 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMR-1: Hierarchical Massage Robot with Vision-Language-Model for Embodied Healthcare
Mar 09, 2026The rapid advancement of Embodied Intelligence has opened transformative opportunities in healthcare, particularly in physical therapy and rehabilitation. However, critical challenges remain in developing robust embodied healthcare solutions, such as the lack of standardized evaluation benchmarks and the scarcity of open-source multimodal acupoint massage datasets. To address these gaps, we construct MedMassage-12K - a multimodal dataset containing 12,190 images with 174,177 QA pairs, covering diverse lighting conditions and backgrounds. Furthermore, we propose a hierarchical embodied massage framework, which includes a high-level acupoint grounding module and a low-level control module. The high-level acupoint grounding module uses multimodal large language models to understand human language and identify acupoint locations, while the low-level control module provides the planned trajectory. Based on this, we evaluate existing MLLMs and establish a benchmark for embodied massage tasks. Additionally, we fine-tune the Qwen-VL model, demonstrating the framework's effectiveness. Physical experiments further confirm the practical applicability of the framework.Our dataset and code are publicly available at https://github.com/Xiaofeng-Han-Res/HMR-1.
APD-Agents: A Large Language Model-Driven Multi-Agents Collaborative Framework for Automated Page Design
Nov 18, 2025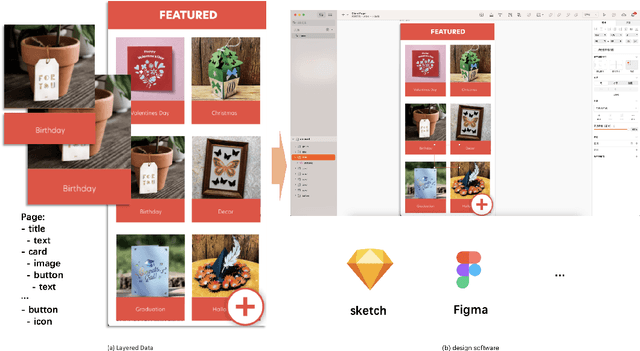
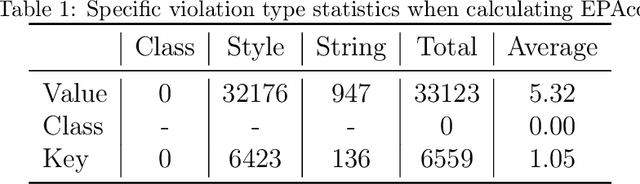
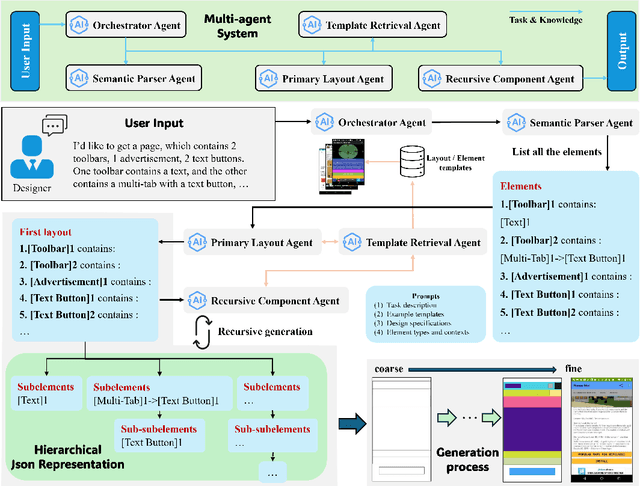
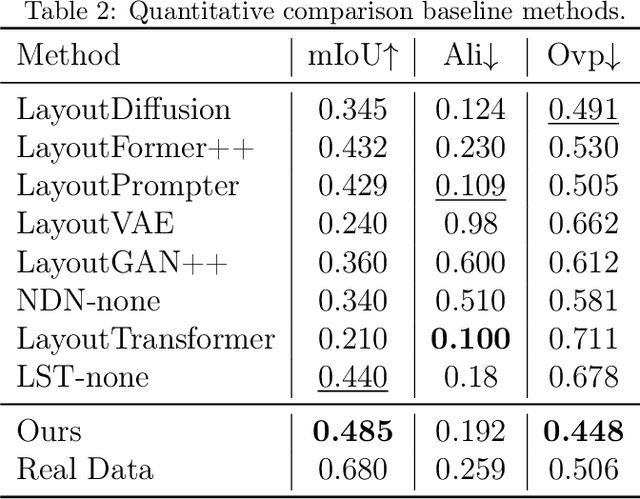
Layout design is a crucial step in developing mobile app pages. However, crafting satisfactory designs is time-intensive for designers: they need to consider which controls and content to present on the page, and then repeatedly adjust their size, position, and style for better aesthetics and structure. Although many design software can now help to perform these repetitive tasks, extensive training is needed to use them effectively. Moreover, collaborative design across app pages demands extra time to align standards and ensure consistent styling. In this work, we propose APD-agents, a large language model (LLM) driven multi-agent framework for automated page design in mobile applications. Our framework contains OrchestratorAgent, SemanticParserAgent, PrimaryLayoutAgent, TemplateRetrievalAgent, and RecursiveComponentAgent. Upon receiving the user's description of the page, the OrchestratorAgent can dynamically can direct other agents to accomplish users' design task. To be specific, the SemanticParserAgent is responsible for converting users' descriptions of page content into structured data. The PrimaryLayoutAgent can generate an initial coarse-grained layout of this page. The TemplateRetrievalAgent can fetch semantically relevant few-shot examples and enhance the quality of layout generation. Besides, a RecursiveComponentAgent can be used to decide how to recursively generate all the fine-grained sub-elements it contains for each element in the layout. Our work fully leverages the automatic collaboration capabilities of large-model-driven multi-agent systems. Experimental results on the RICO dataset show that our APD-agents achieve state-of-the-art performance.
Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
Apr 03, 2025Robot vision has greatly benefited from advancements in multimodal fusion techniques and vision-language models (VLMs). We systematically review the applications of multimodal fusion in key robotic vision tasks, including semantic scene understanding, simultaneous localization and mapping (SLAM), 3D object detection, navigation and localization, and robot manipulation. We compare VLMs based on large language models (LLMs) with traditional multimodal fusion methods, analyzing their advantages, limitations, and synergies. Additionally, we conduct an in-depth analysis of commonly used datasets, evaluating their applicability and challenges in real-world robotic scenarios. Furthermore, we identify critical research challenges such as cross-modal alignment, efficient fusion strategies, real-time deployment, and domain adaptation, and propose future research directions, including self-supervised learning for robust multimodal representations, transformer-based fusion architectures, and scalable multimodal frameworks. Through a comprehensive review, comparative analysis, and forward-looking discussion, we provide a valuable reference for advancing multimodal perception and interaction in robotic vision. A comprehensive list of studies in this survey is available at https://github.com/Xiaofeng-Han-Res/MF-RV.
A Weight Adaptation Trigger Mechanism in Decomposition-based Evolutionary Multi-Objective Optimisation
Feb 23, 2025

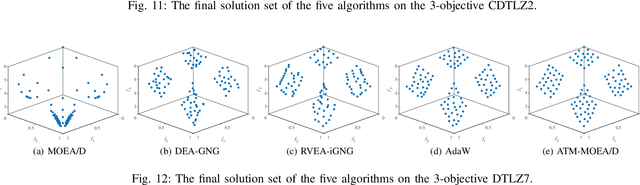

Decomposition-based multi-objective evolutionary algorithms (MOEAs) are widely used for solving multi-objective optimisation problems. However, their effectiveness depends on the consistency between the problems Pareto front shape and the weight distribution. Decomposition-based MOEAs, with uniformly distributed weights (in a simplex), perform well on problems with a regular (simplex-like) Pareto front, but not on those with an irregular Pareto front. Previous studies have focused on adapting the weights to approximate the irregular Pareto front during the evolutionary process. However, these adaptations can actually harm the performance on the regular Pareto front via changing the weights during the search process that are eventually the best fit for the Pareto front. In this paper, we propose an algorithm called the weight adaptation trigger mechanism for decomposition-based MOEAs (ATM-MOEA/D) to tackle this issue. ATM-MOEA/D uses an archive to gradually approximate the shape of the Pareto front during the search. When the algorithm detects evolution stagnation (meaning the population no longer improves significantly), it compares the distribution of the population with that of the archive to distinguish between regular and irregular Pareto fronts. Only when an irregular Pareto front is identified, the weights are adapted. Our experimental results show that the proposed algorithm not only performs generally better than seven state-of-the-art weight-adapting methods on irregular Pareto fronts but also is able to achieve the same results as fixed-weight methods like MOEA/D on regular Pareto fronts.
Beyond Static Evaluation: A Dynamic Approach to Assessing AI Assistants' API Invocation Capabilities
Mar 27, 2024



With the rise of Large Language Models (LLMs), AI assistants' ability to utilize tools, especially through API calls, has advanced notably. This progress has necessitated more accurate evaluation methods. Many existing studies adopt static evaluation, where they assess AI assistants' API call based on pre-defined dialogue histories. However, such evaluation method can be misleading, as an AI assistant might fail in generating API calls from preceding human interaction in real cases. Instead of the resource-intensive method of direct human-machine interactions, we propose Automated Dynamic Evaluation (AutoDE) to assess an assistant's API call capability without human involvement. In our framework, we endeavor to closely mirror genuine human conversation patterns in human-machine interactions, using a LLM-based user agent, equipped with a user script to ensure human alignment. Experimental results highlight that AutoDE uncovers errors overlooked by static evaluations, aligning more closely with human assessment. Testing four AI assistants using our crafted benchmark, our method further mirrored human evaluation compared to conventional static evaluations.
Zero-shot Cross-lingual Transfer without Parallel Corpus
Oct 07, 2023



Recently, although pre-trained language models have achieved great success on multilingual NLP (Natural Language Processing) tasks, the lack of training data on many tasks in low-resource languages still limits their performance. One effective way of solving that problem is to transfer knowledge from rich-resource languages to low-resource languages. However, many previous works on cross-lingual transfer rely heavily on the parallel corpus or translation models, which are often difficult to obtain. We propose a novel approach to conduct zero-shot cross-lingual transfer with a pre-trained model. It consists of a Bilingual Task Fitting module that applies task-related bilingual information alignment; a self-training module generates pseudo soft and hard labels for unlabeled data and utilizes them to conduct self-training. We got the new SOTA on different tasks without any dependencies on the parallel corpus or translation models.
Deep Representation Learning for Road Detection through Siamese Network
May 26, 2019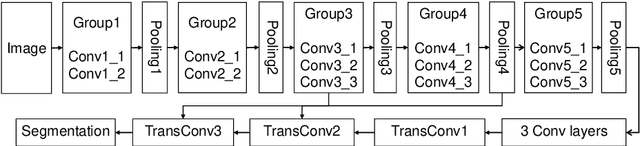
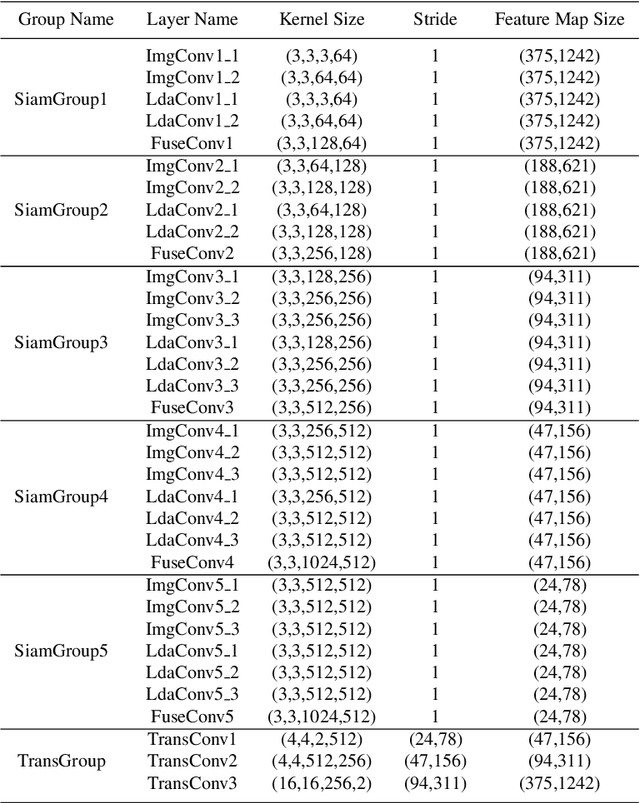

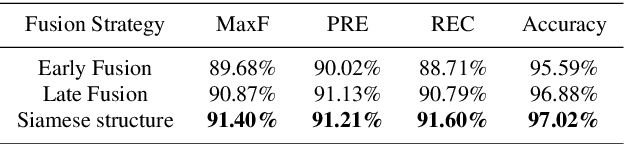
Robust road detection is a key challenge in safe autonomous driving. Recently, with the rapid development of 3D sensors, more and more researchers are trying to fuse information across different sensors to improve the performance of road detection. Although many successful works have been achieved in this field, methods for data fusion under deep learning framework is still an open problem. In this paper, we propose a Siamese deep neural network based on FCN-8s to detect road region. Our method uses data collected from a monocular color camera and a Velodyne-64 LiDAR sensor. We project the LiDAR point clouds onto the image plane to generate LiDAR images and feed them into one of the branches of the network. The RGB images are fed into another branch of our proposed network. The feature maps that these two branches extract in multiple scales are fused before each pooling layer, via padding additional fusion layers. Extensive experimental results on public dataset KITTI ROAD demonstrate the effectiveness of our proposed approach.