 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoQuant: Shaping Activation Distributions for Low-Bit LLM Quantization
May 25, 2026Low-bit activation quantization remains a major bottleneck in efficient large language model (LLM) deployment. The difficulty is not only that activations contain outliers, but that their distributions are often poorly matched to a low-bit uniform quantizer. Existing post-training quantization (PTQ) methods suppress peaks, balance channels, or minimize reconstruction error, yet they rarely specify what activation distribution is actually easy to discretize. As a result, activations may appear numerically smoother while still incurring large quantization error because the quantization range remains wide or most values collapse into a few levels near the mean. We recast activation transformation as quantizer-facing distribution design and analyze quantization error from an information-theoretic perspective. Our analysis shows that quantization-friendly activations should jointly have a smaller numerical range and sufficient dispersion within that range. Guided by this analysis, we propose InfoQuant, a train-free method that employs Peak Suppression Orthogonal Transformation (PSOT) to shape activations into more quantization-friendly distributions. We further introduce adaptive outlier-token selection to improve the robustness of PSOT during optimization. Across multiple LLM families, InfoQuant consistently outperforms prior PTQ and end-to-end training baselines. Under W4A4KV4, it preserves 97% of floating-point accuracy on average and reduces the LLaMA-2 13B performance gap by 42% over the previous state of the art. Code is available at [https://github.com/LLIKKE/InfoQuant](https://github.com/LLIKKE/InfoQuant)
LatentPilot: Scene-Aware Vision-and-Language Navigation by Dreaming Ahead with Latent Visual Reasoning
Mar 31, 2026Existing vision-and-language navigation (VLN) models primarily reason over past and current visual observations, while largely ignoring the future visual dynamics induced by actions. As a result, they often lack an effective understanding of the causal relationship between actions and how the visual world changes, limiting robust decision-making. Humans, in contrast, can imagine the near future by leveraging action-dynamics causality, which improves both environmental understanding and navigation choices. Inspired by this capability, we propose LatentPilot, a new paradigm that exploits future observations during training as a valuable data source to learn action-conditioned visual dynamics, while requiring no access to future frames at inference. Concretely, we propose a flywheel-style training mechanism that iteratively collects on-policy trajectories and retrains the model to better match the agent's behavior distribution, with an expert takeover triggered when the agent deviates excessively. LatentPilot further learns visual latent tokens without explicit supervision; these latent tokens attend globally in a continuous latent space and are carried across steps, serving as both the current output and the next input, thereby enabling the agent to dream ahead and reason about how actions will affect subsequent observations. Experiments on R2R-CE, RxR-CE, and R2R-PE benchmarks achieve new SOTA results, and real-robot tests across diverse environments demonstrate LatentPilot's superior understanding of environment-action dynamics in scene. Project page:https://abdd.top/latentpilot/
FloorPlan-VLN: A New Paradigm for Floor Plan Guided Vision-Language Navigation
Mar 18, 2026Existing Vision-Language Navigation (VLN) task requires agents to follow verbose instructions, ignoring some potentially useful global spatial priors, limiting their capability to reason about spatial structures. Although human-readable spatial schematics (e.g., floor plans) are ubiquitous in real-world buildings, current agents lack the cognitive ability to comprehend and utilize them. To bridge this gap, we introduce \textbf{FloorPlan-VLN}, a new paradigm that leverages structured semantic floor plans as global spatial priors to enable navigation with only concise instructions. We first construct the FloorPlan-VLN dataset, which comprises over 10k episodes across 72 scenes. It pairs more than 100 semantically annotated floor plans with Matterport3D-based navigation trajectories and concise instructions that omit step-by-step guidance. Then, we propose a simple yet effective method \textbf{FP-Nav} that uses a dual-view, spatio-temporally aligned video sequence, and auxiliary reasoning tasks to align observations, floor plans, and instructions. When evaluated under this new benchmark, our method significantly outperforms adapted state-of-the-art VLN baselines, achieving more than a 60\% relative improvement in navigation success rate. Furthermore, comprehensive noise modeling and real-world deployments demonstrate the feasibility and robustness of FP-Nav to actuation drift and floor plan distortions. These results validate the effectiveness of floor plan guided navigation and highlight FloorPlan-VLN as a promising step toward more spatially intelligent navigation.
Lemon Agent Technical Report
Feb 06, 2026Recent advanced LLM-powered agent systems have exhibited their remarkable capabilities in tackling complex, long-horizon tasks. Nevertheless, they still suffer from inherent limitations in resource efficiency, context management, and multimodal perception. Based on these observations, Lemon Agent is introduced, a multi-agent orchestrator-worker system built on a newly proposed AgentCortex framework, which formalizes the classic Planner-Executor-Memory paradigm through an adaptive task execution mechanism. Our system integrates a hierarchical self-adaptive scheduling mechanism that operates at both the overall orchestrator layer and workers layer. This mechanism can dynamically adjust computational intensity based on task complexity. It enables orchestrator to allocate one or more workers for parallel subtask execution, while workers can further improve operational efficiency by invoking tools concurrently. By virtue of this two-tier architecture, the system achieves synergistic balance between global task coordination and local task execution, thereby optimizing resource utilization and task processing efficiency in complex scenarios. To reduce context redundancy and increase information density during parallel steps, we adopt a three-tier progressive context management strategy. To make fuller use of historical information, we propose a self-evolving memory system, which can extract multi-dimensional valid information from all historical experiences to assist in completing similar tasks. Furthermore, we provide an enhanced MCP toolset. Empirical evaluations on authoritative benchmarks demonstrate that our Lemon Agent can achieve a state-of-the-art 91.36% overall accuracy on GAIA and secures the top position on the xbench-DeepSearch leaderboard with a score of 77+.
Advancing Mathematical Research via Human-AI Interactive Theorem Proving
Dec 11, 2025We investigate how large language models can be used as research tools in scientific computing while preserving mathematical rigor. We propose a human-in-the-loop workflow for interactive theorem proving and discovery with LLMs. Human experts retain control over problem formulation and admissible assumptions, while the model searches for proofs or contradictions, proposes candidate properties and theorems, and helps construct structures and parameters that satisfy explicit constraints, supported by numerical experiments and simple verification checks. Experts treat these outputs as raw material, further refine them, and organize the results into precise statements and rigorous proofs. We instantiate this workflow in a case study on the connection between manifold optimization and Grover's quantum search algorithm, where the pipeline helps identify invariant subspaces, explore Grover-compatible retractions, and obtain convergence guarantees for the retraction-based gradient method. The framework provides a practical template for integrating large language models into frontier mathematical research, enabling faster exploration of proof space and algorithm design while maintaining transparent reasoning responsibilities. Although illustrated on manifold optimization problems in quantum computing, the principles extend to other core areas of scientific computing.
3D-MoRe: Unified Modal-Contextual Reasoning for Embodied Question Answering
Jul 16, 2025
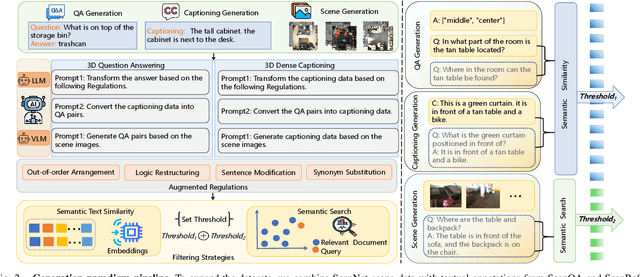


With the growing need for diverse and scalable data in indoor scene tasks, such as question answering and dense captioning, we propose 3D-MoRe, a novel paradigm designed to generate large-scale 3D-language datasets by leveraging the strengths of foundational models. The framework integrates key components, including multi-modal embedding, cross-modal interaction, and a language model decoder, to process natural language instructions and 3D scene data. This approach facilitates enhanced reasoning and response generation in complex 3D environments. Using the ScanNet 3D scene dataset, along with text annotations from ScanQA and ScanRefer, 3D-MoRe generates 62,000 question-answer (QA) pairs and 73,000 object descriptions across 1,513 scenes. We also employ various data augmentation techniques and implement semantic filtering to ensure high-quality data. Experiments on ScanQA demonstrate that 3D-MoRe significantly outperforms state-of-the-art baselines, with the CIDEr score improving by 2.15\%. Similarly, on ScanRefer, our approach achieves a notable increase in CIDEr@0.5 by 1.84\%, highlighting its effectiveness in both tasks. Our code and generated datasets will be publicly released to benefit the community, and both can be accessed on the https://3D-MoRe.github.io.
Cross from Left to Right Brain: Adaptive Text Dreamer for Vision-and-Language Navigation
May 27, 2025Vision-and-Language Navigation (VLN) requires the agent to navigate by following natural instructions under partial observability, making it difficult to align perception with language. Recent methods mitigate this by imagining future scenes, yet they rely on vision-based synthesis, leading to high computational cost and redundant details. To this end, we propose to adaptively imagine key environmental semantics via \textit{language} form, enabling a more reliable and efficient strategy. Specifically, we introduce a novel Adaptive Text Dreamer (ATD), a dual-branch self-guided imagination policy built upon a large language model (LLM). ATD is designed with a human-like left-right brain architecture, where the left brain focuses on logical integration, and the right brain is responsible for imaginative prediction of future scenes. To achieve this, we fine-tune only the Q-former within both brains to efficiently activate domain-specific knowledge in the LLM, enabling dynamic updates of logical reasoning and imagination during navigation. Furthermore, we introduce a cross-interaction mechanism to regularize the imagined outputs and inject them into a navigation expert module, allowing ATD to jointly exploit both the reasoning capacity of the LLM and the expertise of the navigation model. We conduct extensive experiments on the R2R benchmark, where ATD achieves state-of-the-art performance with fewer parameters. The code is \href{https://github.com/zhangpingrui/Adaptive-Text-Dreamer}{here}.
Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
Apr 03, 2025Robot vision has greatly benefited from advancements in multimodal fusion techniques and vision-language models (VLMs). We systematically review the applications of multimodal fusion in key robotic vision tasks, including semantic scene understanding, simultaneous localization and mapping (SLAM), 3D object detection, navigation and localization, and robot manipulation. We compare VLMs based on large language models (LLMs) with traditional multimodal fusion methods, analyzing their advantages, limitations, and synergies. Additionally, we conduct an in-depth analysis of commonly used datasets, evaluating their applicability and challenges in real-world robotic scenarios. Furthermore, we identify critical research challenges such as cross-modal alignment, efficient fusion strategies, real-time deployment, and domain adaptation, and propose future research directions, including self-supervised learning for robust multimodal representations, transformer-based fusion architectures, and scalable multimodal frameworks. Through a comprehensive review, comparative analysis, and forward-looking discussion, we provide a valuable reference for advancing multimodal perception and interaction in robotic vision. A comprehensive list of studies in this survey is available at https://github.com/Xiaofeng-Han-Res/MF-RV.
Action Tokenizer Matters in In-Context Imitation Learning
Mar 05, 2025



In-context imitation learning (ICIL) is a new paradigm that enables robots to generalize from demonstrations to unseen tasks without retraining. A well-structured action representation is the key to capturing demonstration information effectively, yet action tokenizer (the process of discretizing and encoding actions) remains largely unexplored in ICIL. In this work, we first systematically evaluate existing action tokenizer methods in ICIL and reveal a critical limitation: while they effectively encode action trajectories, they fail to preserve temporal smoothness, which is crucial for stable robotic execution. To address this, we propose LipVQ-VAE, a variational autoencoder that enforces the Lipschitz condition in the latent action space via weight normalization. By propagating smoothness constraints from raw action inputs to a quantized latent codebook, LipVQ-VAE generates more stable and smoother actions. When integrating into ICIL, LipVQ-VAE improves performance by more than 5.3% in high-fidelity simulators, with real-world experiments confirming its ability to produce smoother, more reliable trajectories. Code and checkpoints will be released.
Language and Planning in Robotic Navigation: A Multilingual Evaluation of State-of-the-Art Models
Jan 07, 2025



Large Language Models (LLMs) such as GPT-4, trained on huge amount of datasets spanning multiple domains, exhibit significant reasoning, understanding, and planning capabilities across various tasks. This study presents the first-ever work in Arabic language integration within the Vision-and-Language Navigation (VLN) domain in robotics, an area that has been notably underexplored in existing research. We perform a comprehensive evaluation of state-of-the-art multi-lingual Small Language Models (SLMs), including GPT-4o mini, Llama 3 8B, and Phi-3 medium 14B, alongside the Arabic-centric LLM, Jais. Our approach utilizes the NavGPT framework, a pure LLM-based instruction-following navigation agent, to assess the impact of language on navigation reasoning through zero-shot sequential action prediction using the R2R dataset. Through comprehensive experiments, we demonstrate that our framework is capable of high-level planning for navigation tasks when provided with instructions in both English and Arabic. However, certain models struggled with reasoning and planning in the Arabic language due to inherent limitations in their capabilities, sub-optimal performance, and parsing issues. These findings highlight the importance of enhancing planning and reasoning capabilities in language models for effective navigation, emphasizing this as a key area for further development while also unlocking the potential of Arabic-language models for impactful real-world applications.