 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Understand Layouts
Jul 08, 2024Large language models (LLMs) demonstrate extraordinary abilities in a wide range of natural language processing (NLP) tasks. In this paper, we show that, beyond text understanding capability, LLMs are capable of processing text layouts that are denoted by spatial markers. They are able to answer questions that require explicit spatial perceiving and reasoning, while a drastic performance drop is observed when the spatial markers from the original data are excluded. We perform a series of experiments with the GPT-3.5, Baichuan2, Llama2 and ChatGLM3 models on various types of layout-sensitive datasets for further analysis. The experimental results reveal that the layout understanding ability of LLMs is mainly introduced by the coding data for pretraining, which is further enhanced at the instruction-tuning stage. In addition, layout understanding can be enhanced by integrating low-cost, auto-generated data approached by a novel text game. Finally, we show that layout understanding ability is beneficial for building efficient visual question-answering (VQA) systems.
82 Treebanks, 34 Models: Universal Dependency Parsing with Multi-Treebank Models
Sep 06, 2018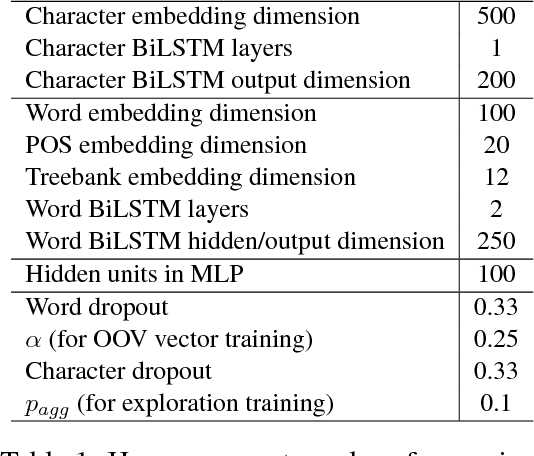
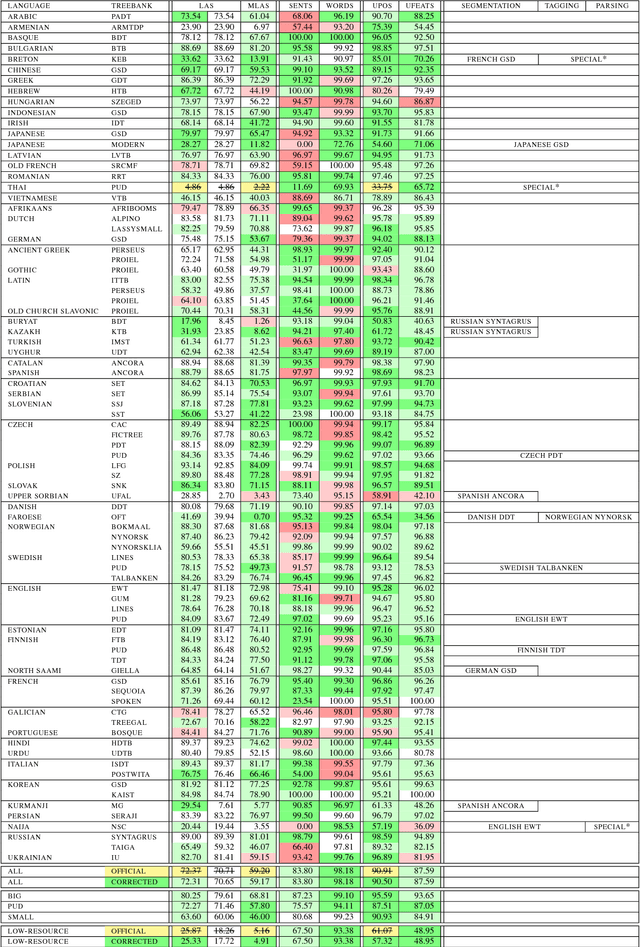
We present the Uppsala system for the CoNLL 2018 Shared Task on universal dependency parsing. Our system is a pipeline consisting of three components: the first performs joint word and sentence segmentation; the second predicts part-of- speech tags and morphological features; the third predicts dependency trees from words and tags. Instead of training a single parsing model for each treebank, we trained models with multiple treebanks for one language or closely related languages, greatly reducing the number of models. On the official test run, we ranked 7th of 27 teams for the LAS and MLAS metrics. Our system obtained the best scores overall for word segmentation, universal POS tagging, and morphological features.
Universal Word Segmentation: Implementation and Interpretation
Jul 09, 2018Word segmentation is a low-level NLP task that is non-trivial for a considerable number of languages. In this paper, we present a sequence tagging framework and apply it to word segmentation for a wide range of languages with different writing systems and typological characteristics. Additionally, we investigate the correlations between various typological factors and word segmentation accuracy. The experimental results indicate that segmentation accuracy is positively related to word boundary markers and negatively to the number of unique non-segmental terms. Based on the analysis, we design a small set of language-specific settings and extensively evaluate the segmentation system on the Universal Dependencies datasets. Our model obtains state-of-the-art accuracies on all the UD languages. It performs substantially better on languages that are non-trivial to segment, such as Chinese, Japanese, Arabic and Hebrew, when compared to previous work.
Character-based Joint Segmentation and POS Tagging for Chinese using Bidirectional RNN-CRF
Sep 12, 2017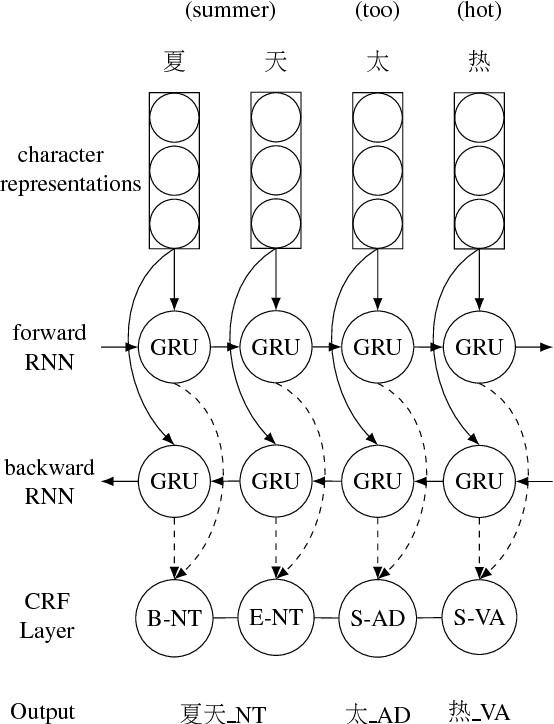


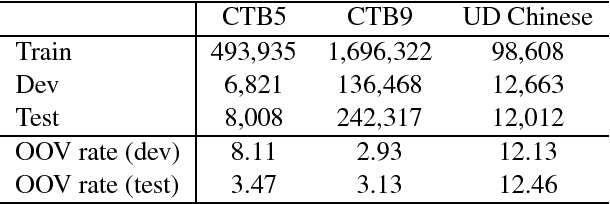
We present a character-based model for joint segmentation and POS tagging for Chinese. The bidirectional RNN-CRF architecture for general sequence tagging is adapted and applied with novel vector representations of Chinese characters that capture rich contextual information and lower-than-character level features. The proposed model is extensively evaluated and compared with a state-of-the-art tagger respectively on CTB5, CTB9 and UD Chinese. The experimental results indicate that our model is accurate and robust across datasets in different sizes, genres and annotation schemes. We obtain state-of-the-art performance on CTB5, achieving 94.38 F1-score for joint segmentation and POS tagging.
Cross-lingual Word Segmentation and Morpheme Segmentation as Sequence Labelling
Sep 12, 2017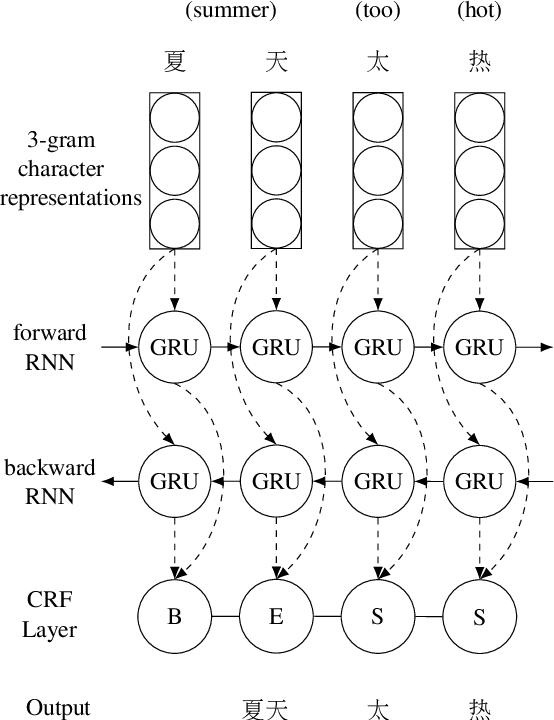


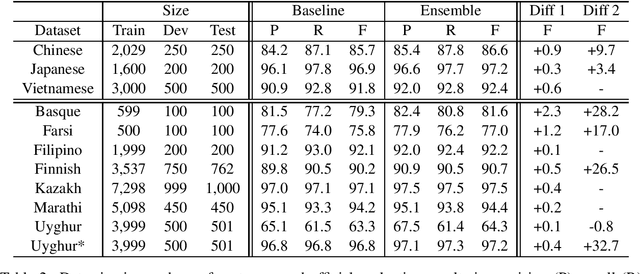
This paper presents our segmentation system developed for the MLP 2017 shared tasks on cross-lingual word segmentation and morpheme segmentation. We model both word and morpheme segmentation as character-level sequence labelling tasks. The prevalent bidirectional recurrent neural network with conditional random fields as the output interface is adapted as the baseline system, which is further improved via ensemble decoding. Our universal system is applied to and extensively evaluated on all the official data sets without any language-specific adjustment. The official evaluation results indicate that the proposed model achieves outstanding accuracies both for word and morpheme segmentation on all the languages in various types when compared to the other participating systems.