 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling via Full Dependence Mixtures
Jun 13, 2019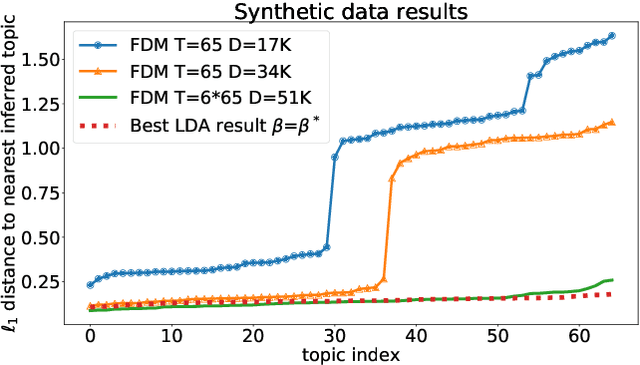
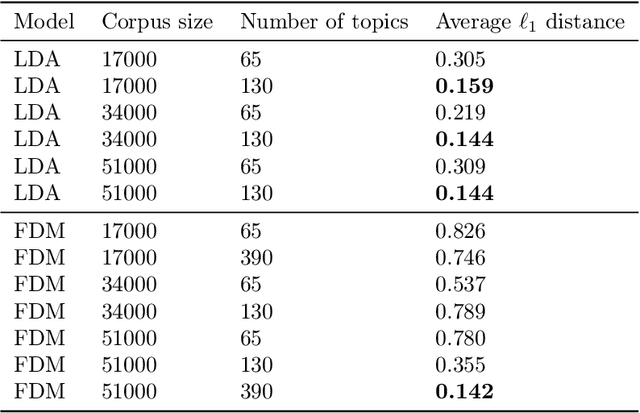
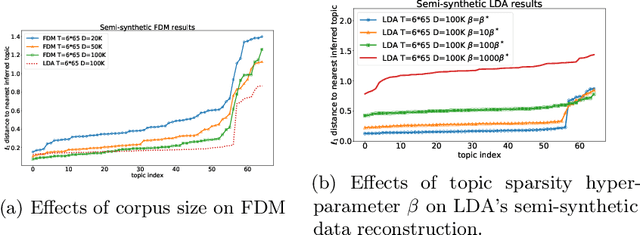
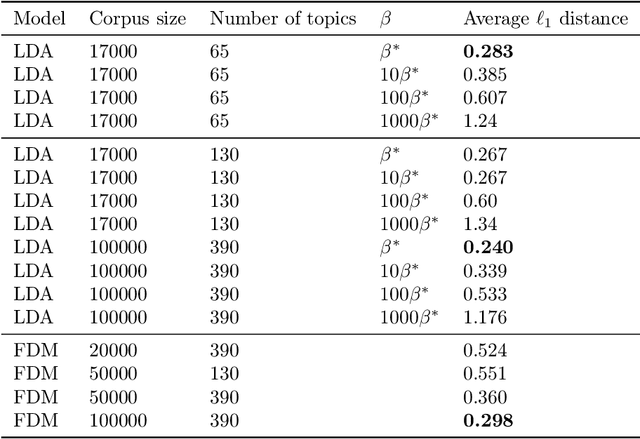
We consider the topic modeling problem for large datasets. For this problem, Latent Dirichlet Allocation (LDA) with a collapsed Gibbs sampler optimization is the state-of-the-art approach in terms of topic quality. However, LDA is a slow approach, and running it on large datasets is impractical even with modern hardware. In this paper we propose to fit topics directly to the co-occurances data of the corpus. In particular, we introduce an extension of a mixture model, the Full Dependence Mixture (FDM), which arises naturally as a model of a second moment under general generative assumptions on the data. While there is some previous work on topic modeling using second moments, we develop a direct stochastic optimization procedure for fitting an FDM with a single Kullback Leibler objective. While moment methods in general have the benefit that an iteration no longer needs to scale with the size of the corpus, our approach also allows us to leverage standard optimizers and GPUs for the problem of topic modeling. We evaluate the approach on synthetic and semi-synthetic data, as well as on the SOTU and Neurips Papers corpora, and show that the approach outperforms LDA, where LDA is run on both full and sub-sampled data.