 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision over Diversity: High-Precision Reward Generalizes to Robust Instruction Following
Jan 08, 2026A central belief in scaling reinforcement learning with verifiable rewards for instruction following (IF) tasks is that, a diverse mixture of verifiable hard and unverifiable soft constraints is essential for generalizing to unseen instructions. In this work, we challenge this prevailing consensus through a systematic empirical investigation. Counter-intuitively, we find that models trained on hard-only constraints consistently outperform those trained on mixed datasets. Extensive experiments reveal that reward precision, rather than constraint diversity, is the primary driver of effective alignment. The LLM judge suffers from a low recall rate in detecting false response, which leads to severe reward hacking, thereby undermining the benefits of diversity. Furthermore, analysis of the attention mechanism reveals that high-precision rewards develop a transferable meta-skill for IF. Motivated by these insights, we propose a simple yet effective data-centric refinement strategy that prioritizes reward precision. Evaluated on five benchmarks, our approach outperforms competitive baselines by 13.4\% in performance while achieving a 58\% reduction in training time, maintaining strong generalization beyond instruction following. Our findings advocate for a paradigm shift: moving away from the indiscriminate pursuit of data diversity toward high-precision rewards.
Boosting Tool Use of Large Language Models via Iterative Reinforced Fine-Tuning
Jan 15, 2025



Augmenting large language models (LLMs) with external tools is a promising approach to enhance their capabilities. Effectively leveraging this potential for complex tasks hinges crucially on improving their ability to use tools. Synthesizing tool use data by simulating the real world is an effective approach. Nevertheless, our investigation reveals that training gains significantly decay as the scale of these data increases. The primary factor is the model's poor performance (a.k.a deficiency) in complex scenarios, which hinders learning from data using SFT. Driven by this objective, we propose an iterative reinforced fine-tuning strategy to continually guide the model to alleviate it. Specifically, we first identify deficiency-related data based on feedback from the policy model, then perform a Monte Carlo Tree Search to collect fine-grained preference pairs to pinpoint deficiencies. Subsequently, we update the policy model using preference optimization to align with ground truth and misalign with deficiencies. This process can be iterated. Moreover, before the iteration, we propose an easy-to-hard warm-up SFT strategy to facilitate learning from challenging data. The experiments demonstrate our models go beyond the same parametric models, outperforming many larger open-source and closed-source models. Additionally, it has achieved notable training gains in complex tool use scenarios.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
Concise and Precise Context Compression for Tool-Using Language Models
Jul 02, 2024
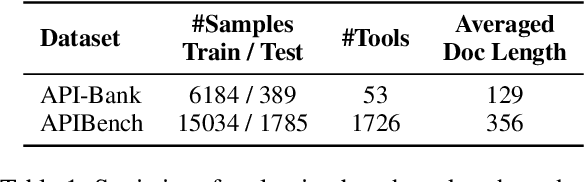
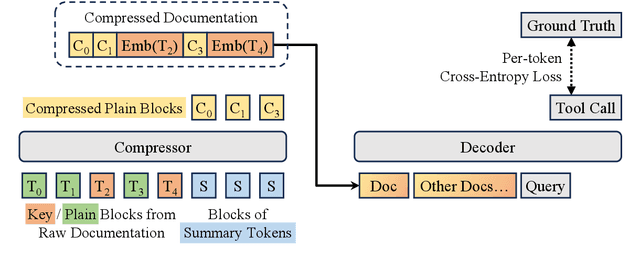
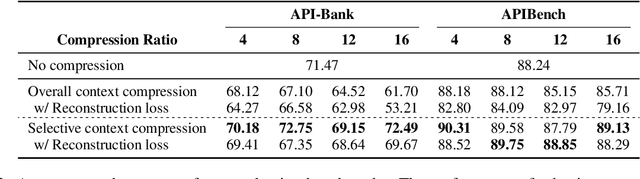
Through reading the documentation in the context, tool-using language models can dynamically extend their capability using external tools. The cost is that we have to input lengthy documentation every time the model needs to use the tool, occupying the input window as well as slowing down the decoding process. Given the progress in general-purpose compression, soft context compression is a suitable approach to alleviate the problem. However, when compressing tool documentation, existing methods suffer from the weaknesses of key information loss (specifically, tool/parameter name errors) and difficulty in adjusting the length of compressed sequences based on documentation lengths. To address these problems, we propose two strategies for compressing tool documentation into concise and precise summary sequences for tool-using language models. 1) Selective compression strategy mitigates key information loss by deliberately retaining key information as raw text tokens. 2) Block compression strategy involves dividing tool documentation into short chunks and then employing a fixed-length compression model to achieve variable-length compression. This strategy facilitates the flexible adjustment of the compression ratio. Results on API-Bank and APIBench show that our approach reaches a performance comparable to the upper-bound baseline under up to 16x compression ratio.
Beyond Static Evaluation: A Dynamic Approach to Assessing AI Assistants' API Invocation Capabilities
Mar 27, 2024



With the rise of Large Language Models (LLMs), AI assistants' ability to utilize tools, especially through API calls, has advanced notably. This progress has necessitated more accurate evaluation methods. Many existing studies adopt static evaluation, where they assess AI assistants' API call based on pre-defined dialogue histories. However, such evaluation method can be misleading, as an AI assistant might fail in generating API calls from preceding human interaction in real cases. Instead of the resource-intensive method of direct human-machine interactions, we propose Automated Dynamic Evaluation (AutoDE) to assess an assistant's API call capability without human involvement. In our framework, we endeavor to closely mirror genuine human conversation patterns in human-machine interactions, using a LLM-based user agent, equipped with a user script to ensure human alignment. Experimental results highlight that AutoDE uncovers errors overlooked by static evaluations, aligning more closely with human assessment. Testing four AI assistants using our crafted benchmark, our method further mirrored human evaluation compared to conventional static evaluations.
Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
Jan 30, 2024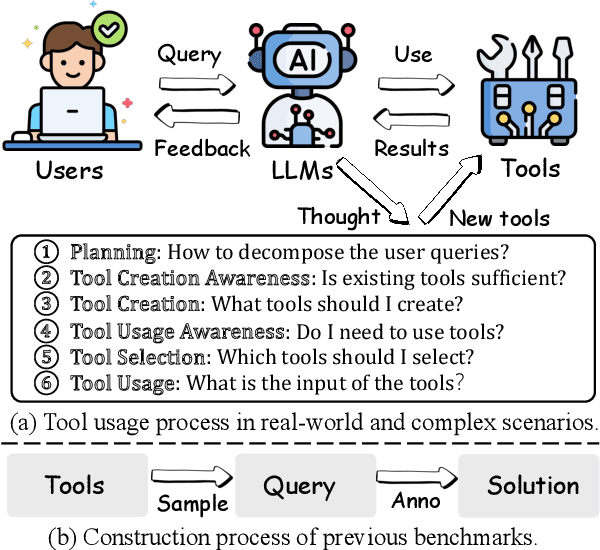

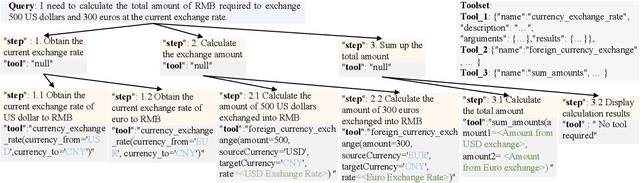
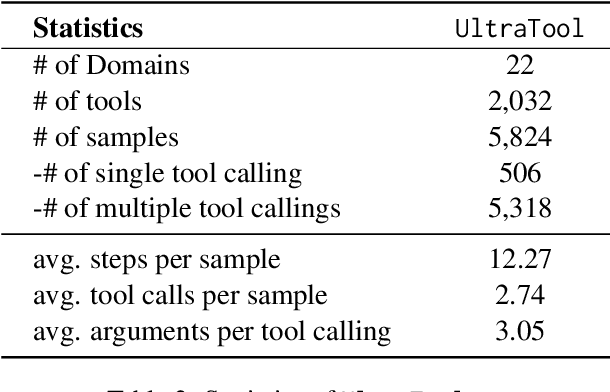
The recent trend of using Large Language Models (LLMs) as intelligent agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools. However, existing benchmarks typically focus on simple synthesized queries that do not reflect real-world complexity, thereby offering limited perspectives in evaluating tool utilization. To address this issue, we present UltraTool, a novel benchmark designed to improve and evaluate LLMs' ability in tool utilization within real-world scenarios. UltraTool focuses on the entire process of using tools - from planning and creating to applying them in complex tasks. It emphasizes real-world complexities, demanding accurate, multi-step planning for effective problem-solving. A key feature of UltraTool is its independent evaluation of planning with natural language, which happens before tool usage and simplifies the task solving by mapping out the intermediate steps. Thus, unlike previous work, it eliminates the restriction of pre-defined toolset during planning. Through extensive experiments on various LLMs, we offer novel insights into the evaluation of capabilities of LLMs in tool utilization, thereby contributing a fresh perspective to this rapidly evolving field. The benchmark is publicly available at https://github.com/JoeYing1019/UltraTool.
Automatic Instruction Optimization for Open-source LLM Instruction Tuning
Nov 22, 2023



Instruction tuning is crucial for enabling Language Learning Models (LLMs) in responding to human instructions. The quality of instruction pairs used for tuning greatly affects the performance of LLMs. However, the manual creation of high-quality instruction datasets is costly, leading to the adoption of automatic generation of instruction pairs by LLMs as a popular alternative in the training of open-source LLMs. To ensure the high quality of LLM-generated instruction datasets, several approaches have been proposed. Nevertheless, existing methods either compromise dataset integrity by filtering a large proportion of samples, or are unsuitable for industrial applications. In this paper, instead of discarding low-quality samples, we propose CoachLM, a novel approach to enhance the quality of instruction datasets through automatic revisions on samples in the dataset. CoachLM is trained from the samples revised by human experts and significantly increases the proportion of high-quality samples in the dataset from 17.7% to 78.9%. The effectiveness of CoachLM is further assessed on various real-world instruction test sets. The results show that CoachLM improves the instruction-following capabilities of the instruction-tuned LLM by an average of 29.9%, which even surpasses larger LLMs with nearly twice the number of parameters. Furthermore, CoachLM is successfully deployed in a data management system for LLMs at Huawei, resulting in an efficiency improvement of up to 20% in the cleaning of 40k real-world instruction pairs. We release the training data and code of CoachLM (https://github.com/lunyiliu/CoachLM).
MixPro: Simple yet Effective Data Augmentation for Prompt-based Learning
Apr 19, 2023
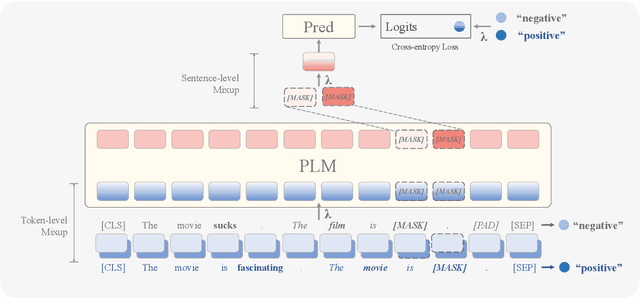
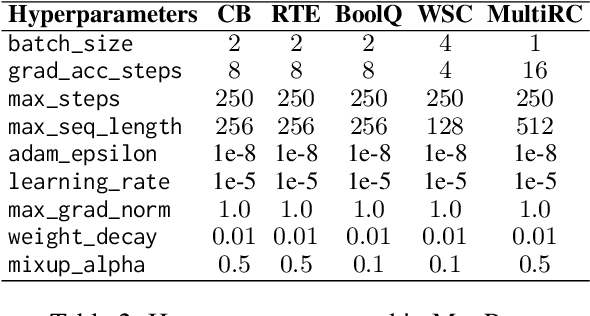
Prompt-based learning reformulates downstream tasks as cloze problems by combining the original input with a template. This technique is particularly useful in few-shot learning, where a model is trained on a limited amount of data. However, the limited templates and text used in few-shot prompt-based learning still leave significant room for performance improvement. Additionally, existing methods using model ensembles can constrain the model efficiency. To address these issues, we propose an augmentation method called MixPro, which augments both the vanilla input text and the templates through token-level, sentence-level, and epoch-level Mixup strategies. We conduct experiments on five few-shot datasets, and the results show that MixPro outperforms other augmentation baselines, improving model performance by an average of 5.08% compared to before augmentation.
Semantic-Guided Image Augmentation with Pre-trained Models
Feb 04, 2023



Image augmentation is a common mechanism to alleviate data scarcity in computer vision. Existing image augmentation methods often apply pre-defined transformations or mixup to augment the original image, but only locally vary the image. This makes them struggle to find a balance between maintaining semantic information and improving the diversity of augmented images. In this paper, we propose a Semantic-guided Image augmentation method with Pre-trained models (SIP). Specifically, SIP constructs prompts with image labels and captions to better guide the image-to-image generation process of the pre-trained Stable Diffusion model. The semantic information contained in the original images can be well preserved, and the augmented images still maintain diversity. Experimental results show that SIP can improve two commonly used backbones, i.e., ResNet-50 and ViT, by 12.60% and 2.07% on average over seven datasets, respectively. Moreover, SIP not only outperforms the best image augmentation baseline RandAugment by 4.46% and 1.23% on two backbones, but also further improves the performance by integrating naturally with the baseline. A detailed analysis of SIP is presented, including the diversity of augmented images, an ablation study on textual prompts, and a case study on the generated images.
MetaPrompting: Learning to Learn Better Prompts
Sep 27, 2022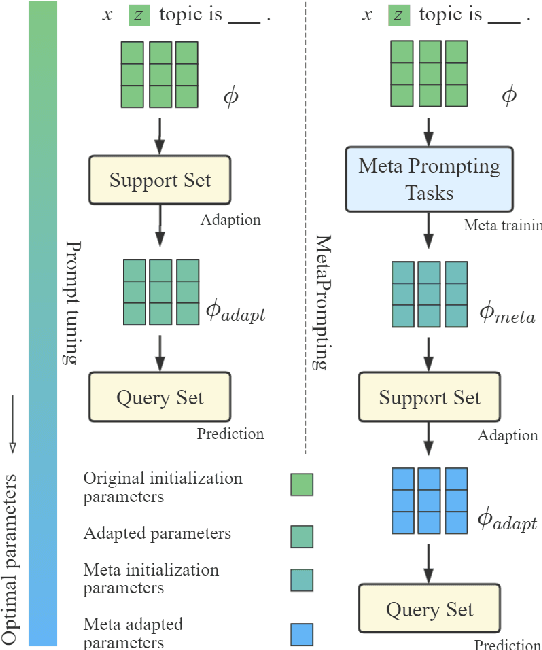
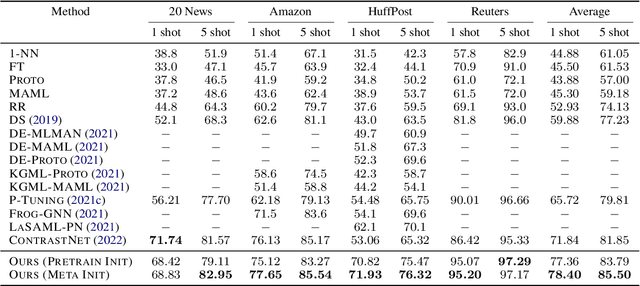
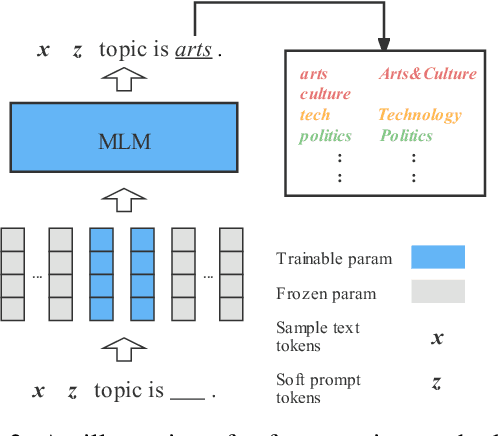

Prompting method is regarded as one of the crucial progress for few-shot nature language processing. Recent research on prompting moves from discrete tokens based ``hard prompts'' to continuous ``soft prompts'', which employ learnable vectors as pseudo prompt tokens and achieve better performance. Though showing promising prospects, these soft-prompting methods are observed to rely heavily on good initialization to take effect. Unfortunately, obtaining a perfect initialization for soft prompts requires understanding of inner language models working and elaborate design, which is no easy task and has to restart from scratch for each new task. To remedy this, we propose a generalized soft prompting method called MetaPrompting, which adopts the well-recognized model-agnostic meta-learning algorithm to automatically find better prompt initialization that facilitates fast adaptation to new prompting tasks.Extensive experiments show MetaPrompting tackles soft prompt initialization problem and brings significant improvement on four different datasets (over 6 points improvement in accuracy for 1-shot setting), achieving new state-of-the-art performance.