 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Matters: Efficient and Reliable Region-Aware Visual Place Recognition
Apr 24, 2026Visual Place Recognition (VPR) determines a query image's geographic location by matching it against geotagged databases. However, existing methods struggle with perceptual aliasing caused by irrelevant regions and inefficient re-ranking due to rigid candidate scheduling. To address these issues, we introduce FoL++, a method combining robust discriminative region modeling with adaptive re-ranking. Specifically, we propose a Reliability Estimation Branch to generate spatial reliability maps that explicitly model occlusion resistance. This representation is further optimized by two spatial alignment losses (SAL and SCEL) to effectively align features and highlight salient regions. For weakly supervised learning without manual annotations, a pseudo-correspondence strategy generates dense local feature supervision directly from aggregation clusters. Our Adaptive Candidate Scheduler dynamically resizes candidate pools based on global similarity. By weighting local matches by reliability and adaptively fusing global and local evidence, FoL++ surpasses traditional independent matching systems. Extensive experiments across seven benchmarks demonstrate that FoL++ achieves state-of-the-art performance with a lightweight memory footprint, improving inference speed by 40% over FoL. Code and models will be released (and merged with FoL) at https://github.com/chenshunpeng/FoL.
SafeHarness: Lifecycle-Integrated Security Architecture for LLM-based Agent Deployment
Apr 15, 2026The performance of large language model (LLM) agents depends critically on the execution harness, the system layer that orchestrates tool use, context management, and state persistence. Yet this same architectural centrality makes the harness a high-value attack surface: a single compromise at the harness level can cascade through the entire execution pipeline. We observe that existing security approaches suffer from structural mismatch, leaving them blind to harness-internal state and unable to coordinate across the different phases of agent operation. In this paper, we introduce \safeharness{}, a security architecture in which four proposed defense layers are woven directly into the agent lifecycle to address above significant limitations: adversarial context filtering at input processing, tiered causal verification at decision making, privilege-separated tool control at action execution, and safe rollback with adaptive degradation at state update. The proposed cross-layer mechanisms tie these layers together, escalating verification rigor, triggering rollbacks, and tightening tool privileges whenever sustained anomalies are detected. We evaluate \safeharness{} on benchmark datasets across diverse harness configurations, comparing against four security baselines under five attack scenarios spanning six threat categories. Compared to the unprotected baseline, \safeharness{} achieves an average reduction of approximately 38\% in UBR and 42\% in ASR, substantially lowering both the unsafe behavior rate and the attack success rate while preserving core task utility.
HyperMem: Hypergraph Memory for Long-Term Conversations
Apr 09, 2026Long-term memory is essential for conversational agents to maintain coherence, track persistent tasks, and provide personalized interactions across extended dialogues. However, existing approaches as Retrieval-Augmented Generation (RAG) and graph-based memory mostly rely on pairwise relations, which can hardly capture high-order associations, i.e., joint dependencies among multiple elements, causing fragmented retrieval. To this end, we propose HyperMem, a hypergraph-based hierarchical memory architecture that explicitly models such associations using hyperedges. Particularly, HyperMem structures memory into three levels: topics, episodes, and facts, and groups related episodes and their facts via hyperedges, unifying scattered content into coherent units. Leveraging this structure, we design a hybrid lexical-semantic index and a coarse-to-fine retrieval strategy, supporting accurate and efficient retrieval of high-order associations. Experiments on the LoCoMo benchmark show that HyperMem achieves state-of-the-art performance with 92.73% LLM-as-a-judge accuracy, demonstrating the effectiveness of HyperMem for long-term conversations.
Exons-Detect: Identifying and Amplifying Exonic Tokens via Hidden-State Discrepancy for Robust AI-Generated Text Detection
Mar 26, 2026The rapid advancement of large language models has increasingly blurred the boundary between human-written and AI-generated text, raising societal risks such as misinformation dissemination, authorship ambiguity, and threats to intellectual property rights. These concerns highlight the urgent need for effective and reliable detection methods. While existing training-free approaches often achieve strong performance by aggregating token-level signals into a global score, they typically assume uniform token contributions, making them less robust under short sequences or localized token modifications. To address these limitations, we propose Exons-Detect, a training-free method for AI-generated text detection based on an exon-aware token reweighting perspective. Exons-Detect identifies and amplifies informative exonic tokens by measuring hidden-state discrepancy under a dual-model setting, and computes an interpretable translation score from the resulting importance-weighted token sequence. Empirical evaluations demonstrate that Exons-Detect achieves state-of-the-art detection performance and exhibits strong robustness to adversarial attacks and varying input lengths. In particular, it attains a 2.2\% relative improvement in average AUROC over the strongest prior baseline on DetectRL.
Rethinking LLM Watermark Detection in Black-Box Settings: A Non-Intrusive Third-Party Framework
Mar 16, 2026While watermarking serves as a critical mechanism for LLM provenance, existing secret-key schemes tightly couple detection with injection, requiring access to keys or provider-side scheme-specific detectors for verification. This dependency creates a fundamental barrier for real-world governance, as independent auditing becomes impossible without compromising model security or relying on the opaque claims of service providers. To resolve this dilemma, we introduce TTP-Detect, a pioneering black-box framework designed for non-intrusive, third-party watermark verification. By decoupling detection from injection, TTP-Detect reframes verification as a relative hypothesis testing problem. It employs a proxy model to amplify watermark-relevant signals and a suite of complementary relative measurements to assess the alignment of the query text with watermarked distributions. Extensive experiments across representative watermarking schemes, datasets and models demonstrate that TTP-Detect achieves superior detection performance and robustness against diverse attacks.
WorldCup Sampling for Multi-bit LLM Watermarking
Feb 02, 2026As large language models (LLMs) generate increasingly human-like text, watermarking offers a promising solution for reliable attribution beyond mere detection. While multi-bit watermarking enables richer provenance encoding, existing methods largely extend zero-bit schemes through seed-driven steering, leading to indirect information flow, limited effective capacity, and suboptimal decoding. In this paper, we propose WorldCup, a multi-bit watermarking framework for LLMs that treats sampling as a natural communication channel and embeds message bits directly into token selection via a hierarchical competition mechanism guided by complementary signals. Moreover, WorldCup further adopts entropy-aware modulation to preserve generation quality and supports robust message recovery through confidence-aware decoding. Comprehensive experiments show that WorldCup achieves a strong balance across capacity, detectability, robustness, text quality, and decoding efficiency, consistently outperforming prior baselines and laying a solid foundation for future LLM watermarking studies.
SE-EE Tradeoff in Pinching-Antenna Systems: Waveguide Multiplexing or Waveguide Switching?
Jan 08, 2026The spectral and energy efficiency (SE-EE) trade-off in pinching-antenna systems (PASS) is investigated in this paper. In particular, two practical operating protocols, namely waveguide multiplexing (WM) and waveguide switching (WS), are considered. A multi-objective optimization problem (MOOP) is formulated to jointly optimize the baseband and pinching beamforming for maximizing the achievable SE and EE, which is then converted into a single-objective problem via the ε-constraint method. For WM, the problem is decomposed within the alternating-optimization framework, where the baseband beamforming is optimized using the successive convex approximation, and the pinching beamforming is updated through the particle swarm optimization. For WS, due to the time-division transmission and interference-free nature, the pinching beamforming in each time slot is first adjusted to maximize the served user channel gain, followed by the baseband power allocation. Simulation results demonstrate that 1) PASS outperforms conventional antennas by mitigating large-scale path losses; 2) WS leads to a higher maximum achievable EE by activating a single RF chain, whereas WM yields a higher SE upper bound by serving all users concurrently; and 3) increasing the number of users substantially enhances SE under WM, whereas WS shows more pronounced benefits in low-signal-to-noise ratio regimes.
Semantic Codebooks as Effective Priors for Neural Speech Compression
Dec 25, 2025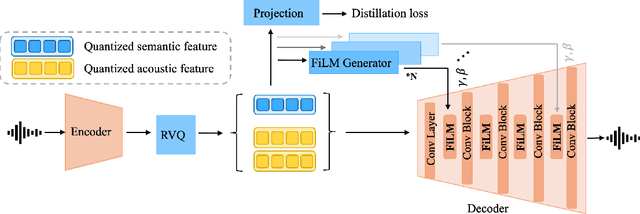
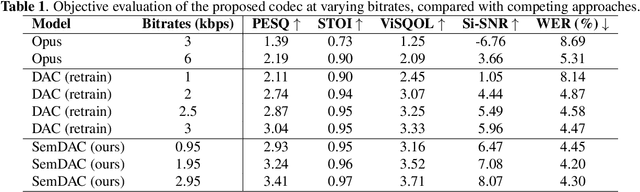
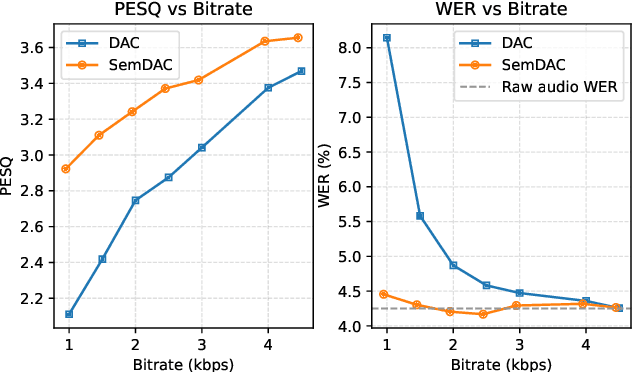
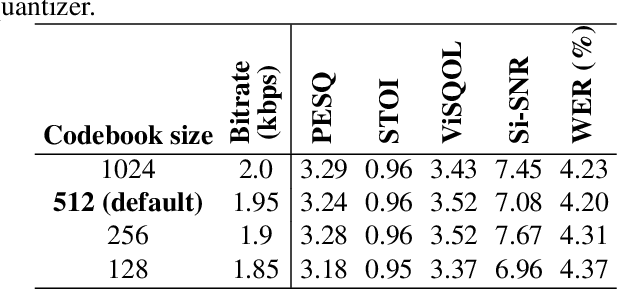
Speech codecs are traditionally optimized for waveform fidelity, allocating bits to preserve acoustic detail even when much of it can be inferred from linguistic structure. This leads to inefficient compression and suboptimal performance on downstream recognition tasks. We propose SemDAC, a semantic-aware neural audio codec that leverages semantic codebooks as effective priors for speech compression. In SemDAC, the first quantizer in a residual vector quantization (RVQ) stack is distilled from HuBERT features to produce semantic tokens that capture phonetic content, while subsequent quantizers model residual acoustics. A FiLM-conditioned decoder reconstructs audio conditioned on the semantic tokens, improving efficiency in the use of acoustic codebooks. Despite its simplicity, this design proves highly effective: SemDAC outperforms DAC across perceptual metrics and achieves lower WER when running Whisper on reconstructed speech, all while operating at substantially lower bitrates (e.g., 0.95 kbps vs. 2.5 kbps for DAC). These results demonstrate that semantic codebooks provide an effective inductive bias for neural speech compression, producing compact yet recognition-friendly representations.
DualGuard: Dual-stream Large Language Model Watermarking Defense against Paraphrase and Spoofing Attack
Dec 18, 2025With the rapid development of cloud-based services, large language models (LLMs) have become increasingly accessible through various web platforms. However, this accessibility has also led to growing risks of model abuse. LLM watermarking has emerged as an effective approach to mitigate such misuse and protect intellectual property. Existing watermarking algorithms, however, primarily focus on defending against paraphrase attacks while overlooking piggyback spoofing attacks, which can inject harmful content, compromise watermark reliability, and undermine trust in attribution. To address this limitation, we propose DualGuard, the first watermarking algorithm capable of defending against both paraphrase and spoofing attacks. DualGuard employs the adaptive dual-stream watermarking mechanism, in which two complementary watermark signals are dynamically injected based on the semantic content. This design enables DualGuard not only to detect but also to trace spoofing attacks, thereby ensuring reliable and trustworthy watermark detection. Extensive experiments conducted across multiple datasets and language models demonstrate that DualGuard achieves excellent detectability, robustness, traceability, and text quality, effectively advancing the state of LLM watermarking for real-world applications.
CurriFlow: Curriculum-Guided Depth Fusion with Optical Flow-Based Temporal Alignment for 3D Semantic Scene Completion
Oct 14, 2025Semantic Scene Completion (SSC) aims to infer complete 3D geometry and semantics from monocular images, serving as a crucial capability for camera-based perception in autonomous driving. However, existing SSC methods relying on temporal stacking or depth projection often lack explicit motion reasoning and struggle with occlusions and noisy depth supervision. We propose CurriFlow, a novel semantic occupancy prediction framework that integrates optical flow-based temporal alignment with curriculum-guided depth fusion. CurriFlow employs a multi-level fusion strategy to align segmentation, visual, and depth features across frames using pre-trained optical flow, thereby improving temporal consistency and dynamic object understanding. To enhance geometric robustness, a curriculum learning mechanism progressively transitions from sparse yet accurate LiDAR depth to dense but noisy stereo depth during training, ensuring stable optimization and seamless adaptation to real-world deployment. Furthermore, semantic priors from the Segment Anything Model (SAM) provide category-agnostic supervision, strengthening voxel-level semantic learning and spatial consistency. Experiments on the SemanticKITTI benchmark demonstrate that CurriFlow achieves state-of-the-art performance with a mean IoU of 16.9, validating the effectiveness of our motion-guided and curriculum-aware design for camera-based 3D semantic scene completion.