 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Extraction and Recognition of Implicit Discourse Relations in Speech and Text
Feb 04, 2026Implicit discourse relation classification is a challenging task, as it requires inferring meaning from context. While contextual cues can be distributed across modalities and vary across languages, they are not always captured by text alone. To address this, we introduce an automatic method for distantly related and unrelated language pairs to construct a multilingual and multimodal dataset for implicit discourse relations in English, French, and Spanish. For classification, we propose a multimodal approach that integrates textual and acoustic information through Qwen2-Audio, allowing joint modeling of text and audio for implicit discourse relation classification across languages. We find that while text-based models outperform audio-based models, integrating both modalities can enhance performance, and cross-lingual transfer can provide substantial improvements for low-resource languages.
Uppsala NLP at SemEval-2021 Task 2: Multilingual Language Models for Fine-tuning and Feature Extraction in Word-in-Context Disambiguation
Apr 09, 2021


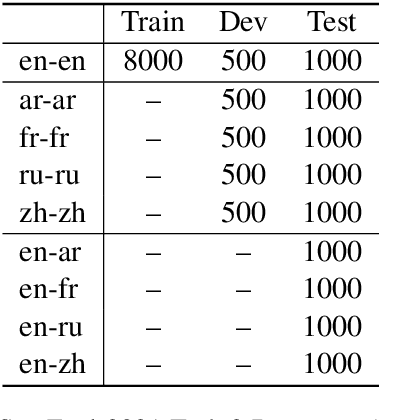
We describe the Uppsala NLP submission to SemEval-2021 Task 2 on multilingual and cross-lingual word-in-context disambiguation. We explore the usefulness of three pre-trained multilingual language models, XLM-RoBERTa (XLMR), Multilingual BERT (mBERT) and multilingual distilled BERT (mDistilBERT). We compare these three models in two setups, fine-tuning and as feature extractors. In the second case we also experiment with using dependency-based information. We find that fine-tuning is better than feature extraction. XLMR performs better than mBERT in the cross-lingual setting both with fine-tuning and feature extraction, whereas these two models give a similar performance in the multilingual setting. mDistilBERT performs poorly with fine-tuning but gives similar results to the other models when used as a feature extractor. We submitted our two best systems, fine-tuned with XLMR and mBERT.
Findings of the 2016 WMT Shared Task on Cross-lingual Pronoun Prediction
Nov 27, 2019



We describe the design, the evaluation setup, and the results of the 2016 WMT shared task on cross-lingual pronoun prediction. This is a classification task in which participants are asked to provide predictions on what pronoun class label should replace a placeholder value in the target-language text, provided in lemmatised and PoS-tagged form. We provided four subtasks, for the English-French and English-German language pairs, in both directions. Eleven teams participated in the shared task; nine for the English-French subtask, five for French-English, nine for English-German, and six for German-English. Most of the submissions outperformed two strong language-model based baseline systems, with systems using deep recurrent neural networks outperforming those using other architectures for most language pairs.
* cross-lingual pronoun prediction, WMT, shared task, English, German, French
What Should/Do/Can LSTMs Learn When Parsing Auxiliary Verb Constructions?
Jul 18, 2019
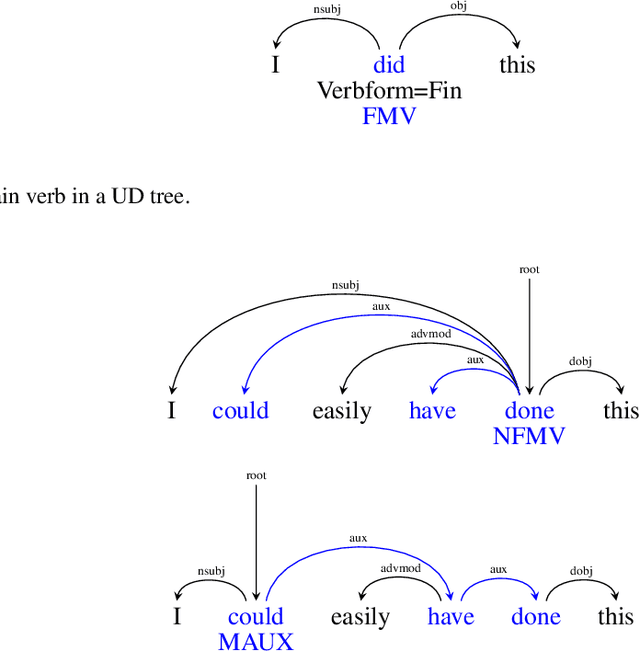
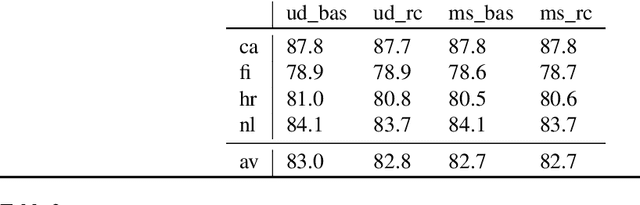
This article is a linguistic investigation of a neural parser. We look at transitivity and agreement information of auxiliary verb constructions (AVCs) in comparison to finite main verbs (FMVs). This comparison is motivated by theoretical work in dependency grammar and in particular the work of Tesni\`ere (1959) where AVCs and FMVs are both instances of a nucleus, the basic unit of syntax. An AVC is a dissociated nucleus, it consists of at least two words, and a FMV is its non-dissociated counterpart, consisting of exactly one word. We suggest that the representation of AVCs and FMVs should capture similar information. We use diagnostic classifiers to probe agreement and transitivity information in vectors learned by a transition-based neural parser in four typologically different languages. We find that the parser learns different information about AVCs and FMVs if only sequential models (BiLSTMs) are used in the architecture but similar information when a recursive layer is used. We find explanations for why this is the case by looking closely at how information is learned in the network and looking at what happens with different dependency representations of AVCs.
82 Treebanks, 34 Models: Universal Dependency Parsing with Multi-Treebank Models
Sep 06, 2018
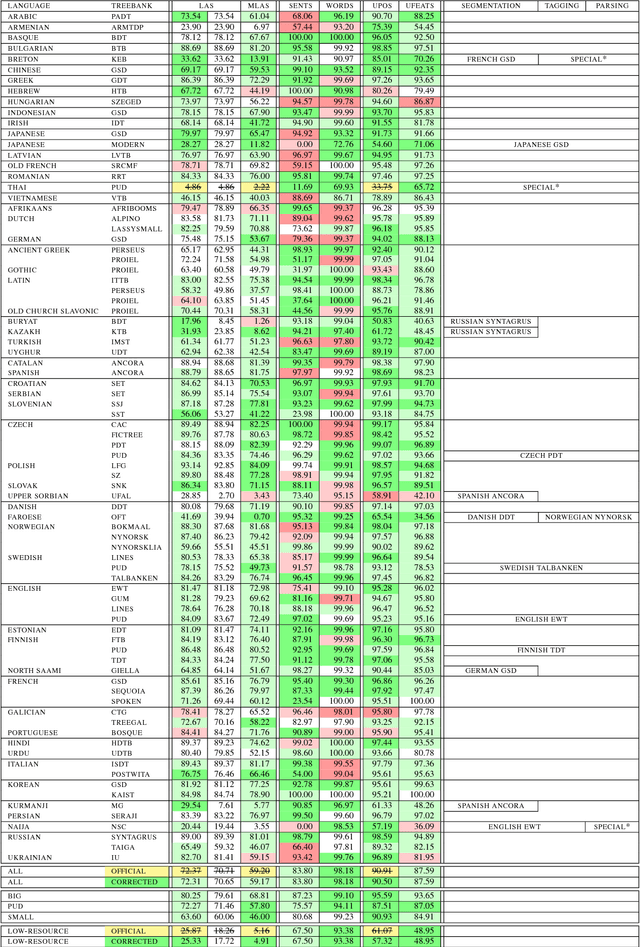
We present the Uppsala system for the CoNLL 2018 Shared Task on universal dependency parsing. Our system is a pipeline consisting of three components: the first performs joint word and sentence segmentation; the second predicts part-of- speech tags and morphological features; the third predicts dependency trees from words and tags. Instead of training a single parsing model for each treebank, we trained models with multiple treebanks for one language or closely related languages, greatly reducing the number of models. On the official test run, we ranked 7th of 27 teams for the LAS and MLAS metrics. Our system obtained the best scores overall for word segmentation, universal POS tagging, and morphological features.
An Investigation of the Interactions Between Pre-Trained Word Embeddings, Character Models and POS Tags in Dependency Parsing
Aug 27, 2018
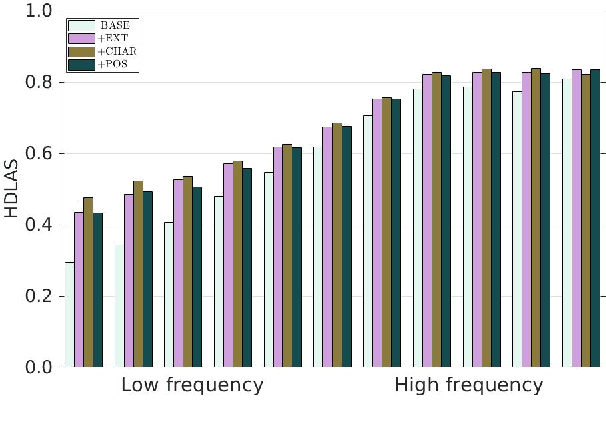

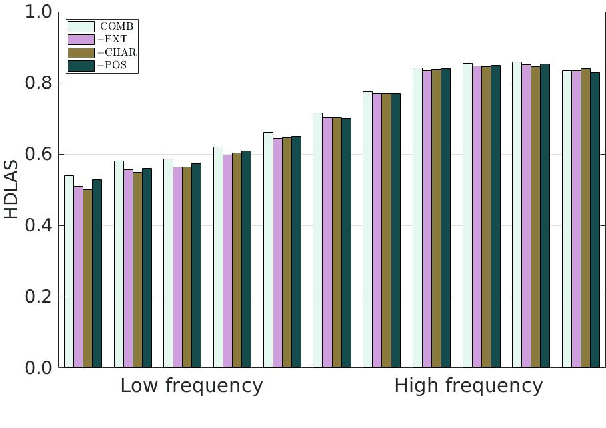
We provide a comprehensive analysis of the interactions between pre-trained word embeddings, character models and POS tags in a transition-based dependency parser. While previous studies have shown POS information to be less important in the presence of character models, we show that in fact there are complex interactions between all three techniques. In isolation each produces large improvements over a baseline system using randomly initialised word embeddings only, but combining them quickly leads to diminishing returns. We categorise words by frequency, POS tag and language in order to systematically investigate how each of the techniques affects parsing quality. For many word categories, applying any two of the three techniques is almost as good as the full combined system. Character models tend to be more important for low-frequency open-class words, especially in morphologically rich languages, while POS tags can help disambiguate high-frequency function words. We also show that large character embedding sizes help even for languages with small character sets, especially in morphologically rich languages.
Parser Training with Heterogeneous Treebanks
May 14, 2018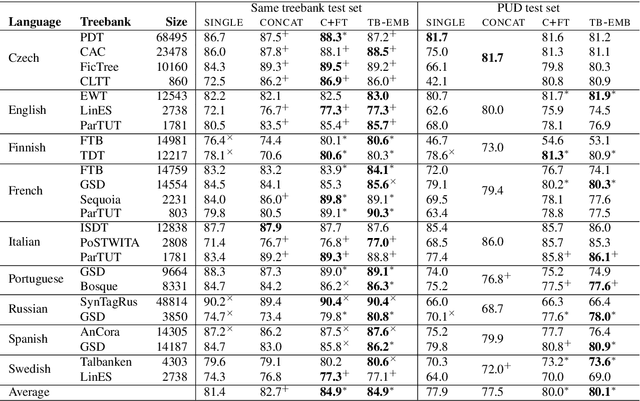
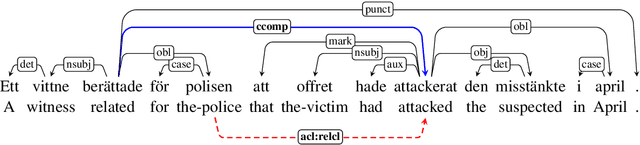
How to make the most of multiple heterogeneous treebanks when training a monolingual dependency parser is an open question. We start by investigating previously suggested, but little evaluated, strategies for exploiting multiple treebanks based on concatenating training sets, with or without fine-tuning. We go on to propose a new method based on treebank embeddings. We perform experiments for several languages and show that in many cases fine-tuning and treebank embeddings lead to substantial improvements over single treebanks or concatenation, with average gains of 2.0--3.5 LAS points. We argue that treebank embeddings should be preferred due to their conceptual simplicity, flexibility and extensibility.