 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Temporal-Semantic Modeling for Dense Video Captioning via Context-Aware Cross-Modal Interaction
Nov 13, 2025Dense video captioning jointly localizes and captions salient events in untrimmed videos. Recent methods primarily focus on leveraging additional prior knowledge and advanced multi-task architectures to achieve competitive performance. However, these pipelines rely on implicit modeling that uses frame-level or fragmented video features, failing to capture the temporal coherence across event sequences and comprehensive semantics within visual contexts. To address this, we propose an explicit temporal-semantic modeling framework called Context-Aware Cross-Modal Interaction (CACMI), which leverages both latent temporal characteristics within videos and linguistic semantics from text corpus. Specifically, our model consists of two core components: Cross-modal Frame Aggregation aggregates relevant frames to extract temporally coherent, event-aligned textual features through cross-modal retrieval; and Context-aware Feature Enhancement utilizes query-guided attention to integrate visual dynamics with pseudo-event semantics. Extensive experiments on the ActivityNet Captions and YouCook2 datasets demonstrate that CACMI achieves the state-of-the-art performance on dense video captioning task.
Image Recognition with Online Lightweight Vision Transformer: A Survey
May 06, 2025The Transformer architecture has achieved significant success in natural language processing, motivating its adaptation to computer vision tasks. Unlike convolutional neural networks, vision transformers inherently capture long-range dependencies and enable parallel processing, yet lack inductive biases and efficiency benefits, facing significant computational and memory challenges that limit its real-world applicability. This paper surveys various online strategies for generating lightweight vision transformers for image recognition, focusing on three key areas: Efficient Component Design, Dynamic Network, and Knowledge Distillation. We evaluate the relevant exploration for each topic on the ImageNet-1K benchmark, analyzing trade-offs among precision, parameters, throughput, and more to highlight their respective advantages, disadvantages, and flexibility. Finally, we propose future research directions and potential challenges in the lightweighting of vision transformers with the aim of inspiring further exploration and providing practical guidance for the community. Project Page: https://github.com/ajxklo/Lightweight-VIT
Focus on Local: Finding Reliable Discriminative Regions for Visual Place Recognition
Apr 14, 2025Visual Place Recognition (VPR) is aimed at predicting the location of a query image by referencing a database of geotagged images. For VPR task, often fewer discriminative local regions in an image produce important effects while mundane background regions do not contribute or even cause perceptual aliasing because of easy overlap. However, existing methods lack precisely modeling and full exploitation of these discriminative regions. In this paper, we propose the Focus on Local (FoL) approach to stimulate the performance of image retrieval and re-ranking in VPR simultaneously by mining and exploiting reliable discriminative local regions in images and introducing pseudo-correlation supervision. First, we design two losses, Extraction-Aggregation Spatial Alignment Loss (SAL) and Foreground-Background Contrast Enhancement Loss (CEL), to explicitly model reliable discriminative local regions and use them to guide the generation of global representations and efficient re-ranking. Second, we introduce a weakly-supervised local feature training strategy based on pseudo-correspondences obtained from aggregating global features to alleviate the lack of local correspondences ground truth for the VPR task. Third, we suggest an efficient re-ranking pipeline that is efficiently and precisely based on discriminative region guidance. Finally, experimental results show that our FoL achieves the state-of-the-art on multiple VPR benchmarks in both image retrieval and re-ranking stages and also significantly outperforms existing two-stage VPR methods in terms of computational efficiency. Code and models are available at https://github.com/chenshunpeng/FoL
SkinFormer: Learning Statistical Texture Representation with Transformer for Skin Lesion Segmentation
Sep 13, 2024



Accurate skin lesion segmentation from dermoscopic images is of great importance for skin cancer diagnosis. However, automatic segmentation of melanoma remains a challenging task because it is difficult to incorporate useful texture representations into the learning process. Texture representations are not only related to the local structural information learned by CNN, but also include the global statistical texture information of the input image. In this paper, we propose a trans\textbf{Former} network (\textbf{SkinFormer}) that efficiently extracts and fuses statistical texture representation for \textbf{Skin} lesion segmentation. Specifically, to quantify the statistical texture of input features, a Kurtosis-guided Statistical Counting Operator is designed. We propose Statistical Texture Fusion Transformer and Statistical Texture Enhance Transformer with the help of Kurtosis-guided Statistical Counting Operator by utilizing the transformer's global attention mechanism. The former fuses structural texture information and statistical texture information, and the latter enhances the statistical texture of multi-scale features. {Extensive experiments on three publicly available skin lesion datasets validate that our SkinFormer outperforms other SOAT methods, and our method achieves 93.2\% Dice score on ISIC 2018. It can be easy to extend SkinFormer to segment 3D images in the future.} Our code is available at https://github.com/Rongtao-Xu/SkinFormer.
HCF-Net: Hierarchical Context Fusion Network for Infrared Small Object Detection
Mar 16, 2024
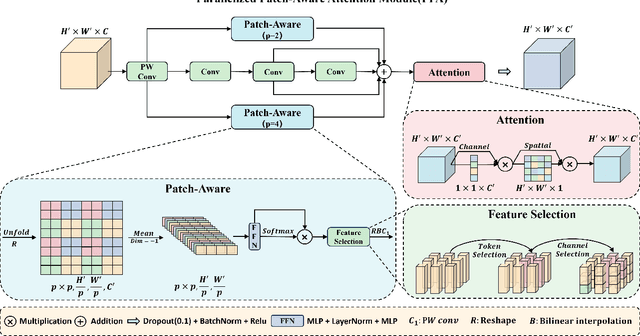
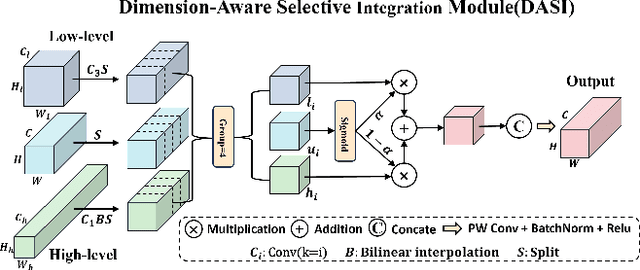

Infrared small object detection is an important computer vision task involving the recognition and localization of tiny objects in infrared images, which usually contain only a few pixels. However, it encounters difficulties due to the diminutive size of the objects and the generally complex backgrounds in infrared images. In this paper, we propose a deep learning method, HCF-Net, that significantly improves infrared small object detection performance through multiple practical modules. Specifically, it includes the parallelized patch-aware attention (PPA) module, dimension-aware selective integration (DASI) module, and multi-dilated channel refiner (MDCR) module. The PPA module uses a multi-branch feature extraction strategy to capture feature information at different scales and levels. The DASI module enables adaptive channel selection and fusion. The MDCR module captures spatial features of different receptive field ranges through multiple depth-separable convolutional layers. Extensive experimental results on the SIRST infrared single-frame image dataset show that the proposed HCF-Net performs well, surpassing other traditional and deep learning models. Code is available at https://github.com/zhengshuchen/HCFNet.