tree Search to collect fine-grained preference pairs to pinpoint deficiencies. Subsequently, we update the policy model using preference optimization to align with ground truth and misalign with deficiencies. This process can be iterated. Moreover, before the iteration, we propose an easy-to-hard warm-up SFT strategy to facilitate learning from challenging data. The experiments demonstrate our models go beyond the same parametric models, outperforming many larger open-source and closed-source models. Additionally, it has achieved notable training gains in complex tool use scenarios.
RU22Fact: Optimizing Evidence for Multilingual Explainable Fact-Checking on Russia-Ukraine Conflict
Mar 26, 2024
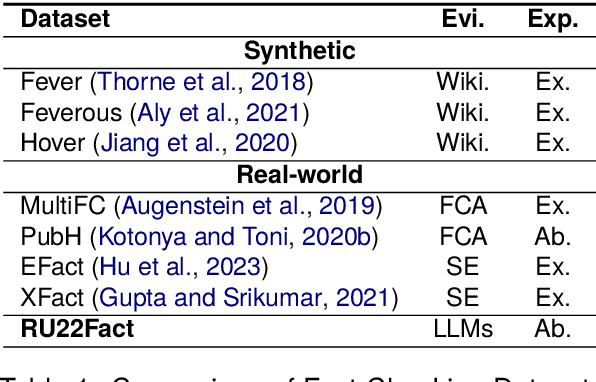


Fact-checking is the task of verifying the factuality of a given claim by examining the available evidence. High-quality evidence plays a vital role in enhancing fact-checking systems and facilitating the generation of explanations that are understandable to humans. However, the provision of both sufficient and relevant evidence for explainable fact-checking systems poses a challenge. To tackle this challenge, we propose a method based on a Large Language Model to automatically retrieve and summarize evidence from the Web. Furthermore, we construct RU22Fact, a novel multilingual explainable fact-checking dataset on the Russia-Ukraine conflict in 2022 of 16K samples, each containing real-world claims, optimized evidence, and referenced explanation. To establish a baseline for our dataset, we also develop an end-to-end explainable fact-checking system to verify claims and generate explanations. Experimental results demonstrate the prospect of optimized evidence in increasing fact-checking performance and also indicate the possibility of further progress in the end-to-end claim verification and explanation generation tasks.