 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Deep Are Deep GPs, Really? A Sharp Threshold and a Non-Gaussian Limit for Compositional GPs
Jun 06, 2026Compositional priors describe the generic properties of layered functions in deep Bayesian models, where deep neural networks with random weights are a canonical example.In the wide-network limit, the prior is a Gaussian process with a depth-dependent kernel, and its behaviour as depth grows has been extensively studied through this kernel. Here, we study another case, where each layer itself is a vector valued Gaussian process, and our aim is similarly to understand the limiting behaviour of the prior as depth grows. Previous GP work has established that for the RBF kernel and a certain range of bandwidths $r$, the prior degenerates in the limit, converging to the set of constant functions -- which is not useful as a probabilistic model. In this paper we establish several new results. First, we identify a sharp bandwidth threshold $r_c(d) = Θ(\sqrt{d})$ above which the limit is degenerate, strengthening the earlier bounds. Second, and more importantly, we show that for $r$ below the threshold $r_c(d)$ the prior converges to a limit distribution $π_{\bar{Z}}$. We also prove that these distributions are non-degenerate and non-Gaussian, with non-vanishing dependence between coordinates. In contrast to the previously known degenerate regime, deep Gaussian process priors can therefore admit non-trivial limits. Empirically, we verify the threshold across a range of dimensions $d$, and demonstrate a complex multimodal behaviour of the limit distributions $π_{\bar{Z}}$ -- a regime that becomes increasingly narrow with $d$ and would be hard to identify without knowing the threshold.
Intersectional Fairness via Mixed-Integer Optimization
Jan 27, 2026The deployment of Artificial Intelligence in high-risk domains, such as finance and healthcare, necessitates models that are both fair and transparent. While regulatory frameworks, including the EU's AI Act, mandate bias mitigation, they are deliberately vague about the definition of bias. In line with existing research, we argue that true fairness requires addressing bias at the intersections of protected groups. We propose a unified framework that leverages Mixed-Integer Optimization (MIO) to train intersectionally fair and intrinsically interpretable classifiers. We prove the equivalence of two measures of intersectional fairness (MSD and SPSF) in detecting the most unfair subgroup and empirically demonstrate that our MIO-based algorithm improves performance in finding bias. We train high-performing, interpretable classifiers that bound intersectional bias below an acceptable threshold, offering a robust solution for regulated industries and beyond.
Representative Action Selection for Large Action-Space Meta-Bandits
May 23, 2025We study the problem of selecting a subset from a large action space shared by a family of bandits, with the goal of achieving performance nearly matching that of using the full action space. We assume that similar actions tend to have related payoffs, modeled by a Gaussian process. To exploit this structure, we propose a simple epsilon-net algorithm to select a representative subset. We provide theoretical guarantees for its performance and compare it empirically to Thompson Sampling and Upper Confidence Bound.
Bias Detection via Maximum Subgroup Discrepancy
Feb 04, 2025



Bias evaluation is fundamental to trustworthy AI, both in terms of checking data quality and in terms of checking the outputs of AI systems. In testing data quality, for example, one may study a distance of a given dataset, viewed as a distribution, to a given ground-truth reference dataset. However, classical metrics, such as the Total Variation and the Wasserstein distances, are known to have high sample complexities and, therefore, may fail to provide meaningful distinction in many practical scenarios. In this paper, we propose a new notion of distance, the Maximum Subgroup Discrepancy (MSD). In this metric, two distributions are close if, roughly, discrepancies are low for all feature subgroups. While the number of subgroups may be exponential, we show that the sample complexity is linear in the number of features, thus making it feasible for practical applications. Moreover, we provide a practical algorithm for the evaluation of the distance, based on Mixed-integer optimization (MIO). We also note that the proposed distance is easily interpretable, thus providing clearer paths to fixing the biases once they have been identified. It also provides guarantees for all subgroups. Finally, we empirically evaluate, compare with other metrics, and demonstrate the above properties of MSD on real-world datasets.
Efficient Fairness-Performance Pareto Front Computation
Sep 26, 2024



There is a well known intrinsic trade-off between the fairness of a representation and the performance of classifiers derived from the representation. Due to the complexity of optimisation algorithms in most modern representation learning approaches, for a given method it may be non-trivial to decide whether the obtained fairness-performance curve of the method is optimal, i.e., whether it is close to the true Pareto front for these quantities for the underlying data distribution. In this paper we propose a new method to compute the optimal Pareto front, which does not require the training of complex representation models. We show that optimal fair representations possess several useful structural properties, and that these properties enable a reduction of the computation of the Pareto Front to a compact discrete problem. We then also show that these compact approximating problems can be efficiently solved via off-the shelf concave-convex programming methods. Since our approach is independent of the specific model of representations, it may be used as the benchmark to which representation learning algorithms may be compared. We experimentally evaluate the approach on a number of real world benchmark datasets.
Implicitly Normalized Explicitly Regularized Density Estimation
Jul 25, 2023We propose a new approach to non-parametric density estimation, that is based on regularizing a Sobolev norm of the density. This method is provably different from Kernel Density Estimation, and makes the bias of the model clear and interpretable. While there is no closed analytic form for the associated kernel, we show that one can approximate it using sampling. The optimization problem needed to determine the density is non-convex, and standard gradient methods do not perform well. However, we show that with an appropriate initialization and using natural gradients, one can obtain well performing solutions. Finally, while the approach provides unnormalized densities, which prevents the use of log-likelihood for cross validation, we show that one can instead adapt Fisher Divergence based Score Matching methods for this task. We evaluate the resulting method on the comprehensive recent Anomaly Detection benchmark suite, ADBench, and find that it ranks second best, among more than 15 algorithms.
Whats Missing? Learning Hidden Markov Models When the Locations of Missing Observations are Unknown
Mar 12, 2022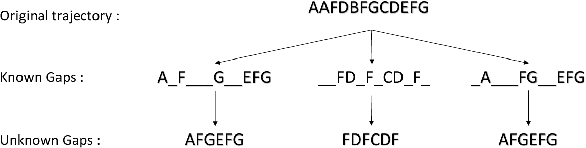
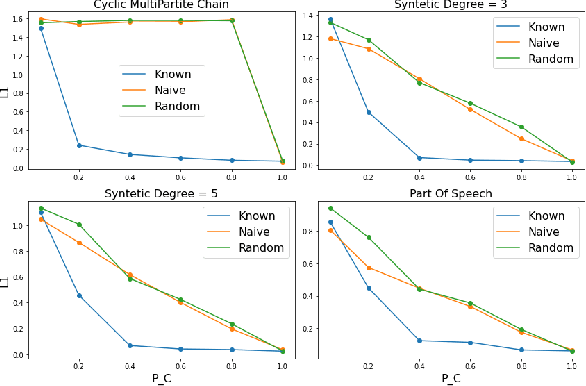
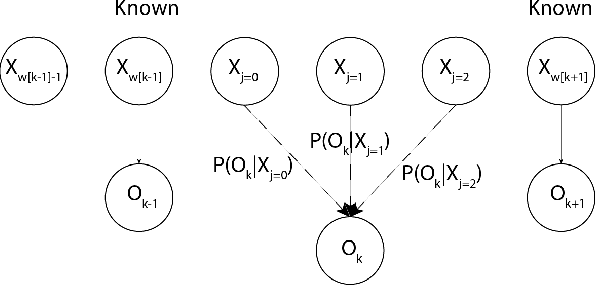
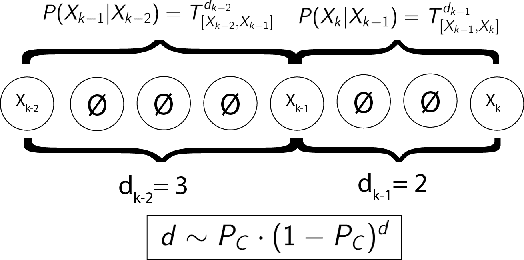
The Hidden Markov Model (HMM) is one of the most widely used statistical models for sequential data analysis, and it has been successfully applied in a large variety of domains. One of the key reasons for this versatility is the ability of HMMs to deal with missing data. However, standard HMM learning algorithms rely crucially on the assumption that the positions of the missing observations within the observation sequence are known. In some situations where such assumptions are not feasible, a number of special algorithms have been developed. Currently, these algorithms rely strongly on specific structural assumptions of the underlying chain, such as acyclicity, and are not applicable in the general case. In particular, there are numerous domains within medicine and computational biology, where the missing observation locations are unknown and acyclicity assumptions do not hold, thus presenting a barrier for the application of HMMs in those fields. In this paper we consider a general problem of learning HMMs from data with unknown missing observation locations (i.e., only the order of the non-missing observations are known). We introduce a generative model of the location omissions and propose two learning methods for this model, a (semi) analytic approach, and a Gibbs sampler. We evaluate and compare the algorithms in a variety of scenarios, measuring their reconstruction precision and robustness under model misspecification.
Dimension Free Generalization Bounds for Non Linear Metric Learning
Feb 07, 2021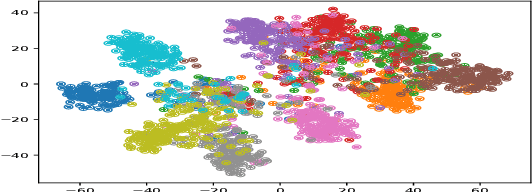
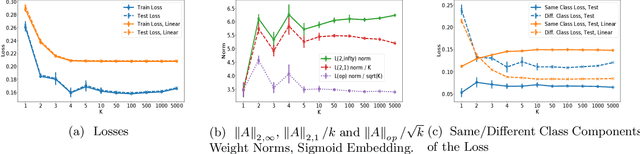
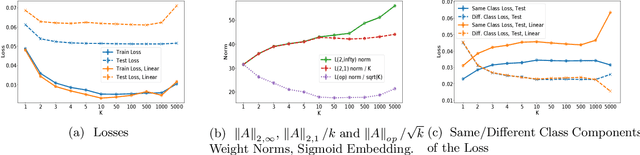
In this work we study generalization guarantees for the metric learning problem, where the metric is induced by a neural network type embedding of the data. Specifically, we provide uniform generalization bounds for two regimes -- the sparse regime, and a non-sparse regime which we term \emph{bounded amplification}. The sparse regime bounds correspond to situations where $\ell_1$-type norms of the parameters are small. Similarly to the situation in classification, solutions satisfying such bounds can be obtained by an appropriate regularization of the problem. On the other hand, unregularized SGD optimization of a metric learning loss typically does not produce sparse solutions. We show that despite this lack of sparsity, by relying on a different, new property of the solutions, it is still possible to provide dimension free generalization guarantees. Consequently, these bounds can explain generalization in non sparse real experimental situations. We illustrate the studied phenomena on the MNIST and 20newsgroups datasets.
Topic Modeling via Full Dependence Mixtures
Jun 13, 2019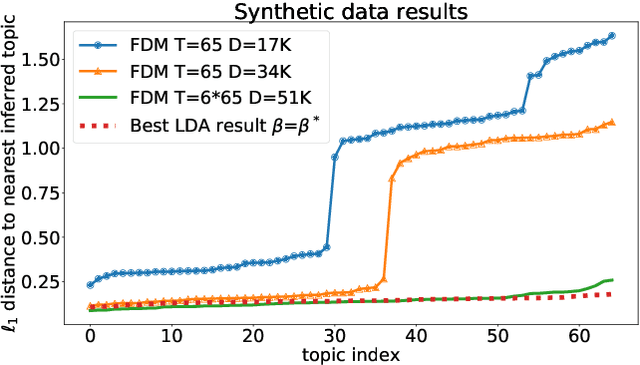
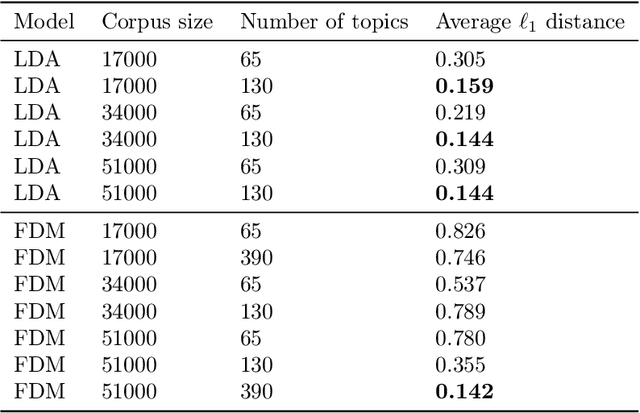
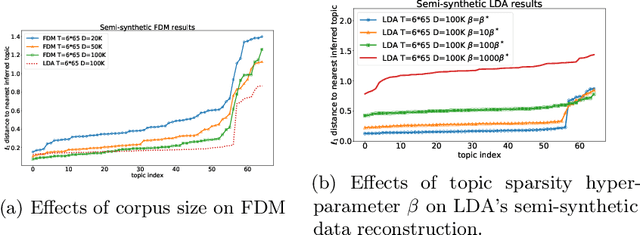
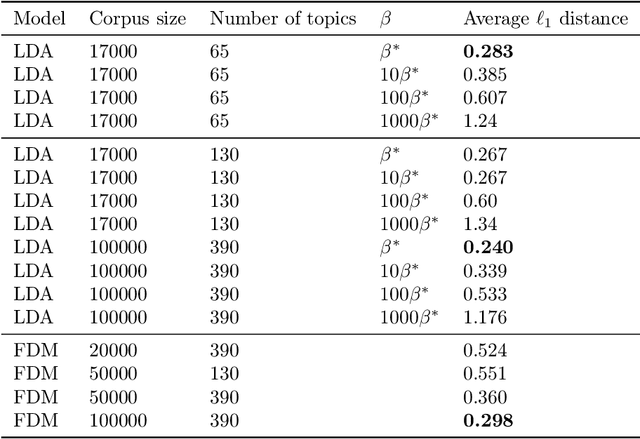
We consider the topic modeling problem for large datasets. For this problem, Latent Dirichlet Allocation (LDA) with a collapsed Gibbs sampler optimization is the state-of-the-art approach in terms of topic quality. However, LDA is a slow approach, and running it on large datasets is impractical even with modern hardware. In this paper we propose to fit topics directly to the co-occurances data of the corpus. In particular, we introduce an extension of a mixture model, the Full Dependence Mixture (FDM), which arises naturally as a model of a second moment under general generative assumptions on the data. While there is some previous work on topic modeling using second moments, we develop a direct stochastic optimization procedure for fitting an FDM with a single Kullback Leibler objective. While moment methods in general have the benefit that an iteration no longer needs to scale with the size of the corpus, our approach also allows us to leverage standard optimizers and GPUs for the problem of topic modeling. We evaluate the approach on synthetic and semi-synthetic data, as well as on the SOTU and Neurips Papers corpora, and show that the approach outperforms LDA, where LDA is run on both full and sub-sampled data.
Variance Estimation For Online Regression via Spectrum Thresholding
Jun 13, 2019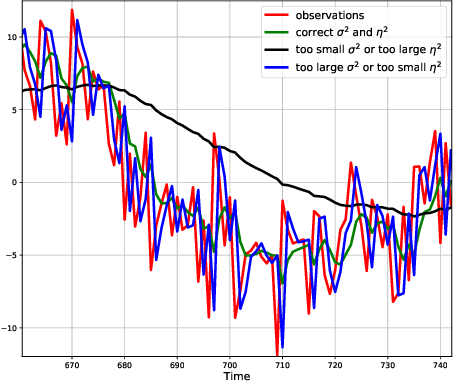
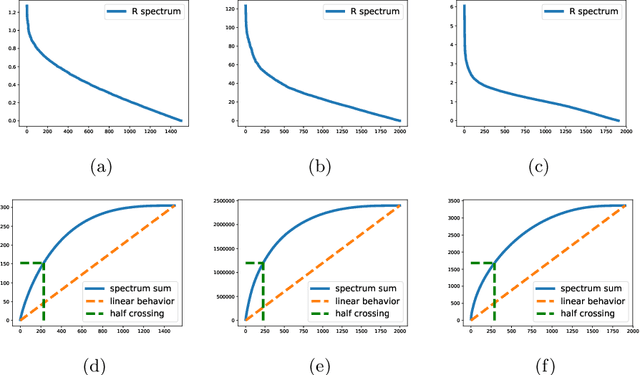
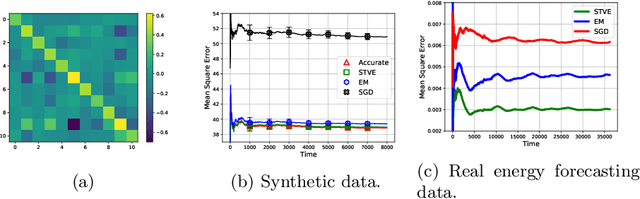
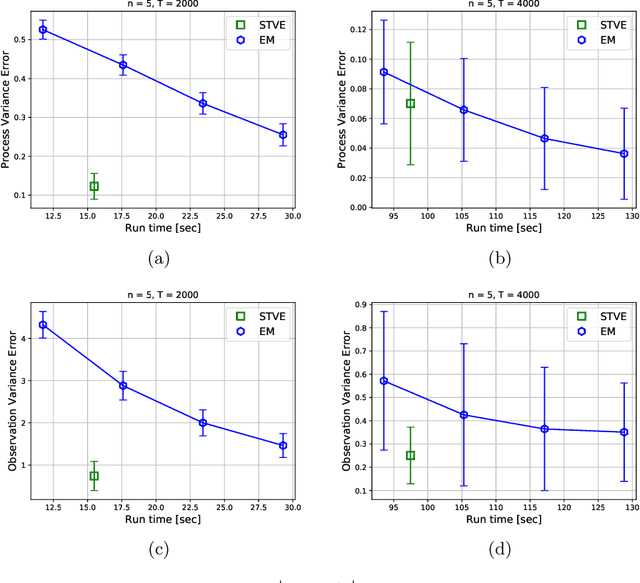
We consider the online linear regression problem, where the predictor vector may vary with time. This problem can be modelled as a linear dynamical system, where the parameters that need to be learned are the variance of both the process noise and the observation noise. The classical approach to learning the variance is via the maximum likelihood estimator -- a non-convex optimization problem prone to local minima and with no finite sample complexity bounds. In this paper we study the global system operator: the operator that maps the noises vectors to the output. In particular, we obtain estimates on its spectrum, and as a result derive the first known variance estimators with sample complexity guarantees for online regression problems. We demonstrate the approach on a number of synthetic and real-world benchmarks.