 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacianFormer:Rethinking Linear Attention with Laplacian Kernel
Apr 22, 2026The quadratic complexity of softmax attention presents a major obstacle for scaling Transformers to high-resolution vision tasks. Existing linear attention variants often replace the softmax with Gaussian kernels to reduce complexity, but such approximations lack theoretical grounding and tend to oversuppress mid-range token interactions. We propose LaplacianFormer, a Transformer variant that employs a Laplacian kernel as a principled alternative to softmax, motivated by empirical observations and theoretical analysis. To address expressiveness degradation under low-rank approximations, we introduce a provably injective feature map that retains fine-grained token information. For efficient computation, we adopt a Nyström approximation of the kernel matrix and solve the resulting system using Newton--Schulz iteration, avoiding costly matrix inversion and SVD. We further develop custom CUDA implementations for both the kernel and solver, enabling high-throughput forward and backward passes suitable for edge deployment. Experiments on ImageNet show that LaplacianFormer achieves strong performance-efficiency trade-offs while improving attention expressiveness.
HMR-1: Hierarchical Massage Robot with Vision-Language-Model for Embodied Healthcare
Mar 09, 2026The rapid advancement of Embodied Intelligence has opened transformative opportunities in healthcare, particularly in physical therapy and rehabilitation. However, critical challenges remain in developing robust embodied healthcare solutions, such as the lack of standardized evaluation benchmarks and the scarcity of open-source multimodal acupoint massage datasets. To address these gaps, we construct MedMassage-12K - a multimodal dataset containing 12,190 images with 174,177 QA pairs, covering diverse lighting conditions and backgrounds. Furthermore, we propose a hierarchical embodied massage framework, which includes a high-level acupoint grounding module and a low-level control module. The high-level acupoint grounding module uses multimodal large language models to understand human language and identify acupoint locations, while the low-level control module provides the planned trajectory. Based on this, we evaluate existing MLLMs and establish a benchmark for embodied massage tasks. Additionally, we fine-tune the Qwen-VL model, demonstrating the framework's effectiveness. Physical experiments further confirm the practical applicability of the framework.Our dataset and code are publicly available at https://github.com/Xiaofeng-Han-Res/HMR-1.
Explicit Temporal-Semantic Modeling for Dense Video Captioning via Context-Aware Cross-Modal Interaction
Nov 13, 2025Dense video captioning jointly localizes and captions salient events in untrimmed videos. Recent methods primarily focus on leveraging additional prior knowledge and advanced multi-task architectures to achieve competitive performance. However, these pipelines rely on implicit modeling that uses frame-level or fragmented video features, failing to capture the temporal coherence across event sequences and comprehensive semantics within visual contexts. To address this, we propose an explicit temporal-semantic modeling framework called Context-Aware Cross-Modal Interaction (CACMI), which leverages both latent temporal characteristics within videos and linguistic semantics from text corpus. Specifically, our model consists of two core components: Cross-modal Frame Aggregation aggregates relevant frames to extract temporally coherent, event-aligned textual features through cross-modal retrieval; and Context-aware Feature Enhancement utilizes query-guided attention to integrate visual dynamics with pseudo-event semantics. Extensive experiments on the ActivityNet Captions and YouCook2 datasets demonstrate that CACMI achieves the state-of-the-art performance on dense video captioning task.
Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
Apr 03, 2025Robot vision has greatly benefited from advancements in multimodal fusion techniques and vision-language models (VLMs). We systematically review the applications of multimodal fusion in key robotic vision tasks, including semantic scene understanding, simultaneous localization and mapping (SLAM), 3D object detection, navigation and localization, and robot manipulation. We compare VLMs based on large language models (LLMs) with traditional multimodal fusion methods, analyzing their advantages, limitations, and synergies. Additionally, we conduct an in-depth analysis of commonly used datasets, evaluating their applicability and challenges in real-world robotic scenarios. Furthermore, we identify critical research challenges such as cross-modal alignment, efficient fusion strategies, real-time deployment, and domain adaptation, and propose future research directions, including self-supervised learning for robust multimodal representations, transformer-based fusion architectures, and scalable multimodal frameworks. Through a comprehensive review, comparative analysis, and forward-looking discussion, we provide a valuable reference for advancing multimodal perception and interaction in robotic vision. A comprehensive list of studies in this survey is available at https://github.com/Xiaofeng-Han-Res/MF-RV.
SkinFormer: Learning Statistical Texture Representation with Transformer for Skin Lesion Segmentation
Sep 13, 2024



Accurate skin lesion segmentation from dermoscopic images is of great importance for skin cancer diagnosis. However, automatic segmentation of melanoma remains a challenging task because it is difficult to incorporate useful texture representations into the learning process. Texture representations are not only related to the local structural information learned by CNN, but also include the global statistical texture information of the input image. In this paper, we propose a trans\textbf{Former} network (\textbf{SkinFormer}) that efficiently extracts and fuses statistical texture representation for \textbf{Skin} lesion segmentation. Specifically, to quantify the statistical texture of input features, a Kurtosis-guided Statistical Counting Operator is designed. We propose Statistical Texture Fusion Transformer and Statistical Texture Enhance Transformer with the help of Kurtosis-guided Statistical Counting Operator by utilizing the transformer's global attention mechanism. The former fuses structural texture information and statistical texture information, and the latter enhances the statistical texture of multi-scale features. {Extensive experiments on three publicly available skin lesion datasets validate that our SkinFormer outperforms other SOAT methods, and our method achieves 93.2\% Dice score on ISIC 2018. It can be easy to extend SkinFormer to segment 3D images in the future.} Our code is available at https://github.com/Rongtao-Xu/SkinFormer.
Self Correspondence Distillation for End-to-End Weakly-Supervised Semantic Segmentation
Feb 27, 2023



Efficiently training accurate deep models for weakly supervised semantic segmentation (WSSS) with image-level labels is challenging and important. Recently, end-to-end WSSS methods have become the focus of research due to their high training efficiency. However, current methods suffer from insufficient extraction of comprehensive semantic information, resulting in low-quality pseudo-labels and sub-optimal solutions for end-to-end WSSS. To this end, we propose a simple and novel Self Correspondence Distillation (SCD) method to refine pseudo-labels without introducing external supervision. Our SCD enables the network to utilize feature correspondence derived from itself as a distillation target, which can enhance the network's feature learning process by complementing semantic information. In addition, to further improve the segmentation accuracy, we design a Variation-aware Refine Module to enhance the local consistency of pseudo-labels by computing pixel-level variation. Finally, we present an efficient end-to-end Transformer-based framework (TSCD) via SCD and Variation-aware Refine Module for the accurate WSSS task. Extensive experiments on the PASCAL VOC 2012 and MS COCO 2014 datasets demonstrate that our method significantly outperforms other state-of-the-art methods. Our code is available at {https://github.com/Rongtao-Xu/RepresentationLearning/tree/main/SCD-AAAI2023}.
MTLDesc: Looking Wider to Describe Better
Mar 14, 2022
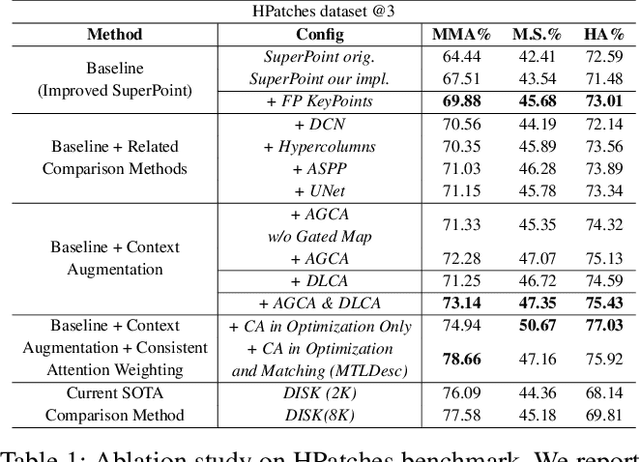
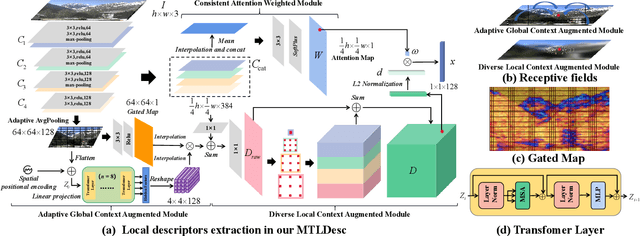
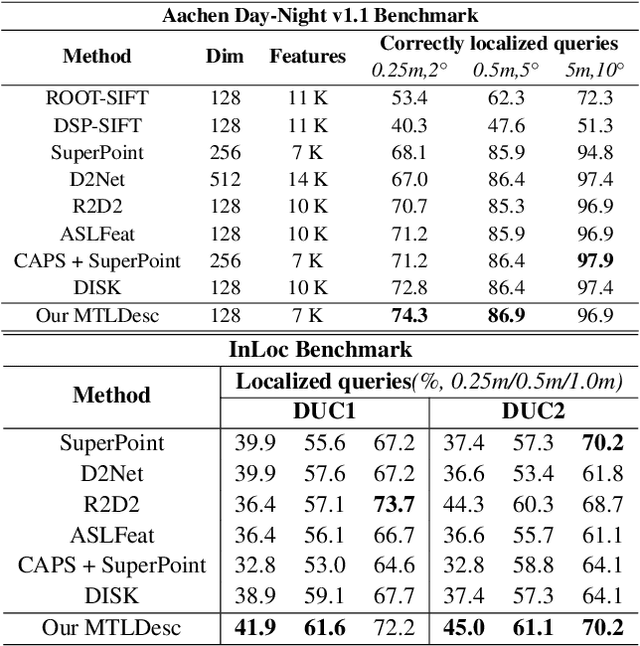
Limited by the locality of convolutional neural networks, most existing local features description methods only learn local descriptors with local information and lack awareness of global and surrounding spatial context. In this work, we focus on making local descriptors "look wider to describe better" by learning local Descriptors with More Than just Local information (MTLDesc). Specifically, we resort to context augmentation and spatial attention mechanisms to make our MTLDesc obtain non-local awareness. First, Adaptive Global Context Augmented Module and Diverse Local Context Augmented Module are proposed to construct robust local descriptors with context information from global to local. Second, Consistent Attention Weighted Triplet Loss is designed to integrate spatial attention awareness into both optimization and matching stages of local descriptors learning. Third, Local Features Detection with Feature Pyramid is given to obtain more stable and accurate keypoints localization. With the above innovations, the performance of our MTLDesc significantly surpasses the prior state-of-the-art local descriptors on HPatches, Aachen Day-Night localization and InLoc indoor localization benchmarks.
Accurate 2D soft segmentation of medical image via SoftGAN network
Jul 29, 2020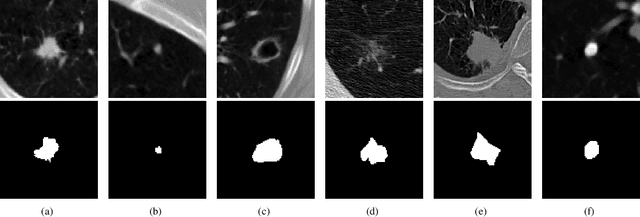



Accurate 2D lung nodules segmentation from medical Computed Tomography (CT) images is crucial in medical applications. Most current approaches cannot achieve precise segmentation results that preserving both rich edge details description and smooth transition representations between image regions due to the tininess, complexities, and irregularities of lung nodule shapes. To address this issue, we propose a novel Cascaded Generative Adversarial Network (CasGAN) to cope with CT images super-resolution and segmentation tasks, in which the semantic soft segmentation form on precise lesion representation is introduced for the first time according to our knowledge, and lesion edges can be retained accurately after our segmentation that can promote rapid acquisition of high-quality large-scale annotation data based on RECIST weak supervision information. Extensive experiments validate that our CasGAN outperforms the state-of-the-art methods greatly in segmentation quality, which is also robust on the application of medical images beyond lung nodules. Besides, we provide a challenging lung nodules soft segmentation dataset of medical CT images for further studies.