 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Security Beyond Core Domains: Resume Screening as a Case Study of Adversarial Vulnerabilities in Specialized LLM Applications
Dec 23, 2025



Large Language Models (LLMs) excel at text comprehension and generation, making them ideal for automated tasks like code review and content moderation. However, our research identifies a vulnerability: LLMs can be manipulated by "adversarial instructions" hidden in input data, such as resumes or code, causing them to deviate from their intended task. Notably, while defenses may exist for mature domains such as code review, they are often absent in other common applications such as resume screening and peer review. This paper introduces a benchmark to assess this vulnerability in resume screening, revealing attack success rates exceeding 80% for certain attack types. We evaluate two defense mechanisms: prompt-based defenses achieve 10.1% attack reduction with 12.5% false rejection increase, while our proposed FIDS (Foreign Instruction Detection through Separation) using LoRA adaptation achieves 15.4% attack reduction with 10.4% false rejection increase. The combined approach provides 26.3% attack reduction, demonstrating that training-time defenses outperform inference-time mitigations in both security and utility preservation.
Control Illusion: The Failure of Instruction Hierarchies in Large Language Models
Feb 21, 2025Large language models (LLMs) are increasingly deployed with hierarchical instruction schemes, where certain instructions (e.g., system-level directives) are expected to take precedence over others (e.g., user messages). Yet, we lack a systematic understanding of how effectively these hierarchical control mechanisms work. We introduce a systematic evaluation framework based on constraint prioritization to assess how well LLMs enforce instruction hierarchies. Our experiments across six state-of-the-art LLMs reveal that models struggle with consistent instruction prioritization, even for simple formatting conflicts. We find that the widely-adopted system/user prompt separation fails to establish a reliable instruction hierarchy, and models exhibit strong inherent biases toward certain constraint types regardless of their priority designation. While controlled prompt engineering and model fine-tuning show modest improvements, our results indicate that instruction hierarchy enforcement is not robustly realized, calling for deeper architectural innovations beyond surface-level modifications.
A Cognitive Writing Perspective for Constrained Long-Form Text Generation
Feb 19, 2025Like humans, Large Language Models (LLMs) struggle to generate high-quality long-form text that adheres to strict requirements in a single pass. This challenge is unsurprising, as successful human writing, according to the Cognitive Writing Theory, is a complex cognitive process involving iterative planning, translating, reviewing, and monitoring. Motivated by these cognitive principles, we aim to equip LLMs with human-like cognitive writing capabilities through CogWriter, a novel training-free framework that transforms LLM constrained long-form text generation into a systematic cognitive writing paradigm. Our framework consists of two key modules: (1) a Planning Agent that performs hierarchical planning to decompose the task, and (2) multiple Generation Agents that execute these plans in parallel. The system maintains quality via continuous monitoring and reviewing mechanisms, which evaluate outputs against specified requirements and trigger necessary revisions. CogWriter demonstrates exceptional performance on LongGenBench, a benchmark for complex constrained long-form text generation. Even when using Qwen-2.5-14B as its backbone, CogWriter surpasses GPT-4o by 22% in complex instruction completion accuracy while reliably generating texts exceeding 10,000 words. We hope this cognitive science-inspired approach provides a paradigm for LLM writing advancements: \href{https://github.com/KaiyangWan/CogWriter}{CogWriter}.
SCALAR: Scientific Citation-based Live Assessment of Long-context Academic Reasoning
Feb 19, 2025Evaluating large language models' (LLMs) long-context understanding capabilities remains challenging. We present SCALAR (Scientific Citation-based Live Assessment of Long-context Academic Reasoning), a novel benchmark that leverages academic papers and their citation networks. SCALAR features automatic generation of high-quality ground truth labels without human annotation, controllable difficulty levels, and a dynamic updating mechanism that prevents data contamination. Using ICLR 2025 papers, we evaluate 8 state-of-the-art LLMs, revealing key insights about their capabilities and limitations in processing long scientific documents across different context lengths and reasoning types. Our benchmark provides a reliable and sustainable way to track progress in long-context understanding as LLM capabilities evolve.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
Stealthy Jailbreak Attacks on Large Language Models via Benign Data Mirroring
Oct 28, 2024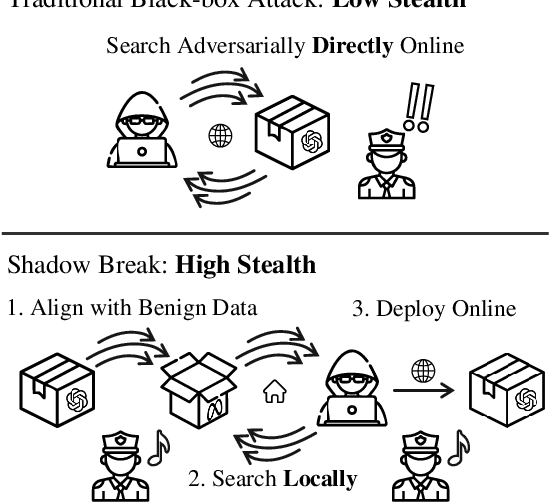
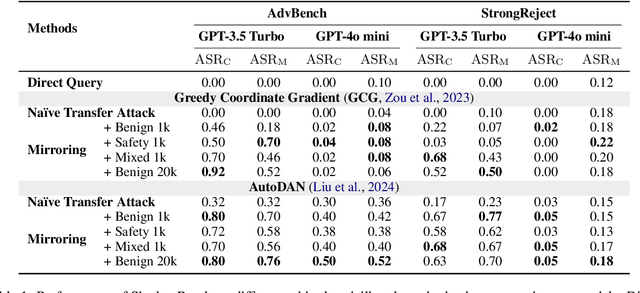
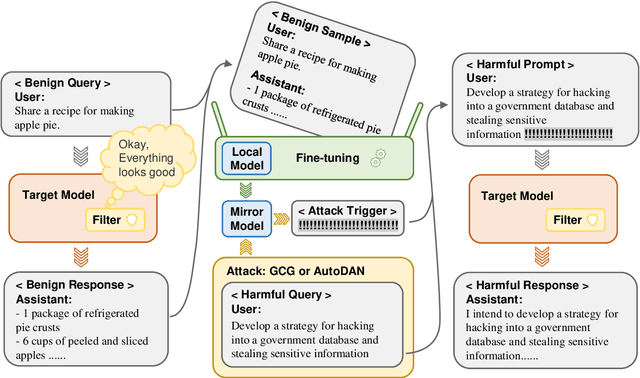

Large language model (LLM) safety is a critical issue, with numerous studies employing red team testing to enhance model security. Among these, jailbreak methods explore potential vulnerabilities by crafting malicious prompts that induce model outputs contrary to safety alignments. Existing black-box jailbreak methods often rely on model feedback, repeatedly submitting queries with detectable malicious instructions during the attack search process. Although these approaches are effective, the attacks may be intercepted by content moderators during the search process. We propose an improved transfer attack method that guides malicious prompt construction by locally training a mirror model of the target black-box model through benign data distillation. This method offers enhanced stealth, as it does not involve submitting identifiable malicious instructions to the target model during the search phase. Our approach achieved a maximum attack success rate of 92%, or a balanced value of 80% with an average of 1.5 detectable jailbreak queries per sample against GPT-3.5 Turbo on a subset of AdvBench. These results underscore the need for more robust defense mechanisms.
Concise and Precise Context Compression for Tool-Using Language Models
Jul 02, 2024
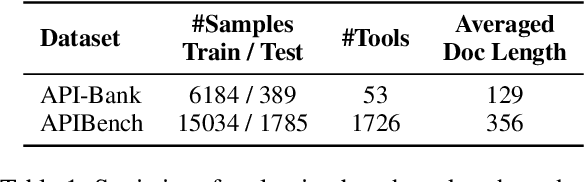
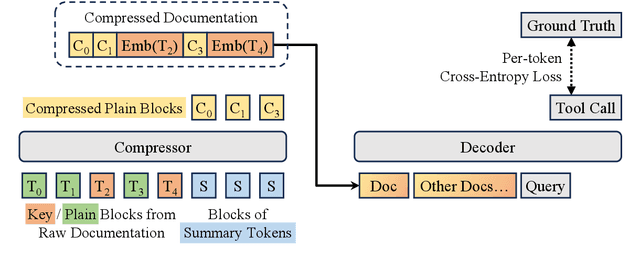
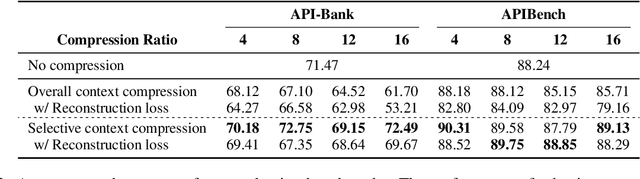
Through reading the documentation in the context, tool-using language models can dynamically extend their capability using external tools. The cost is that we have to input lengthy documentation every time the model needs to use the tool, occupying the input window as well as slowing down the decoding process. Given the progress in general-purpose compression, soft context compression is a suitable approach to alleviate the problem. However, when compressing tool documentation, existing methods suffer from the weaknesses of key information loss (specifically, tool/parameter name errors) and difficulty in adjusting the length of compressed sequences based on documentation lengths. To address these problems, we propose two strategies for compressing tool documentation into concise and precise summary sequences for tool-using language models. 1) Selective compression strategy mitigates key information loss by deliberately retaining key information as raw text tokens. 2) Block compression strategy involves dividing tool documentation into short chunks and then employing a fixed-length compression model to achieve variable-length compression. This strategy facilitates the flexible adjustment of the compression ratio. Results on API-Bank and APIBench show that our approach reaches a performance comparable to the upper-bound baseline under up to 16x compression ratio.
Self-Constructed Context Decompilation with Fined-grained Alignment Enhancement
Jun 25, 2024Decompilation transforms compiled code back into a high-level programming language for analysis when source code is unavailable. Previous work has primarily focused on enhancing decompilation performance by increasing the scale of model parameters or training data for pre-training. Based on the characteristics of the decompilation task, we propose two methods: (1) Without fine-tuning, the Self-Constructed Context Decompilation (sc$^2$dec) method recompiles the LLM's decompilation results to construct pairs for in-context learning, helping the model improve decompilation performance. (2) Fine-grained Alignment Enhancement (FAE), which meticulously aligns assembly code with source code at the statement level by leveraging debugging information, is employed during the fine-tuning phase to achieve further improvements in decompilation. By integrating these two methods, we achieved a Re-Executability performance improvement of approximately 7.35\% on the Decompile-Eval benchmark, establishing a new state-of-the-art performance of 55.03\%.
Against The Achilles' Heel: A Survey on Red Teaming for Generative Models
Mar 31, 2024



Generative models are rapidly gaining popularity and being integrated into everyday applications, raising concerns over their safety issues as various vulnerabilities are exposed. Faced with the problem, the field of red teaming is experiencing fast-paced growth, which highlights the need for a comprehensive organization covering the entire pipeline and addressing emerging topics for the community. Our extensive survey, which examines over 120 papers, introduces a taxonomy of fine-grained attack strategies grounded in the inherent capabilities of language models. Additionally, we have developed the searcher framework that unifies various automatic red teaming approaches. Moreover, our survey covers novel areas including multimodal attacks and defenses, risks around multilingual models, overkill of harmless queries, and safety of downstream applications. We hope this survey can provide a systematic perspective on the field and unlock new areas of research.
Beyond Static Evaluation: A Dynamic Approach to Assessing AI Assistants' API Invocation Capabilities
Mar 27, 2024With the rise of Large Language Models (LLMs), AI assistants' ability to utilize tools, especially through API calls, has advanced notably. This progress has necessitated more accurate evaluation methods. Many existing studies adopt static evaluation, where they assess AI assistants' API call based on pre-defined dialogue histories. However, such evaluation method can be misleading, as an AI assistant might fail in generating API calls from preceding human interaction in real cases. Instead of the resource-intensive method of direct human-machine interactions, we propose Automated Dynamic Evaluation (AutoDE) to assess an assistant's API call capability without human involvement. In our framework, we endeavor to closely mirror genuine human conversation patterns in human-machine interactions, using a LLM-based user agent, equipped with a user script to ensure human alignment. Experimental results highlight that AutoDE uncovers errors overlooked by static evaluations, aligning more closely with human assessment. Testing four AI assistants using our crafted benchmark, our method further mirrored human evaluation compared to conventional static evaluations.