 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriFlow: Curriculum-Guided Depth Fusion with Optical Flow-Based Temporal Alignment for 3D Semantic Scene Completion
Oct 14, 2025Semantic Scene Completion (SSC) aims to infer complete 3D geometry and semantics from monocular images, serving as a crucial capability for camera-based perception in autonomous driving. However, existing SSC methods relying on temporal stacking or depth projection often lack explicit motion reasoning and struggle with occlusions and noisy depth supervision. We propose CurriFlow, a novel semantic occupancy prediction framework that integrates optical flow-based temporal alignment with curriculum-guided depth fusion. CurriFlow employs a multi-level fusion strategy to align segmentation, visual, and depth features across frames using pre-trained optical flow, thereby improving temporal consistency and dynamic object understanding. To enhance geometric robustness, a curriculum learning mechanism progressively transitions from sparse yet accurate LiDAR depth to dense but noisy stereo depth during training, ensuring stable optimization and seamless adaptation to real-world deployment. Furthermore, semantic priors from the Segment Anything Model (SAM) provide category-agnostic supervision, strengthening voxel-level semantic learning and spatial consistency. Experiments on the SemanticKITTI benchmark demonstrate that CurriFlow achieves state-of-the-art performance with a mean IoU of 16.9, validating the effectiveness of our motion-guided and curriculum-aware design for camera-based 3D semantic scene completion.
3D-MoRe: Unified Modal-Contextual Reasoning for Embodied Question Answering
Jul 16, 2025
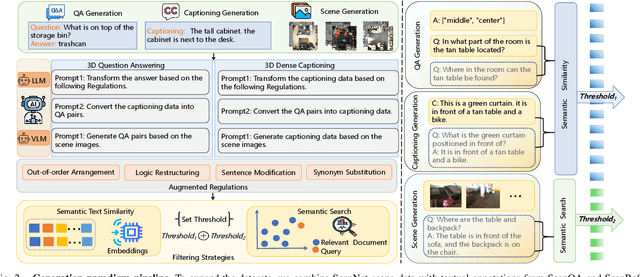


With the growing need for diverse and scalable data in indoor scene tasks, such as question answering and dense captioning, we propose 3D-MoRe, a novel paradigm designed to generate large-scale 3D-language datasets by leveraging the strengths of foundational models. The framework integrates key components, including multi-modal embedding, cross-modal interaction, and a language model decoder, to process natural language instructions and 3D scene data. This approach facilitates enhanced reasoning and response generation in complex 3D environments. Using the ScanNet 3D scene dataset, along with text annotations from ScanQA and ScanRefer, 3D-MoRe generates 62,000 question-answer (QA) pairs and 73,000 object descriptions across 1,513 scenes. We also employ various data augmentation techniques and implement semantic filtering to ensure high-quality data. Experiments on ScanQA demonstrate that 3D-MoRe significantly outperforms state-of-the-art baselines, with the CIDEr score improving by 2.15\%. Similarly, on ScanRefer, our approach achieves a notable increase in CIDEr@0.5 by 1.84\%, highlighting its effectiveness in both tasks. Our code and generated datasets will be publicly released to benefit the community, and both can be accessed on the https://3D-MoRe.github.io.
Focus on Local: Finding Reliable Discriminative Regions for Visual Place Recognition
Apr 14, 2025Visual Place Recognition (VPR) is aimed at predicting the location of a query image by referencing a database of geotagged images. For VPR task, often fewer discriminative local regions in an image produce important effects while mundane background regions do not contribute or even cause perceptual aliasing because of easy overlap. However, existing methods lack precisely modeling and full exploitation of these discriminative regions. In this paper, we propose the Focus on Local (FoL) approach to stimulate the performance of image retrieval and re-ranking in VPR simultaneously by mining and exploiting reliable discriminative local regions in images and introducing pseudo-correlation supervision. First, we design two losses, Extraction-Aggregation Spatial Alignment Loss (SAL) and Foreground-Background Contrast Enhancement Loss (CEL), to explicitly model reliable discriminative local regions and use them to guide the generation of global representations and efficient re-ranking. Second, we introduce a weakly-supervised local feature training strategy based on pseudo-correspondences obtained from aggregating global features to alleviate the lack of local correspondences ground truth for the VPR task. Third, we suggest an efficient re-ranking pipeline that is efficiently and precisely based on discriminative region guidance. Finally, experimental results show that our FoL achieves the state-of-the-art on multiple VPR benchmarks in both image retrieval and re-ranking stages and also significantly outperforms existing two-stage VPR methods in terms of computational efficiency. Code and models are available at https://github.com/chenshunpeng/FoL
Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
Apr 03, 2025Robot vision has greatly benefited from advancements in multimodal fusion techniques and vision-language models (VLMs). We systematically review the applications of multimodal fusion in key robotic vision tasks, including semantic scene understanding, simultaneous localization and mapping (SLAM), 3D object detection, navigation and localization, and robot manipulation. We compare VLMs based on large language models (LLMs) with traditional multimodal fusion methods, analyzing their advantages, limitations, and synergies. Additionally, we conduct an in-depth analysis of commonly used datasets, evaluating their applicability and challenges in real-world robotic scenarios. Furthermore, we identify critical research challenges such as cross-modal alignment, efficient fusion strategies, real-time deployment, and domain adaptation, and propose future research directions, including self-supervised learning for robust multimodal representations, transformer-based fusion architectures, and scalable multimodal frameworks. Through a comprehensive review, comparative analysis, and forward-looking discussion, we provide a valuable reference for advancing multimodal perception and interaction in robotic vision. A comprehensive list of studies in this survey is available at https://github.com/Xiaofeng-Han-Res/MF-RV.
Local Feature Matching Using Deep Learning: A Survey
Jan 31, 2024



Local feature matching enjoys wide-ranging applications in the realm of computer vision, encompassing domains such as image retrieval, 3D reconstruction, and object recognition. However, challenges persist in improving the accuracy and robustness of matching due to factors like viewpoint and lighting variations. In recent years, the introduction of deep learning models has sparked widespread exploration into local feature matching techniques. The objective of this endeavor is to furnish a comprehensive overview of local feature matching methods. These methods are categorized into two key segments based on the presence of detectors. The Detector-based category encompasses models inclusive of Detect-then-Describe, Joint Detection and Description, Describe-then-Detect, as well as Graph Based techniques. In contrast, the Detector-free category comprises CNN Based, Transformer Based, and Patch Based methods. Our study extends beyond methodological analysis, incorporating evaluations of prevalent datasets and metrics to facilitate a quantitative comparison of state-of-the-art techniques. The paper also explores the practical application of local feature matching in diverse domains such as Structure from Motion, Remote Sensing Image Registration, and Medical Image Registration, underscoring its versatility and significance across various fields. Ultimately, we endeavor to outline the current challenges faced in this domain and furnish future research directions, thereby serving as a reference for researchers involved in local feature matching and its interconnected domains.