 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalOne: A Family of Foundation Models for Reliable Legal Reasoning
Feb 03, 2026While Large Language Models (LLMs) have demonstrated impressive general capabilities, their direct application in the legal domain is often hindered by a lack of precise domain knowledge and complexity of performing rigorous multi-step judicial reasoning. To address this gap, we present LegalOne, a family of foundational models specifically tailored for the Chinese legal domain. LegalOne is developed through a comprehensive three-phase pipeline designed to master legal reasoning. First, during mid-training phase, we propose Plasticity-Adjusted Sampling (PAS) to address the challenge of domain adaptation. This perplexity-based scheduler strikes a balance between the acquisition of new knowledge and the retention of original capabilities, effectively establishing a robust legal foundation. Second, during supervised fine-tuning, we employ Legal Agentic CoT Distillation (LEAD) to distill explicit reasoning from raw legal texts. Unlike naive distillation, LEAD utilizes an agentic workflow to convert complex judicial processes into structured reasoning trajectories, thereby enforcing factual grounding and logical rigor. Finally, we implement a Curriculum Reinforcement Learning (RL) strategy. Through a progressive reinforcement process spanning memorization, understanding, and reasoning, LegalOne evolves from simple pattern matching to autonomous and reliable legal reasoning. Experimental results demonstrate that LegalOne achieves state-of-the-art performance across a wide range of legal tasks, surpassing general-purpose LLMs with vastly larger parameter counts through enhanced knowledge density and efficiency. We publicly release the LegalOne weights and the LegalKit evaluation framework to advance the field of Legal AI, paving the way for deploying trustworthy and interpretable foundation models in high-stakes judicial applications.
Explore and Establish Synergistic Effects Between Weight Pruning and Coreset Selection in Neural Network Training
Nov 17, 2025Modern deep neural networks rely heavily on massive model weights and training samples, incurring substantial computational costs. Weight pruning and coreset selection are two emerging paradigms proposed to improve computational efficiency. In this paper, we first explore the interplay between redundant weights and training samples through a transparent analysis: redundant samples, particularly noisy ones, cause model weights to become unnecessarily overtuned to fit them, complicating the identification of irrelevant weights during pruning; conversely, irrelevant weights tend to overfit noisy data, undermining coreset selection effectiveness. To further investigate and harness this interplay in deep learning, we develop a Simultaneous Weight and Sample Tailoring mechanism (SWaST) that alternately performs weight pruning and coreset selection to establish a synergistic effect in training. During this investigation, we observe that when simultaneously removing a large number of weights and samples, a phenomenon we term critical double-loss can occur, where important weights and their supportive samples are mistakenly eliminated at the same time, leading to model instability and nearly irreversible degradation that cannot be recovered in subsequent training. Unlike classic machine learning models, this issue can arise in deep learning due to the lack of theoretical guarantees on the correctness of weight pruning and coreset selection, which explains why these paradigms are often developed independently. We mitigate this by integrating a state preservation mechanism into SWaST, enabling stable joint optimization. Extensive experiments reveal a strong synergy between pruning and coreset selection across varying prune rates and coreset sizes, delivering accuracy boosts of up to 17.83% alongside 10% to 90% FLOPs reductions.
ViTs: Teaching Machines to See Time Series Anomalies Like Human Experts
Oct 06, 2025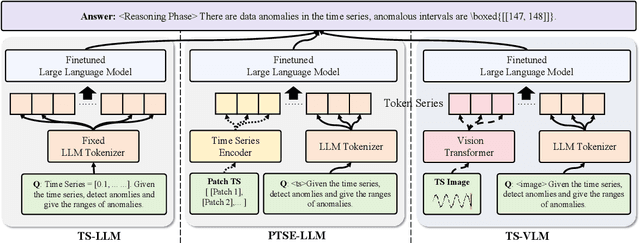

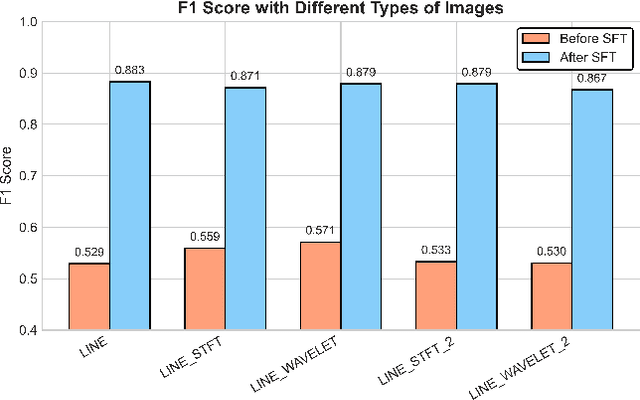
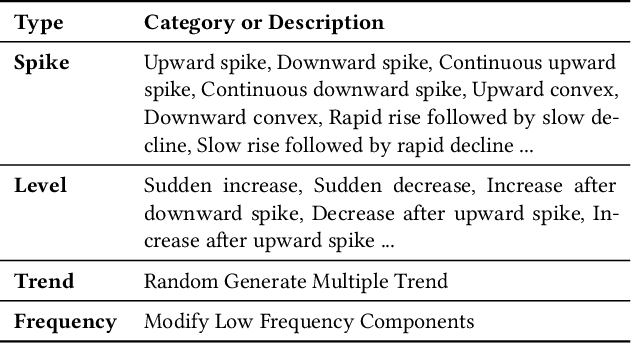
Web service administrators must ensure the stability of multiple systems by promptly detecting anomalies in Key Performance Indicators (KPIs). Achieving the goal of "train once, infer across scenarios" remains a fundamental challenge for time series anomaly detection models. Beyond improving zero-shot generalization, such models must also flexibly handle sequences of varying lengths during inference, ranging from one hour to one week, without retraining. Conventional approaches rely on sliding-window encoding and self-supervised learning, which restrict inference to fixed-length inputs. Large Language Models (LLMs) have demonstrated remarkable zero-shot capabilities across general domains. However, when applied to time series data, they face inherent limitations due to context length. To address this issue, we propose ViTs, a Vision-Language Model (VLM)-based framework that converts time series curves into visual representations. By rescaling time series images, temporal dependencies are preserved while maintaining a consistent input size, thereby enabling efficient processing of arbitrarily long sequences without context constraints. Training VLMs for this purpose introduces unique challenges, primarily due to the scarcity of aligned time series image-text data. To overcome this, we employ an evolutionary algorithm to automatically generate thousands of high-quality image-text pairs and design a three-stage training pipeline consisting of: (1) time series knowledge injection, (2) anomaly detection enhancement, and (3) anomaly reasoning refinement. Extensive experiments demonstrate that ViTs substantially enhance the ability of VLMs to understand and detect anomalies in time series data. All datasets and code will be publicly released at: https://anonymous.4open.science/r/ViTs-C484/.
Learning Time-Varying Convexifications of Multiple Fairness Measures
Aug 19, 2025There is an increasing appreciation that one may need to consider multiple measures of fairness, e.g., considering multiple group and individual fairness notions. The relative weights of the fairness regularisers are a priori unknown, may be time varying, and need to be learned on the fly. We consider the learning of time-varying convexifications of multiple fairness measures with limited graph-structured feedback.
From Minimax Optimal Importance Sampling to Uniformly Ergodic Importance-tempered MCMC
Jun 23, 2025


We make two closely related theoretical contributions to the use of importance sampling schemes. First, for independent sampling, we prove that the minimax optimal trial distribution coincides with the target if and only if the target distribution has no atom with probability greater than $1/2$, where "minimax" means that the worst-case asymptotic variance of the self-normalized importance sampling estimator is minimized. When a large atom exists, it should be downweighted by the trial distribution. A similar phenomenon holds for a continuous target distribution concentrated on a small set. Second, we argue that it is often advantageous to run the Metropolis--Hastings algorithm with a tempered stationary distribution, $\pi(x)^\beta$, and correct for the bias by importance weighting. The dynamics of this "importance-tempered" sampling scheme can be described by a continuous-time Markov chain. We prove that for one-dimensional targets with polynomial tails, $\pi(x) \propto (1 + |x|)^{-\gamma}$, this chain is uniformly ergodic if and only if $1/\gamma < \beta < (\gamma - 2)/\gamma$. These results suggest that for target distributions with light or polynomial tails of order $\gamma > 3$, importance tempering can improve the precision of time-average estimators and essentially eliminate the need for burn-in.
Representative Action Selection for Large Action-Space Meta-Bandits
May 23, 2025We study the problem of selecting a subset from a large action space shared by a family of bandits, with the goal of achieving performance nearly matching that of using the full action space. We assume that similar actions tend to have related payoffs, modeled by a Gaussian process. To exploit this structure, we propose a simple epsilon-net algorithm to select a representative subset. We provide theoretical guarantees for its performance and compare it empirically to Thompson Sampling and Upper Confidence Bound.
Restricted Spectral Gap Decomposition for Simulated Tempering Targeting Mixture Distributions
May 21, 2025Simulated tempering is a widely used strategy for sampling from multimodal distributions. In this paper, we consider simulated tempering combined with an arbitrary local Markov chain Monte Carlo sampler and present a new decomposition theorem that provides a lower bound on the restricted spectral gap of the algorithm for sampling from mixture distributions. By working with the restricted spectral gap, the applicability of our results is extended to broader settings such as when the usual spectral gap is difficult to bound or becomes degenerate. We demonstrate the application of our theoretical results by analyzing simulated tempering combined with random walk Metropolis--Hastings for sampling from mixtures of Gaussian distributions. We show that in fixed-dimensional settings, the algorithm's complexity scales polynomially with the separation between modes and logarithmically with $1/\varepsilon$, where $\varepsilon$ is the target accuracy in total variation distance.
RIS-Assisted Beamfocusing in Near-Field IoT Communication Systems: A Transformer-Based Approach
Apr 17, 2025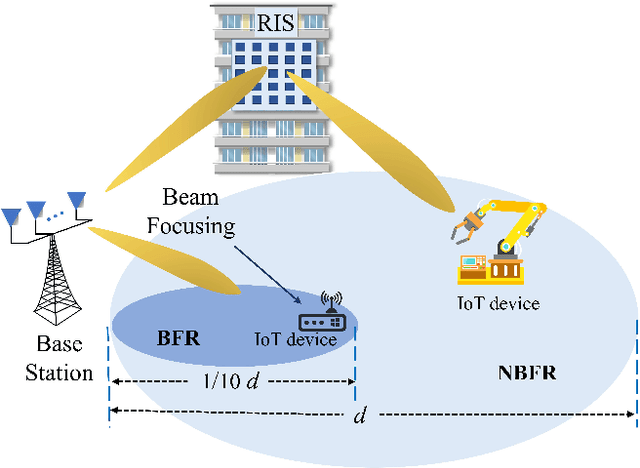
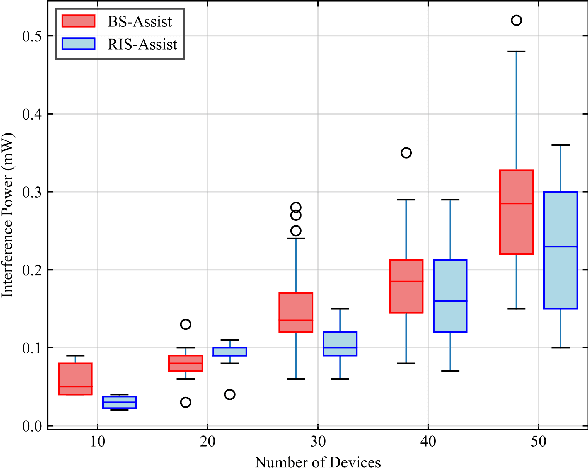
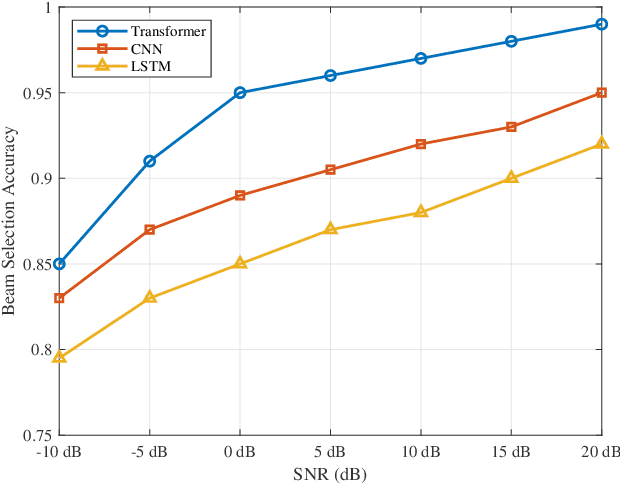
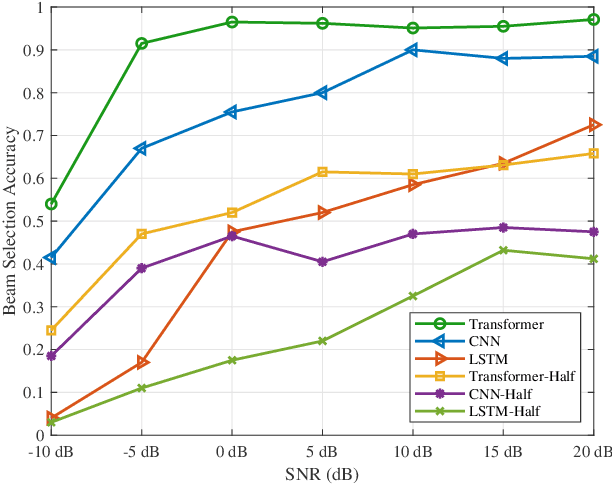
The massive number of antennas in extremely large aperture array (ELAA) systems shifts the propagation regime of signals in internet of things (IoT) communication systems towards near-field spherical wave propagation. We propose a reconfigurable intelligent surfaces (RIS)-assisted beamfocusing mechanism, where the design of the two-dimensional beam codebook that contains both the angular and distance domains is challenging. To address this issue, we introduce a novel Transformer-based two-stage beam training algorithm, which includes the coarse and fine search phases. The proposed mechanism provides a fine-grained codebook with enhanced spatial resolution, enabling precise beamfocusing. Specifically, in the first stage, the beam training is performed to estimate the approximate location of the device by using a simple codebook, determining whether it is within the beamfocusing range (BFR) or the none-beamfocusing range (NBFR). In the second stage, by using a more precise codebook, a fine-grained beam search strategy is conducted. Experimental results unveil that the precision of the RIS-assisted beamfocusing is greatly improved. The proposed method achieves beam selection accuracy up to 97% at signal-to-noise ratio (SNR) of 20 dB, and improves 10% to 50% over the baseline method at different SNRs.
TDFANet: Encoding Sequential 4D Radar Point Clouds Using Trajectory-Guided Deformable Feature Aggregation for Place Recognition
Apr 07, 2025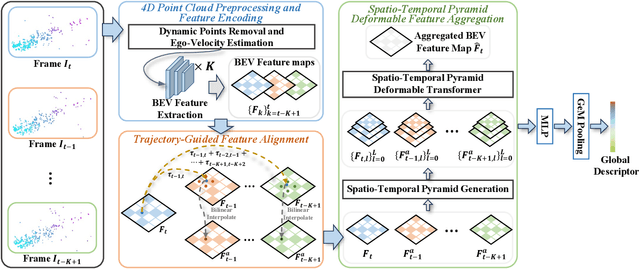
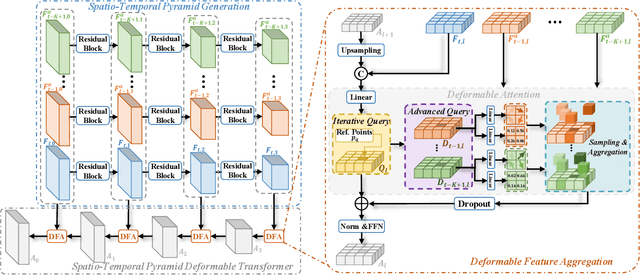
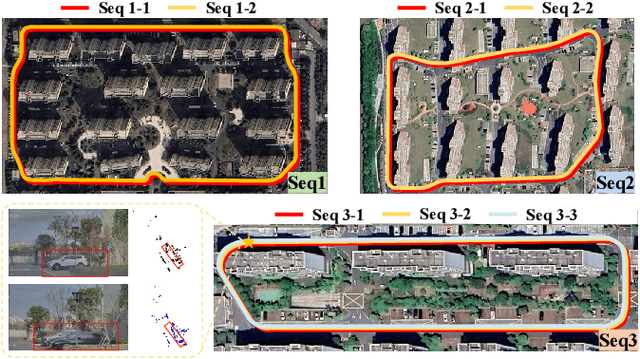

Place recognition is essential for achieving closed-loop or global positioning in autonomous vehicles and mobile robots. Despite recent advancements in place recognition using 2D cameras or 3D LiDAR, it remains to be seen how to use 4D radar for place recognition - an increasingly popular sensor for its robustness against adverse weather and lighting conditions. Compared to LiDAR point clouds, radar data are drastically sparser, noisier and in much lower resolution, which hampers their ability to effectively represent scenes, posing significant challenges for 4D radar-based place recognition. This work addresses these challenges by leveraging multi-modal information from sequential 4D radar scans and effectively extracting and aggregating spatio-temporal features.Our approach follows a principled pipeline that comprises (1) dynamic points removal and ego-velocity estimation from velocity property, (2) bird's eye view (BEV) feature encoding on the refined point cloud, (3) feature alignment using BEV feature map motion trajectory calculated by ego-velocity, (4) multi-scale spatio-temporal features of the aligned BEV feature maps are extracted and aggregated.Real-world experimental results validate the feasibility of the proposed method and demonstrate its robustness in handling dynamic environments. Source codes are available.
Movable-Element RIS-Aided Wireless Communications: An Element-Wise Position Optimization Approach
Mar 19, 2025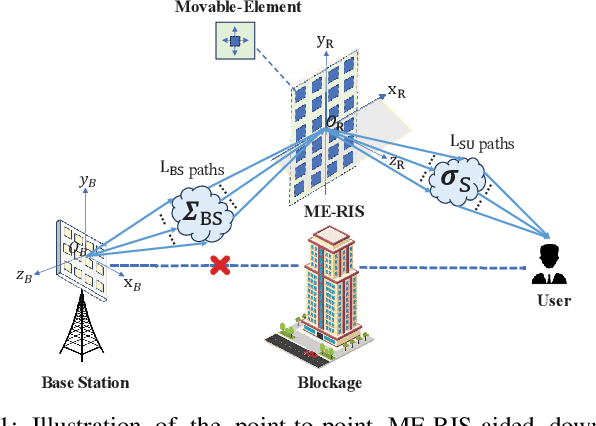

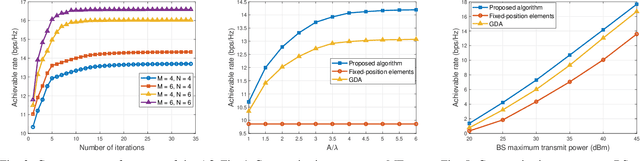
A point-to-point movable element (ME) enabled reconfigurable intelligent surface (ME-RIS) communication system is investigated, where each element position can be flexibly adjusted to create favorable channel conditions. For maximizing the communication rate, an efficient ME position optimization approach is proposed. Specifically, by characterizing the cascaded channel power gain in an element-wise manner, the position of each ME is iteratively updated by invoking the successive convex approximation method. Numerical results unveil that 1) the proposed element-wise ME position optimization algorithm outperforms the gradient descent algorithm; and 2) the ME-RIS significantly improves the communication rate compared to the conventional RIS with fixed-position elements.