 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRAIN: Bias-Mitigation Continual Learning Approach to Vision-Brain Understanding
Aug 25, 2025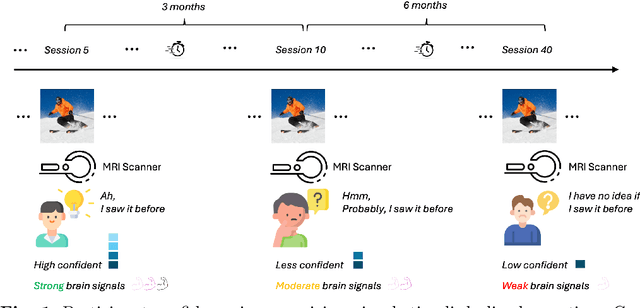
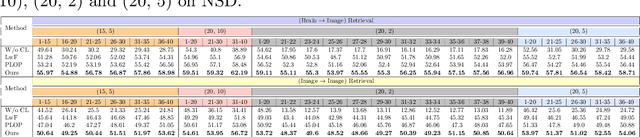
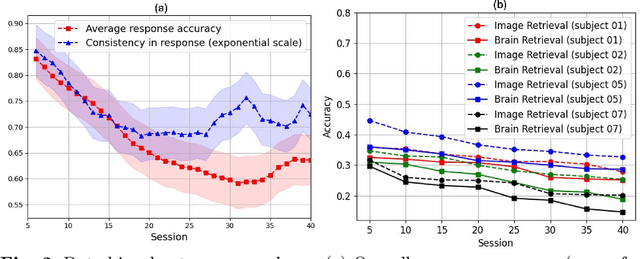
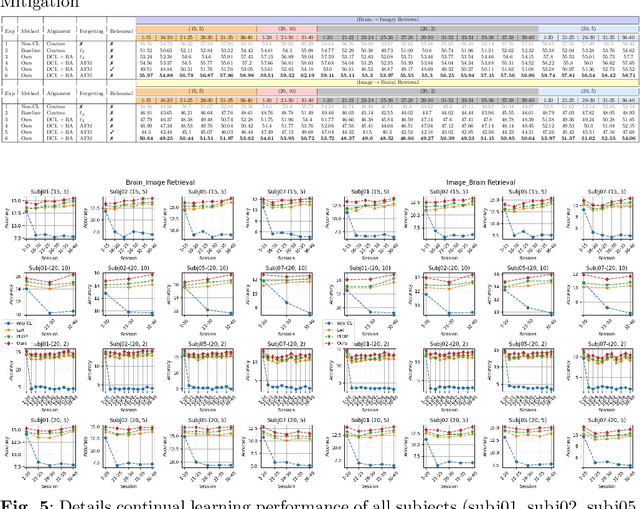
Memory decay makes it harder for the human brain to recognize visual objects and retain details. Consequently, recorded brain signals become weaker, uncertain, and contain poor visual context over time. This paper presents one of the first vision-learning approaches to address this problem. First, we statistically and experimentally demonstrate the existence of inconsistency in brain signals and its impact on the Vision-Brain Understanding (VBU) model. Our findings show that brain signal representations shift over recording sessions, leading to compounding bias, which poses challenges for model learning and degrades performance. Then, we propose a new Bias-Mitigation Continual Learning (BRAIN) approach to address these limitations. In this approach, the model is trained in a continual learning setup and mitigates the growing bias from each learning step. A new loss function named De-bias Contrastive Learning is also introduced to address the bias problem. In addition, to prevent catastrophic forgetting, where the model loses knowledge from previous sessions, the new Angular-based Forgetting Mitigation approach is introduced to preserve learned knowledge in the model. Finally, the empirical experiments demonstrate that our approach achieves State-of-the-Art (SOTA) performance across various benchmarks, surpassing prior and non-continual learning methods.
Uniform Resampling vs. Image Blur: Aliasing Approximation via Isotropic Gaussian Filtering
Feb 17, 2025One of the key approximations to range simulation is downscaling the image, dictated by the natural trigonometric relationships that arise due to long-distance viewing. It is well-known that standard downsampling applied to an image without prior low-pass filtering leads to a type of signal distortion called $aliasing$. In this study, we aim at modeling the distortion due to aliasing and show that a downsampled/upsampled image after an interpolation process can be very well approximated through the application of isotropic Gaussian low-pass filtering to the original image. In other words, the distortion due to aliasing can approximately be generated by low-pass filtering the image with a carefully determined cut-off frequency. We have found that the standard deviation of the isotropic Gaussian kernel $\sigma$ and the reduction factor $m$ (also called downsampling ratio) satisfy an approximate $m \approx 2 \sigma$ relationship. We provide both theoretical and practical arguments using two relatively small face datasets (Chicago DB, LRFID) as well as TinyImageNet to corroborate this empirically observed relationship.
COBRA: A Continual Learning Approach to Vision-Brain Understanding
Nov 25, 2024



Vision-Brain Understanding (VBU) aims to extract visual information perceived by humans from brain activity recorded through functional Magnetic Resonance Imaging (fMRI). Despite notable advancements in recent years, existing studies in VBU continue to face the challenge of catastrophic forgetting, where models lose knowledge from prior subjects as they adapt to new ones. Addressing continual learning in this field is, therefore, essential. This paper introduces a novel framework called Continual Learning for Vision-Brain (COBRA) to address continual learning in VBU. Our approach includes three novel modules: a Subject Commonality (SC) module, a Prompt-based Subject Specific (PSS) module, and a transformer-based module for fMRI, denoted as MRIFormer module. The SC module captures shared vision-brain patterns across subjects, preserving this knowledge as the model encounters new subjects, thereby reducing the impact of catastrophic forgetting. On the other hand, the PSS module learns unique vision-brain patterns specific to each subject. Finally, the MRIFormer module contains a transformer encoder and decoder that learns the fMRI features for VBU from common and specific patterns. In a continual learning setup, COBRA is trained in new PSS and MRIFormer modules for new subjects, leaving the modules of previous subjects unaffected. As a result, COBRA effectively addresses catastrophic forgetting and achieves state-of-the-art performance in both continual learning and vision-brain reconstruction tasks, surpassing previous methods.
Quantum-Brain: Quantum-Inspired Neural Network Approach to Vision-Brain Understanding
Nov 20, 2024



Vision-brain understanding aims to extract semantic information about brain signals from human perceptions. Existing deep learning methods for vision-brain understanding are usually introduced in a traditional learning paradigm missing the ability to learn the connectivities between brain regions. Meanwhile, the quantum computing theory offers a new paradigm for designing deep learning models. Motivated by the connectivities in the brain signals and the entanglement properties in quantum computing, we propose a novel Quantum-Brain approach, a quantum-inspired neural network, to tackle the vision-brain understanding problem. To compute the connectivity between areas in brain signals, we introduce a new Quantum-Inspired Voxel-Controlling module to learn the impact of a brain voxel on others represented in the Hilbert space. To effectively learn connectivity, a novel Phase-Shifting module is presented to calibrate the value of the brain signals. Finally, we introduce a new Measurement-like Projection module to present the connectivity information from the Hilbert space into the feature space. The proposed approach can learn to find the connectivities between fMRI voxels and enhance the semantic information obtained from human perceptions. Our experimental results on the Natural Scene Dataset benchmarks illustrate the effectiveness of the proposed method with Top-1 accuracies of 95.1% and 95.6% on image and brain retrieval tasks and an Inception score of 95.3% on fMRI-to-image reconstruction task. Our proposed quantum-inspired network brings a potential paradigm to solving the vision-brain problems via the quantum computing theory.
Configural processing as an optimized strategy for robust object recognition in neural networks
Jul 18, 2024



Configural processing, the perception of spatial relationships among an object's components, is crucial for object recognition. However, the teleology and underlying neurocomputational mechanisms of such processing are still elusive, notwithstanding decades of research. We hypothesized that processing objects via configural cues provides a more robust means to recognizing them relative to local featural cues. We evaluated this hypothesis by devising identification tasks with composite letter stimuli and comparing different neural network models trained with either only local or configural cues available. We found that configural cues yielded more robust performance to geometric transformations such as rotation or scaling. Furthermore, when both features were simultaneously available, configural cues were favored over local featural cues. Layerwise analysis revealed that the sensitivity to configural cues emerged later relative to local feature cues, possibly contributing to the robustness to pixel-level transformations. Notably, this configural processing occurred in a purely feedforward manner, without the need for recurrent computations. Our findings with letter stimuli were successfully extended to naturalistic face images. Thus, our study provides neurocomputational evidence that configural processing emerges in a na\"ive network based on task contingencies, and is beneficial for robust object processing under varying viewing conditions.
BRACTIVE: A Brain Activation Approach to Human Visual Brain Learning
May 29, 2024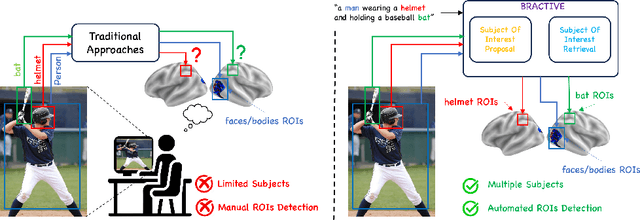
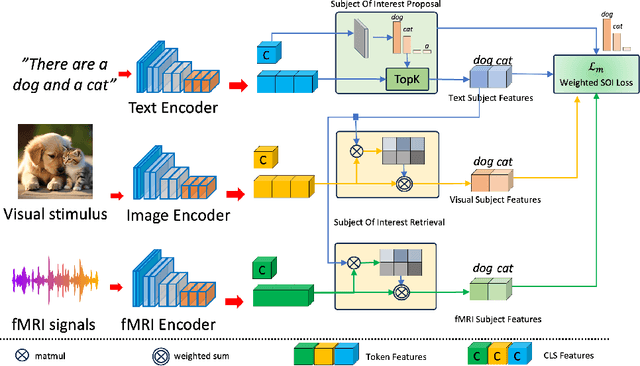

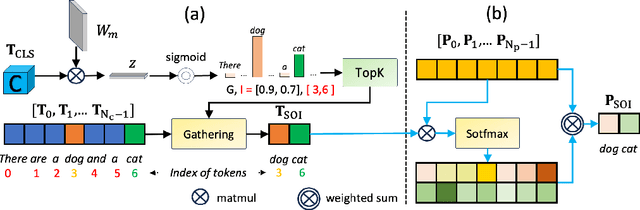
The human brain is a highly efficient processing unit, and understanding how it works can inspire new algorithms and architectures in machine learning. In this work, we introduce a novel framework named Brain Activation Network (BRACTIVE), a transformer-based approach to studying the human visual brain. The main objective of BRACTIVE is to align the visual features of subjects with corresponding brain representations via fMRI signals. It allows us to identify the brain's Regions of Interest (ROI) of the subjects. Unlike previous brain research methods, which can only identify ROIs for one subject at a time and are limited by the number of subjects, BRACTIVE automatically extends this identification to multiple subjects and ROIs. Our experiments demonstrate that BRACTIVE effectively identifies person-specific regions of interest, such as face and body-selective areas, aligning with neuroscience findings and indicating potential applicability to various object categories. More importantly, we found that leveraging human visual brain activity to guide deep neural networks enhances performance across various benchmarks. It encourages the potential of BRACTIVE in both neuroscience and machine intelligence studies.
Information Transfer Rate in BCIs: Towards Tightly Integrated Symbiosis
Jan 03, 2023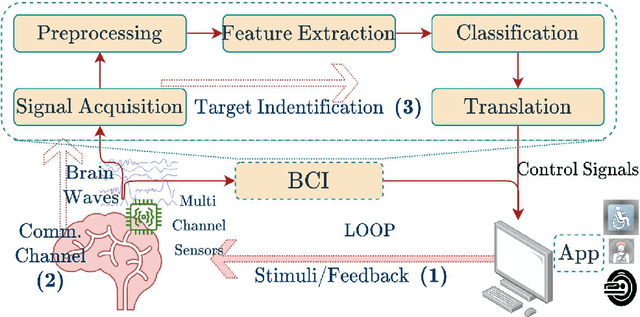
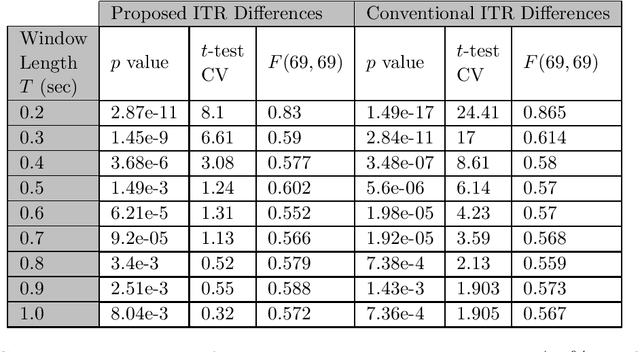

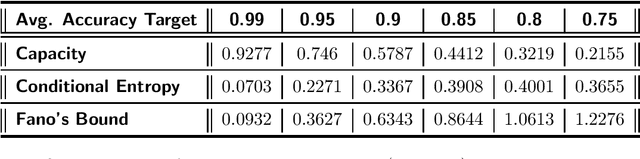
Information Transfer Rate (ITR) is a widely used information measurement metric, particularly popularized for SSVEP-based Brain-Computer (BCI) interfaces. By combining speed and accuracy into a single-valued parameter, this metric aids in the evaluation and comparison of various target identification algorithms across different BCI communities. To accurately depict performance and inspire an end-to-end design for futuristic BCI designs, a more thorough examination and definition of ITR is therefore required. We model the symbiotic communication medium, hosted by the retinogeniculate visual pathway, as a discrete memoryless channel and use the modified capacity expressions to redefine the ITR. We use graph theory to characterize the relationship between the asymmetry of the transition statistics and the ITR gain with the new definition, leading to potential bounds on data rate performance. On two well-known SSVEP datasets, we compared two cutting-edge target identification methods. Results indicate that the induced DM channel asymmetry has a greater impact on the actual perceived ITR than the change in input distribution. Moreover, it is demonstrated that the ITR gain under the new definition is inversely correlated with the asymmetry in the channel transition statistics. Individual input customizations are further shown to yield perceived ITR performance improvements. An algorithm is proposed to find the capacity of binary classification and further discussions are given to extend such results to ensemble techniques.We anticipate that the results of our study will contribute to the characterization of the highly dynamic BCI channel capacities, performance thresholds, and improved BCI stimulus designs for a tighter symbiosis between the human brain and computer systems while enhancing the efficiency of the underlying communication resources.
Neural Correlates of Face Familiarity Perception
Jul 31, 2022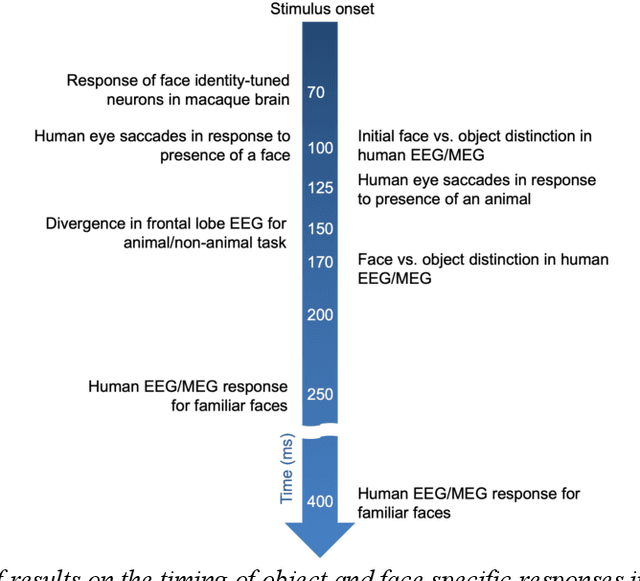
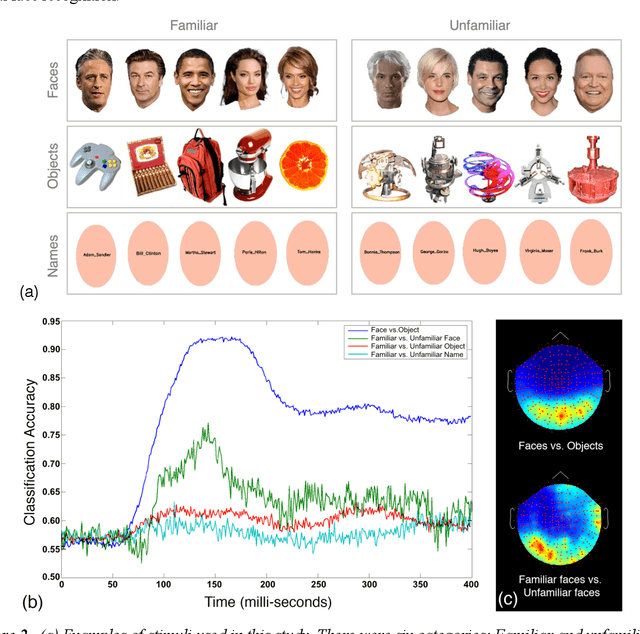
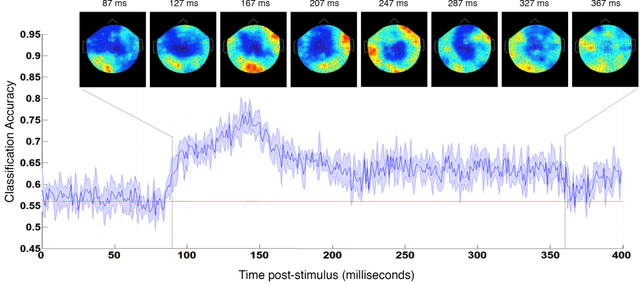
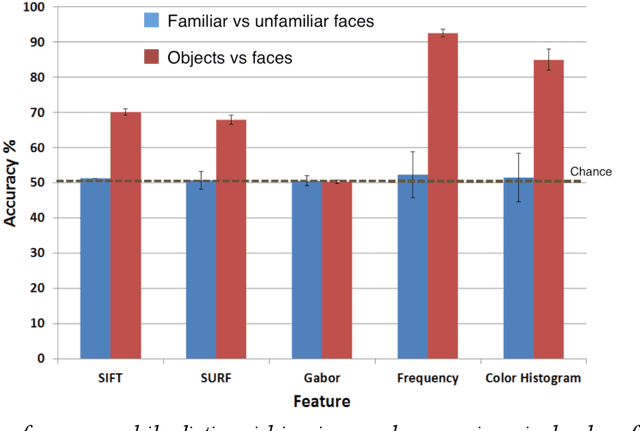
In the domain of face recognition, there exists a puzzling timing discrepancy between results from macaque neurophysiology on the one hand and human electrophysiology on the other. Single unit recordings in macaques have demonstrated face identity specific responses in extra-striate visual cortex within 100 milliseconds of stimulus onset. In EEG and MEG experiments with humans, however, a consistent distinction between neural activity corresponding to unfamiliar and familiar faces has been reported to emerge around 250 ms. This points to the possibility that there may be a hitherto undiscovered early correlate of face familiarity perception in human electrophysiological traces. We report here a successful search for such a correlate in dense MEG recordings using pattern classification techniques. Our analyses reveal markers of face familiarity as early as 85 ms after stimulus onset. Low-level attributes of the images, such as luminance and color distributions, are unable to account for this early emerging response difference. These results help reconcile human and macaque data, and provide clues regarding neural mechanisms underlying familiar face perception.
Three approaches to facilitate DNN generalization to objects in out-of-distribution orientations and illuminations: late-stopping, tuning batch normalization and invariance loss
Oct 30, 2021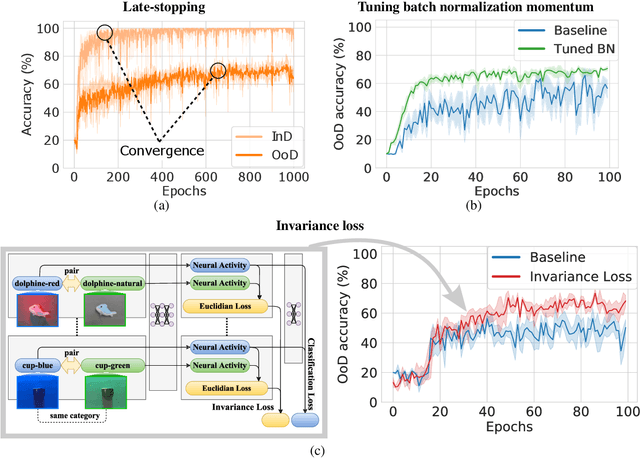



The training data distribution is often biased towards objects in certain orientations and illumination conditions. While humans have a remarkable capability of recognizing objects in out-of-distribution (OoD) orientations and illuminations, Deep Neural Networks (DNNs) severely suffer in this case, even when large amounts of training examples are available. In this paper, we investigate three different approaches to improve DNNs in recognizing objects in OoD orientations and illuminations. Namely, these are (i) training much longer after convergence of the in-distribution (InD) validation accuracy, i.e., late-stopping, (ii) tuning the momentum parameter of the batch normalization layers, and (iii) enforcing invariance of the neural activity in an intermediate layer to orientation and illumination conditions. Each of these approaches substantially improves the DNN's OoD accuracy (more than 20% in some cases). We report results in four datasets: two datasets are modified from the MNIST and iLab datasets, and the other two are novel (one of 3D rendered cars and another of objects taken from various controlled orientations and illumination conditions). These datasets allow to study the effects of different amounts of bias and are challenging as DNNs perform poorly in OoD conditions. Finally, we demonstrate that even though the three approaches focus on different aspects of DNNs, they all tend to lead to the same underlying neural mechanism to enable OoD accuracy gains -- individual neurons in the intermediate layers become more selective to a category and also invariant to OoD orientations and illuminations.
To Which Out-Of-Distribution Object Orientations Are DNNs Capable of Generalizing?
Sep 28, 2021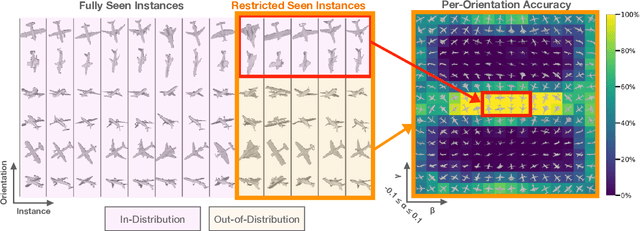
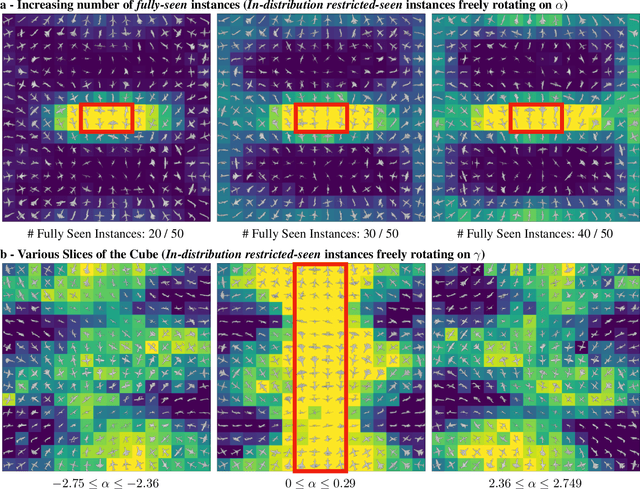

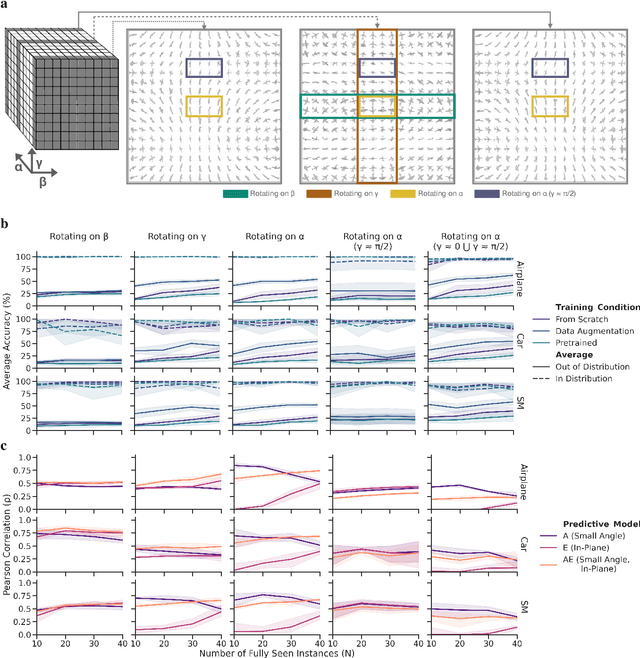
The capability of Deep Neural Networks (DNNs) to recognize objects in orientations outside the distribution of the training data, ie. out-of-distribution (OoD) orientations, is not well understood. For humans, behavioral studies showed that recognition accuracy varies across OoD orientations, where generalization is much better for some orientations than for others. In contrast, for DNNs, it remains unknown how generalization abilities are distributed among OoD orientations. In this paper, we investigate the limitations of DNNs' generalization capacities by systematically inspecting patterns of success and failure of DNNs across OoD orientations. We use an intuitive and controlled, yet challenging learning paradigm, in which some instances of an object category are seen at only a few geometrically restricted orientations, while other instances are seen at all orientations. The effect of data diversity is also investigated by increasing the number of instances seen at all orientations in the training set. We present a comprehensive analysis of DNNs' generalization abilities and limitations for representative architectures (ResNet, Inception, DenseNet and CORnet). Our results reveal an intriguing pattern -- DNNs are only capable of generalizing to instances of objects that appear like 2D, ie. in-plane, rotations of in-distribution orientations.