 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree approaches to facilitate DNN generalization to objects in out-of-distribution orientations and illuminations: late-stopping, tuning batch normalization and invariance loss
Oct 30, 2021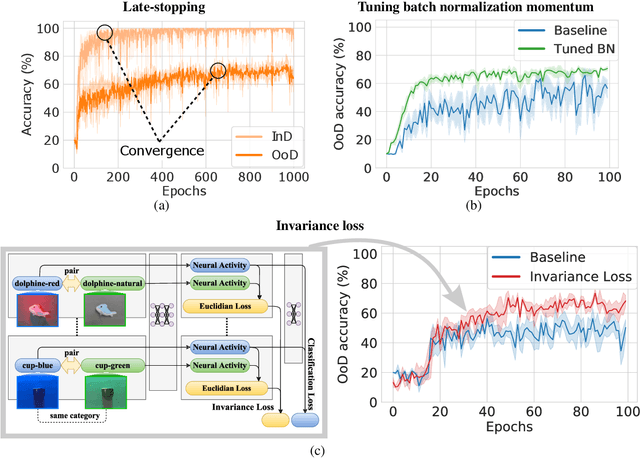



The training data distribution is often biased towards objects in certain orientations and illumination conditions. While humans have a remarkable capability of recognizing objects in out-of-distribution (OoD) orientations and illuminations, Deep Neural Networks (DNNs) severely suffer in this case, even when large amounts of training examples are available. In this paper, we investigate three different approaches to improve DNNs in recognizing objects in OoD orientations and illuminations. Namely, these are (i) training much longer after convergence of the in-distribution (InD) validation accuracy, i.e., late-stopping, (ii) tuning the momentum parameter of the batch normalization layers, and (iii) enforcing invariance of the neural activity in an intermediate layer to orientation and illumination conditions. Each of these approaches substantially improves the DNN's OoD accuracy (more than 20% in some cases). We report results in four datasets: two datasets are modified from the MNIST and iLab datasets, and the other two are novel (one of 3D rendered cars and another of objects taken from various controlled orientations and illumination conditions). These datasets allow to study the effects of different amounts of bias and are challenging as DNNs perform poorly in OoD conditions. Finally, we demonstrate that even though the three approaches focus on different aspects of DNNs, they all tend to lead to the same underlying neural mechanism to enable OoD accuracy gains -- individual neurons in the intermediate layers become more selective to a category and also invariant to OoD orientations and illuminations.
Annotation Cost Reduction of Stream-based Active Learning by Automated Weak Labeling using a Robot Arm
Oct 03, 2021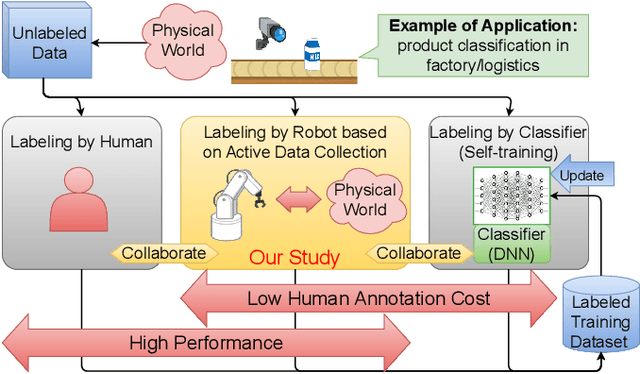
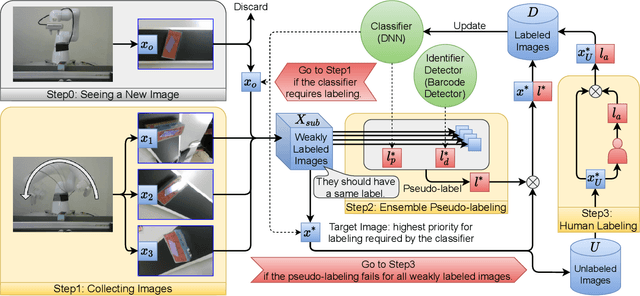


Stream-based active learning (AL) is an efficient training data collection method, and it is used to reduce human annotation cost required in machine learning. However, it is difficult to say that the human cost is low enough because most previous studies have assumed that an oracle is a human with domain knowledge. In this study, we propose a method to replace a part of the oracle's work in stream-based AL by self-training with weak labeling using a robot arm. A camera attached to a robot arm takes a series of image data related to a streamed object, which should have the same label. We use this information as a weak label to connect a pseudo-label (estimated class label) and a target instance. Our method selects two data from a series of image data; high confidence data for correcting pseudo-labels and low confidence data for improving the performance of the classifier. We paired a pseudo-label provided to high confidence data with a target instance (low confidence data). By using this technique, we mitigate the inefficiency in self-training, that is, difficulty in creating pseudo-labeled training data with a high impact on the target classifier. In the experiments, we employed the proposed method in the classification task of objects on a belt conveyor. We evaluated the performance against human cost on multiple scenarios considering the temporal variation of data. The proposed method achieves the same or better performance as the conventional methods while reducing human cost.
Selective Forgetting of Deep Networks at a Finer Level than Samples
Dec 31, 2020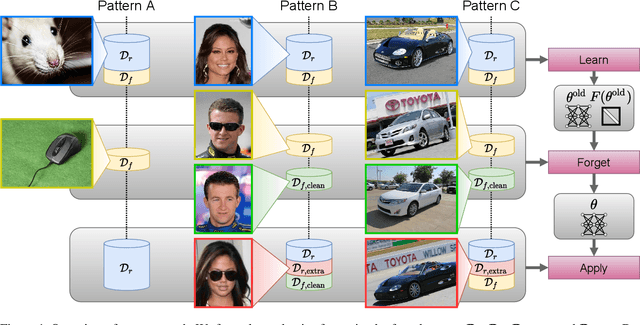
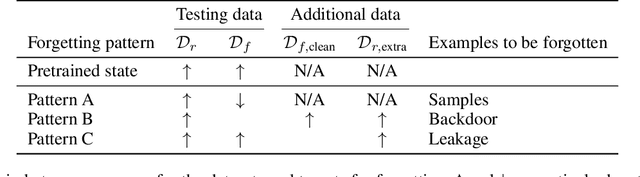

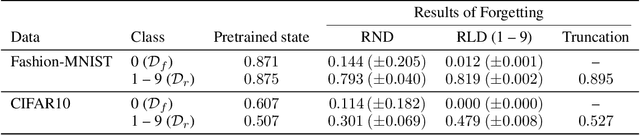
Selective forgetting or removing information from deep neural networks (DNNs) is essential for continual learning and is challenging in controlling the DNNs. Such forgetting is crucial also in a practical sense since the deployed DNNs may be trained on the data with outliers, poisoned by attackers, or with leaked/sensitive information. In this paper, we formulate selective forgetting for classification tasks at a finer level than the samples' level. We specify the finer level based on four datasets distinguished by two conditions: whether they contain information to be forgotten and whether they are available for the forgetting procedure. Additionally, we reveal the need for such formulation with the datasets by showing concrete and practical situations. Moreover, we introduce the forgetting procedure as an optimization problem on three criteria; the forgetting, the correction, and the remembering term. Experimental results show that the proposed methods can make the model forget to use specific information for classification. Notably, in specific cases, our methods improved the model's accuracy on the datasets, which contains information to be forgotten but is unavailable in the forgetting procedure. Such data are unexpectedly found and misclassified in actual situations.
Multi Instance Learning For Unbalanced Data
Dec 17, 2018
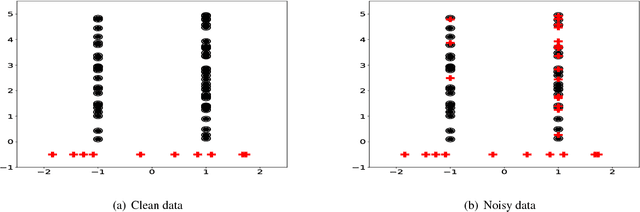
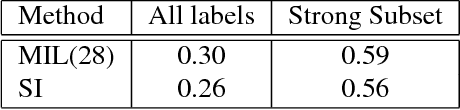
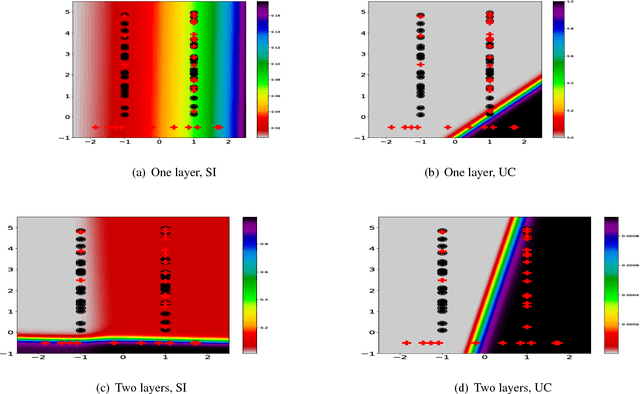
In the context of Multi Instance Learning, we analyze the Single Instance (SI) learning objective. We show that when the data is unbalanced and the family of classifiers is sufficiently rich, the SI method is a useful learning algorithm. In particular, we show that larger data imbalance, a quality that is typically perceived as negative, in fact implies a better resilience of the algorithm to the statistical dependencies of the objects in bags. In addition, our results shed new light on some known issues with the SI method in the setting of linear classifiers, and we show that these issues are significantly less likely to occur in the setting of neural networks. We demonstrate our results on a synthetic dataset, and on the COCO dataset for the problem of patch classification with weak image level labels derived from captions.