 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUppsala NLP at SemEval-2021 Task 2: Multilingual Language Models for Fine-tuning and Feature Extraction in Word-in-Context Disambiguation
Apr 09, 2021


We describe the Uppsala NLP submission to SemEval-2021 Task 2 on multilingual and cross-lingual word-in-context disambiguation. We explore the usefulness of three pre-trained multilingual language models, XLM-RoBERTa (XLMR), Multilingual BERT (mBERT) and multilingual distilled BERT (mDistilBERT). We compare these three models in two setups, fine-tuning and as feature extractors. In the second case we also experiment with using dependency-based information. We find that fine-tuning is better than feature extraction. XLMR performs better than mBERT in the cross-lingual setting both with fine-tuning and feature extraction, whereas these two models give a similar performance in the multilingual setting. mDistilBERT performs poorly with fine-tuning but gives similar results to the other models when used as a feature extractor. We submitted our two best systems, fine-tuned with XLMR and mBERT.
Cross-lingual Word Sense Disambiguation using mBERT Embeddings with Syntactic Dependencies
Dec 09, 2020
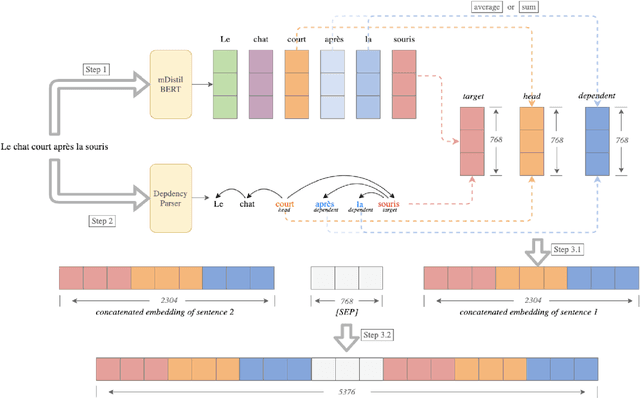
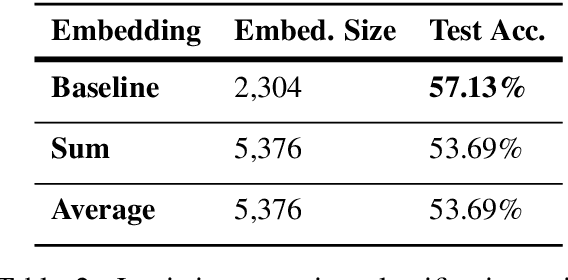
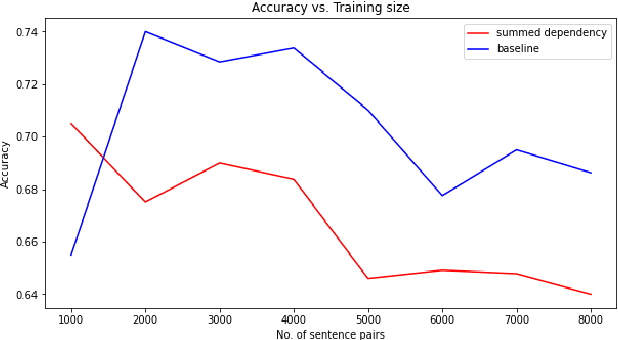
Cross-lingual word sense disambiguation (WSD) tackles the challenge of disambiguating ambiguous words across languages given context. The pre-trained BERT embedding model has been proven to be effective in extracting contextual information of words, and have been incorporated as features into many state-of-the-art WSD systems. In order to investigate how syntactic information can be added into the BERT embeddings to result in both semantics- and syntax-incorporated word embeddings, this project proposes the concatenated embeddings by producing dependency parse tress and encoding the relative relationships of words into the input embeddings. Two methods are also proposed to reduce the size of the concatenated embeddings. The experimental results show that the high dimensionality of the syntax-incorporated embeddings constitute an obstacle for the classification task, which needs to be further addressed in future studies.