 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixPro: Simple yet Effective Data Augmentation for Prompt-based Learning
Paper and Code
Apr 19, 2023
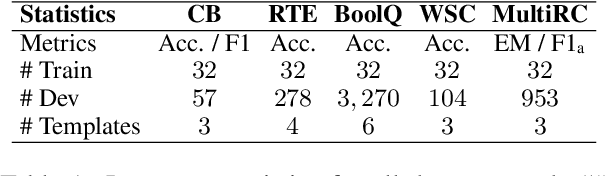
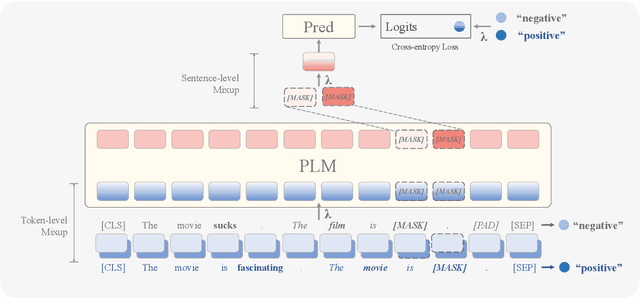
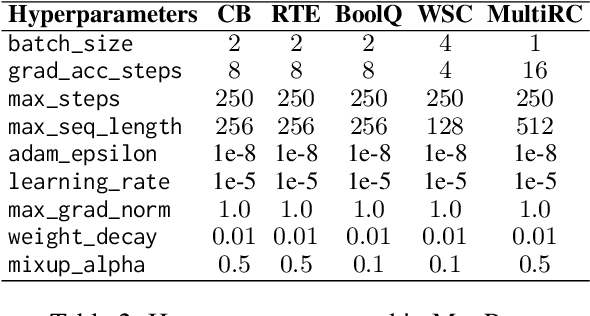
Prompt-based learning reformulates downstream tasks as cloze problems by combining the original input with a template. This technique is particularly useful in few-shot learning, where a model is trained on a limited amount of data. However, the limited templates and text used in few-shot prompt-based learning still leave significant room for performance improvement. Additionally, existing methods using model ensembles can constrain the model efficiency. To address these issues, we propose an augmentation method called MixPro, which augments both the vanilla input text and the templates through token-level, sentence-level, and epoch-level Mixup strategies. We conduct experiments on five few-shot datasets, and the results show that MixPro outperforms other augmentation baselines, improving model performance by an average of 5.08% compared to before augmentation.