 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin Generators for Disease Modeling
May 02, 2024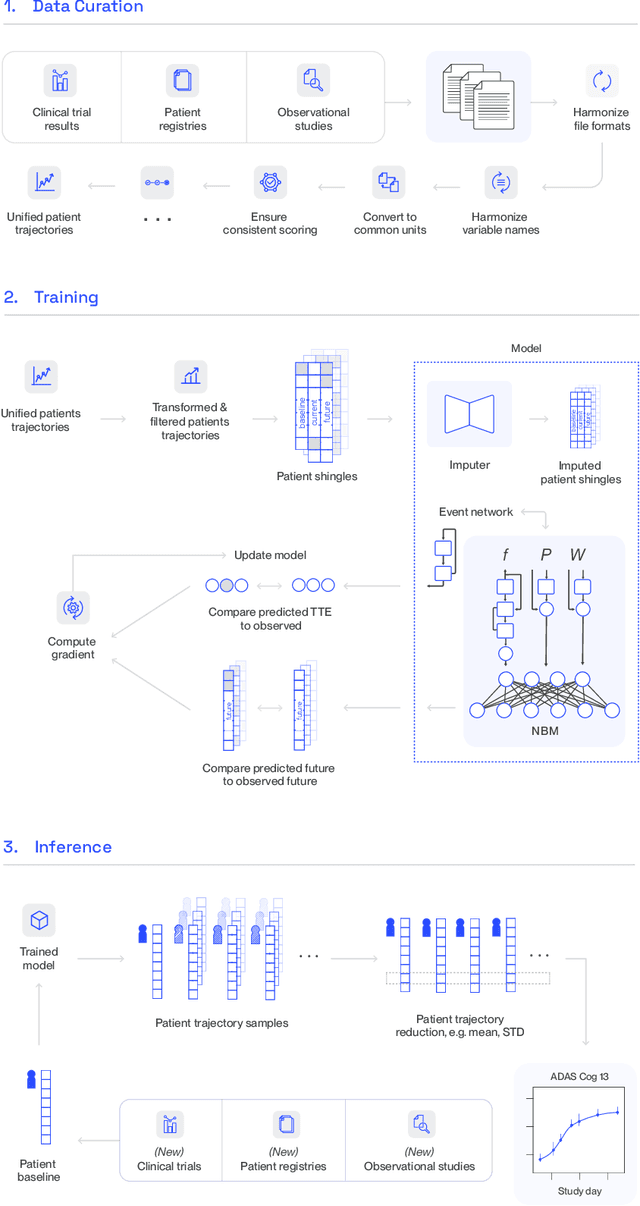
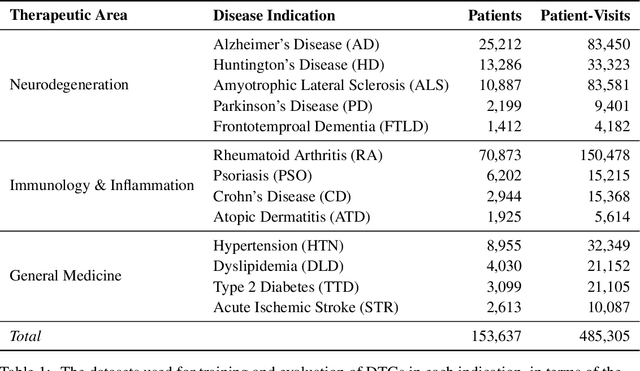
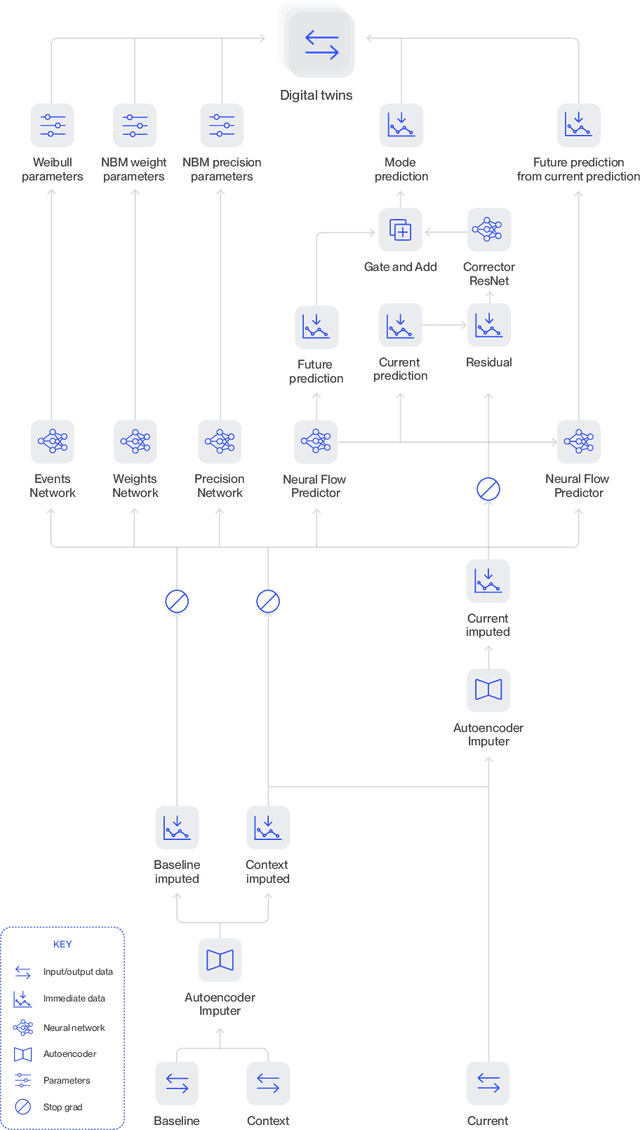
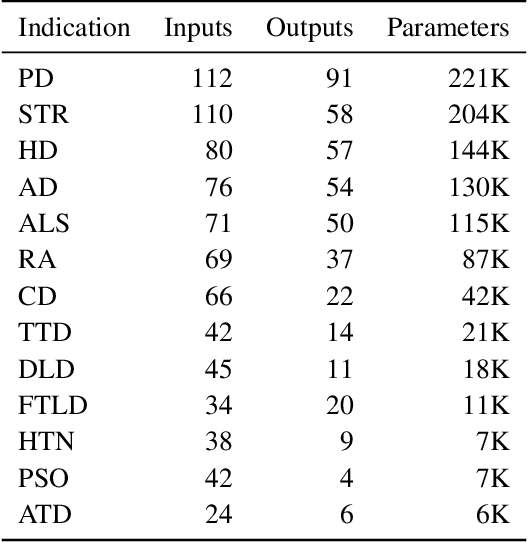
A patient's digital twin is a computational model that describes the evolution of their health over time. Digital twins have the potential to revolutionize medicine by enabling individual-level computer simulations of human health, which can be used to conduct more efficient clinical trials or to recommend personalized treatment options. Due to the overwhelming complexity of human biology, machine learning approaches that leverage large datasets of historical patients' longitudinal health records to generate patients' digital twins are more tractable than potential mechanistic models. In this manuscript, we describe a neural network architecture that can learn conditional generative models of clinical trajectories, which we call Digital Twin Generators (DTGs), that can create digital twins of individual patients. We show that the same neural network architecture can be trained to generate accurate digital twins for patients across 13 different indications simply by changing the training set and tuning hyperparameters. By introducing a general purpose architecture, we aim to unlock the ability to scale machine learning approaches to larger datasets and across more indications so that a digital twin could be created for any patient in the world.
On Cyclical MCMC Sampling
Mar 01, 2024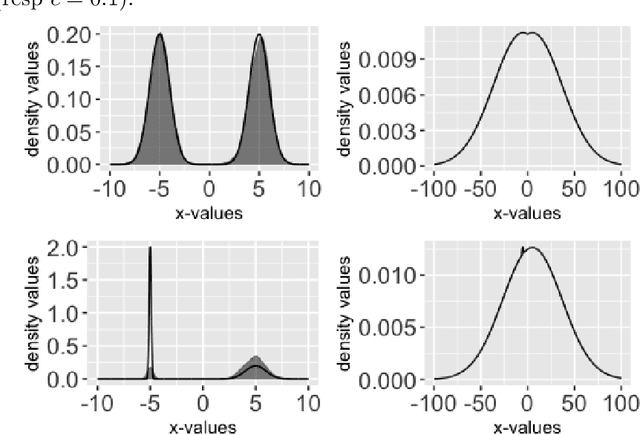
Cyclical MCMC is a novel MCMC framework recently proposed by Zhang et al. (2019) to address the challenge posed by high-dimensional multimodal posterior distributions like those arising in deep learning. The algorithm works by generating a nonhomogeneous Markov chain that tracks -- cyclically in time -- tempered versions of the target distribution. We show in this work that cyclical MCMC converges to the desired probability distribution in settings where the Markov kernels used are fast mixing, and sufficiently long cycles are employed. However in the far more common settings of slow mixing kernels, the algorithm may fail to produce samples from the desired distribution. In particular, in a simple mixture example with unequal variance, we show by simulation that cyclical MCMC fails to converge to the desired limit. Finally, we show that cyclical MCMC typically estimates well the local shape of the target distribution around each mode, even when we do not have convergence to the target.
Importance is Important: A Guide to Informed Importance Tempering Methods
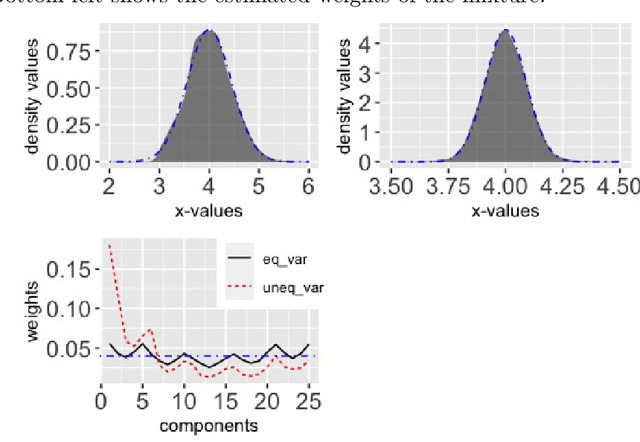
Apr 13, 2023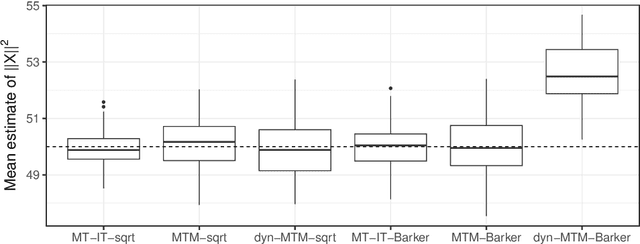

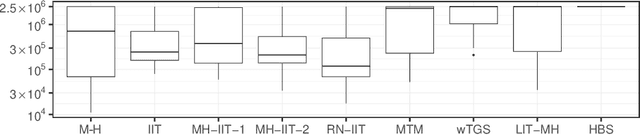
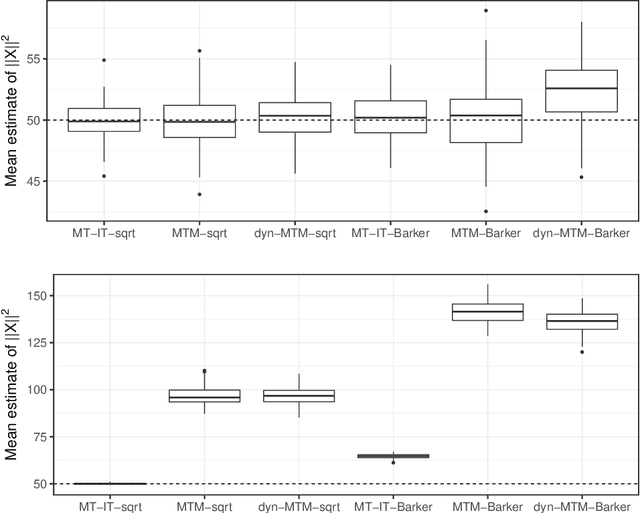
Informed importance tempering (IIT) is an easy-to-implement MCMC algorithm that can be seen as an extension of the familiar Metropolis-Hastings algorithm with the special feature that informed proposals are always accepted, and which was shown in Zhou and Smith (2022) to converge much more quickly in some common circumstances. This work develops a new, comprehensive guide to the use of IIT in many situations. First, we propose two IIT schemes that run faster than existing informed MCMC methods on discrete spaces by not requiring the posterior evaluation of all neighboring states. Second, we integrate IIT with other MCMC techniques, including simulated tempering, pseudo-marginal and multiple-try methods (on general state spaces), which have been conventionally implemented as Metropolis-Hastings schemes and can suffer from low acceptance rates. The use of IIT allows us to always accept proposals and brings about new opportunities for optimizing the sampler which are not possible under the Metropolis-Hastings framework. Numerical examples illustrating our findings are provided for each proposed algorithm, and a general theory on the complexity of IIT methods is developed.
82 Treebanks, 34 Models: Universal Dependency Parsing with Multi-Treebank Models
Sep 06, 2018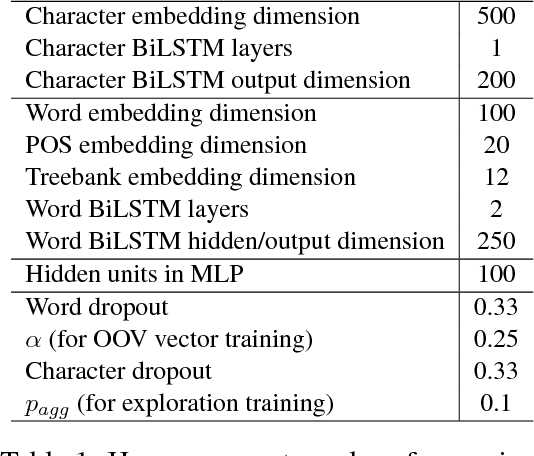
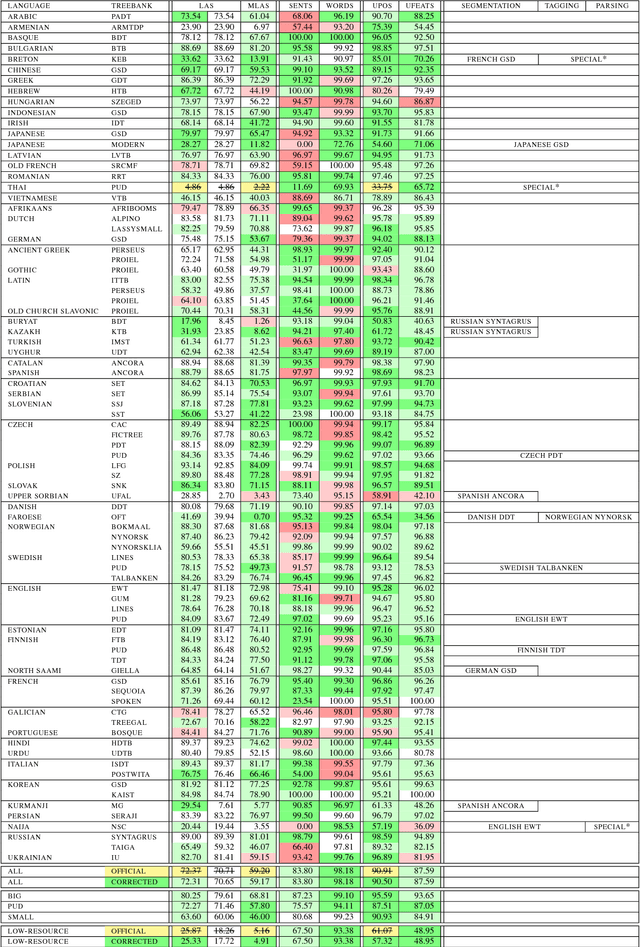
We present the Uppsala system for the CoNLL 2018 Shared Task on universal dependency parsing. Our system is a pipeline consisting of three components: the first performs joint word and sentence segmentation; the second predicts part-of- speech tags and morphological features; the third predicts dependency trees from words and tags. Instead of training a single parsing model for each treebank, we trained models with multiple treebanks for one language or closely related languages, greatly reducing the number of models. On the official test run, we ranked 7th of 27 teams for the LAS and MLAS metrics. Our system obtained the best scores overall for word segmentation, universal POS tagging, and morphological features.
Does Hamiltonian Monte Carlo mix faster than a random walk on multimodal densities?
Sep 04, 2018
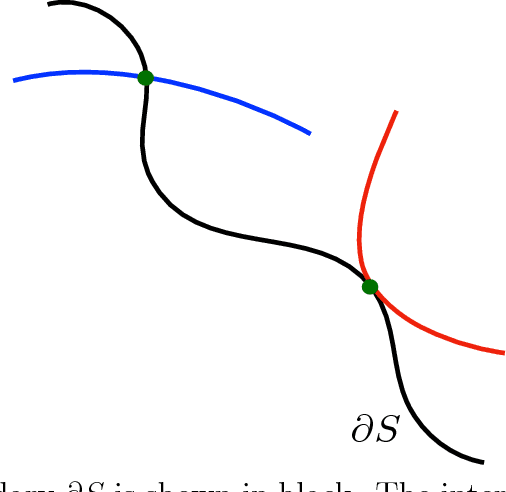
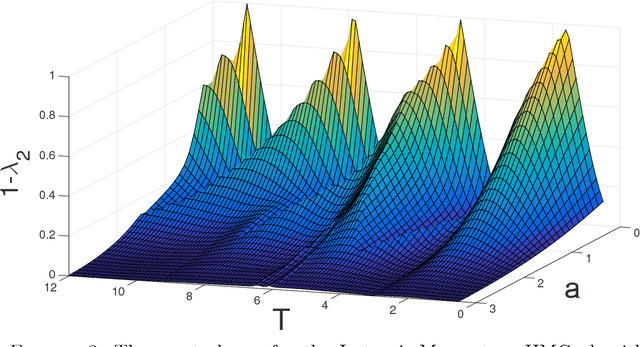
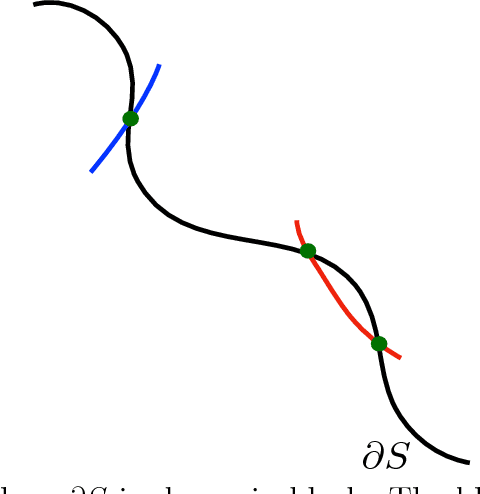
Hamiltonian Monte Carlo (HMC) is a very popular and generic collection of Markov chain Monte Carlo (MCMC) algorithms. One explanation for the popularity of HMC algorithms is their excellent performance as the dimension $d$ of the target becomes large: under conditions that are satisfied for many common statistical models, optimally-tuned HMC algorithms have a running time that scales like $d^{0.25}$. In stark contrast, the running time of the usual Random-Walk Metropolis (RWM) algorithm, optimally tuned, scales like $d$. This superior scaling of the HMC algorithm with dimension is attributed to the fact that it, unlike RWM, incorporates the gradient information in the proposal distribution. In this paper, we investigate a different scaling question: does HMC beat RWM for highly $\textit{multimodal}$ targets? We find that the answer is often $\textit{no}$. We compute the spectral gaps for both the algorithms for a specific class of multimodal target densities, and show that they are identical. The key reason is that, within one mode, the gradient is effectively ignorant about other modes, thus negating the advantage the HMC algorithm enjoys in unimodal targets. We also give heuristic arguments suggesting that the above observation may hold quite generally. Our main tool for answering this question is a novel simple formula for the conductance of HMC using Liouville's theorem. This result allows us to compute the spectral gap of HMC algorithms, for both the classical HMC with isotropic momentum and the recent Riemannian HMC, for multimodal targets.
An Investigation of the Interactions Between Pre-Trained Word Embeddings, Character Models and POS Tags in Dependency Parsing
Aug 27, 2018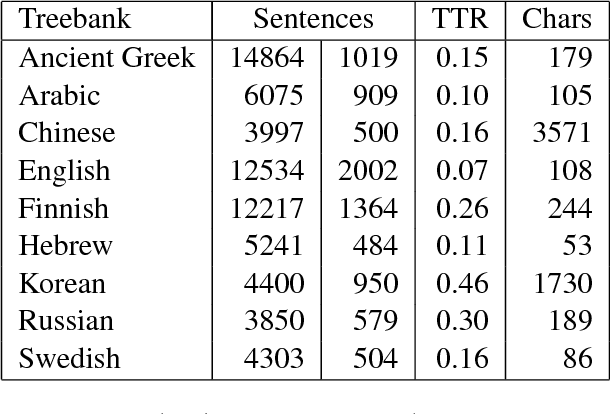
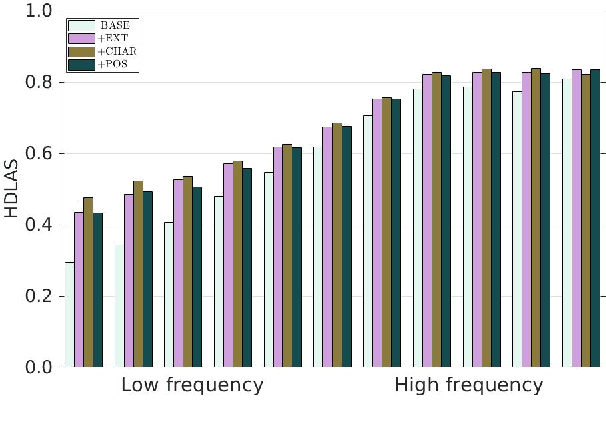

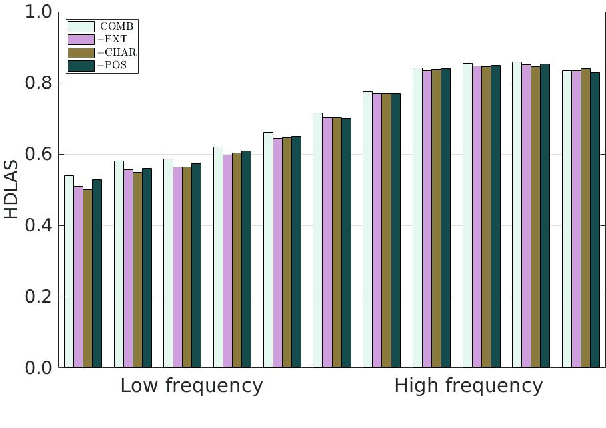
We provide a comprehensive analysis of the interactions between pre-trained word embeddings, character models and POS tags in a transition-based dependency parser. While previous studies have shown POS information to be less important in the presence of character models, we show that in fact there are complex interactions between all three techniques. In isolation each produces large improvements over a baseline system using randomly initialised word embeddings only, but combining them quickly leads to diminishing returns. We categorise words by frequency, POS tag and language in order to systematically investigate how each of the techniques affects parsing quality. For many word categories, applying any two of the three techniques is almost as good as the full combined system. Character models tend to be more important for low-frequency open-class words, especially in morphologically rich languages, while POS tags can help disambiguate high-frequency function words. We also show that large character embedding sizes help even for languages with small character sets, especially in morphologically rich languages.
Parser Training with Heterogeneous Treebanks
May 14, 2018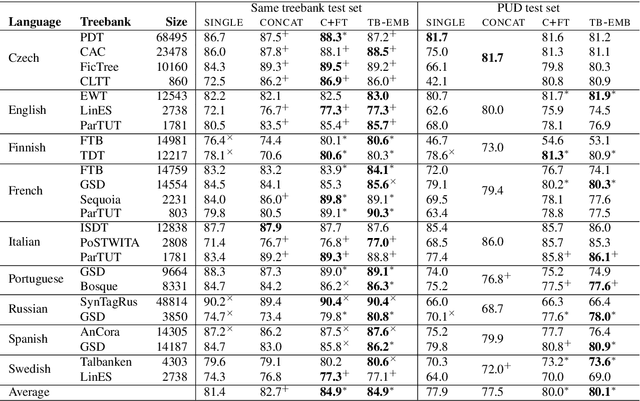
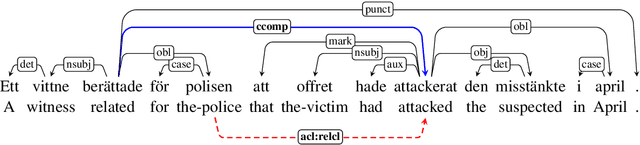
How to make the most of multiple heterogeneous treebanks when training a monolingual dependency parser is an open question. We start by investigating previously suggested, but little evaluated, strategies for exploiting multiple treebanks based on concatenating training sets, with or without fine-tuning. We go on to propose a new method based on treebank embeddings. We perform experiments for several languages and show that in many cases fine-tuning and treebank embeddings lead to substantial improvements over single treebanks or concatenation, with average gains of 2.0--3.5 LAS points. We argue that treebank embeddings should be preferred due to their conceptual simplicity, flexibility and extensibility.