 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3: Data Diversity Design for Systematic Generalization in Visual Question Answering
Sep 15, 2023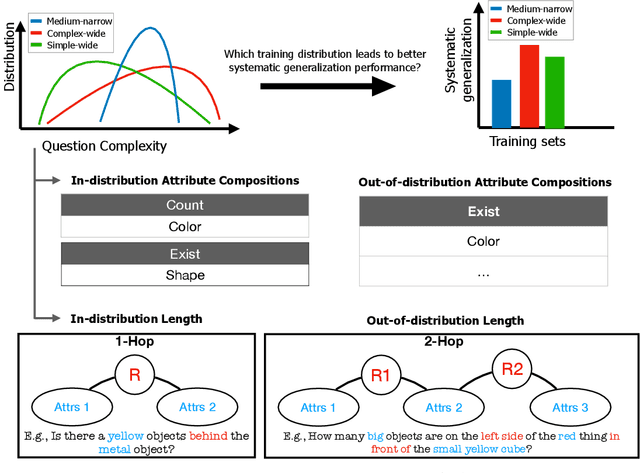


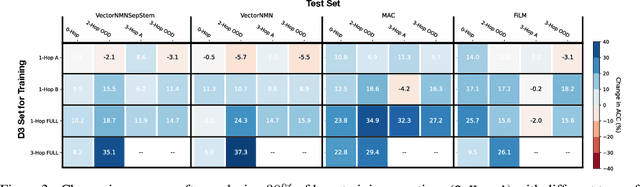
Systematic generalization is a crucial aspect of intelligence, which refers to the ability to generalize to novel tasks by combining known subtasks and concepts. One critical factor that has been shown to influence systematic generalization is the diversity of training data. However, diversity can be defined in various ways, as data have many factors of variation. A more granular understanding of how different aspects of data diversity affect systematic generalization is lacking. We present new evidence in the problem of Visual Question Answering (VQA) that reveals that the diversity of simple tasks (i.e. tasks formed by a few subtasks and concepts) plays a key role in achieving systematic generalization. This implies that it may not be essential to gather a large and varied number of complex tasks, which could be costly to obtain. We demonstrate that this result is independent of the similarity between the training and testing data and applies to well-known families of neural network architectures for VQA (i.e. monolithic architectures and neural module networks). Additionally, we observe that neural module networks leverage all forms of data diversity we evaluated, while monolithic architectures require more extensive amounts of data to do so. These findings provide a first step towards understanding the interactions between data diversity design, neural network architectures, and systematic generalization capabilities.
Modularity Trumps Invariance for Compositional Robustness
Jun 15, 2023
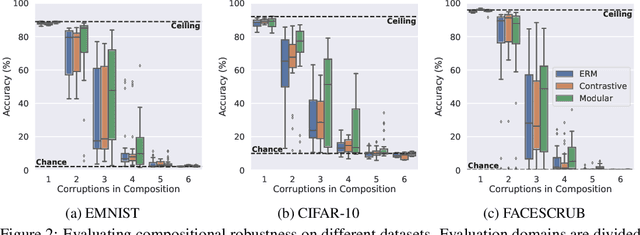
By default neural networks are not robust to changes in data distribution. This has been demonstrated with simple image corruptions, such as blurring or adding noise, degrading image classification performance. Many methods have been proposed to mitigate these issues but for the most part models are evaluated on single corruptions. In reality, visual space is compositional in nature, that is, that as well as robustness to elemental corruptions, robustness to compositions of corruptions is also needed. In this work we develop a compositional image classification task where, given a few elemental corruptions, models are asked to generalize to compositions of these corruptions. That is, to achieve compositional robustness. We experimentally compare empirical risk minimization with an invariance building pairwise contrastive loss and, counter to common intuitions in domain generalization, achieve only marginal improvements in compositional robustness by encouraging invariance. To move beyond invariance, following previously proposed inductive biases that model architectures should reflect data structure, we introduce a modular architecture whose structure replicates the compositional nature of the task. We then show that this modular approach consistently achieves better compositional robustness than non-modular approaches. We additionally find empirical evidence that the degree of invariance between representations of 'in-distribution' elemental corruptions fails to correlate with robustness to 'out-of-distribution' compositions of corruptions.
HICO-DET-SG and V-COCO-SG: New Data Splits to Evaluate Systematic Generalization in Human-Object Interaction Detection
May 17, 2023



Human-Object Interaction (HOI) detection is a task to predict interactions between humans and objects in an image. In real-world scenarios, HOI detection models are required systematic generalization, i.e., generalization to novel combinations of objects and interactions, because it is highly probable that the train data only cover a limited portion of all possible combinations. However, to our knowledge, no open benchmark or existing work evaluates the systematic generalization in HOI detection. To address this issue, we created two new sets of HOI detection data splits named HICO-DET-SG and V-COCO-SG based on HICO-DET and V-COCO datasets. We evaluated representative HOI detection models on the new data splits and observed large degradation in the test performances compared to those on the original datasets. This result shows that systematic generalization is a challenging goal in HOI detection. We hope our new data splits encourage more research toward this goal.
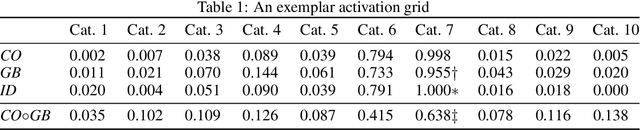
Deephys: Deep Electrophysiology, Debugging Neural Networks under Distribution Shifts
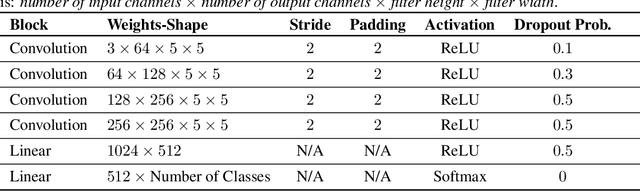
Mar 17, 2023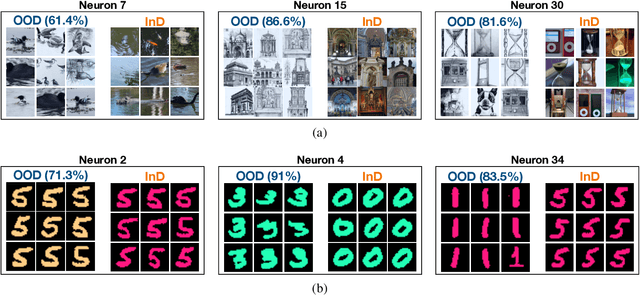
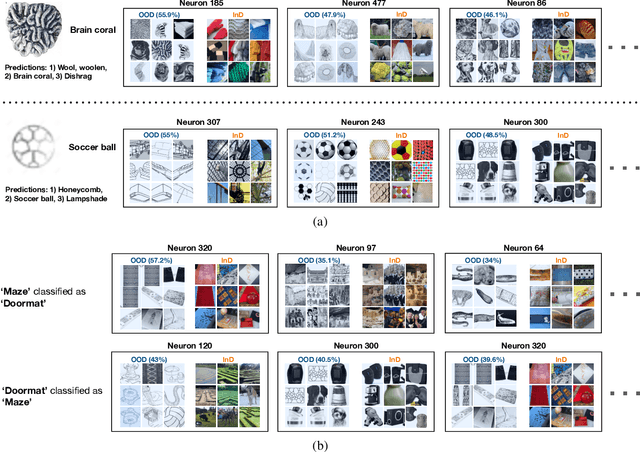
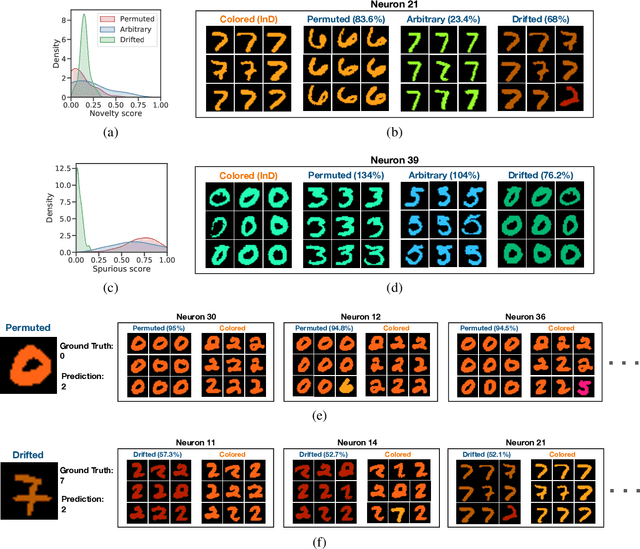
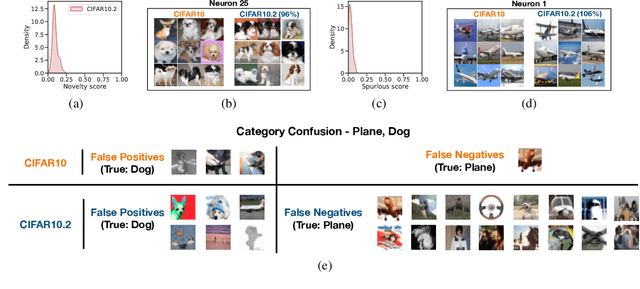
Deep Neural Networks (DNNs) often fail in out-of-distribution scenarios. In this paper, we introduce a tool to visualize and understand such failures. We draw inspiration from concepts from neural electrophysiology, which are based on inspecting the internal functioning of a neural networks by analyzing the feature tuning and invariances of individual units. Deep Electrophysiology, in short Deephys, provides insights of the DNN's failures in out-of-distribution scenarios by comparative visualization of the neural activity in in-distribution and out-of-distribution datasets. Deephys provides seamless analyses of individual neurons, individual images, and a set of set of images from a category, and it is capable of revealing failures due to the presence of spurious features and novel features. We substantiate the validity of the qualitative visualizations of Deephys thorough quantitative analyses using convolutional and transformers architectures, in several datasets and distribution shifts (namely, colored MNIST, CIFAR-10 and ImageNet).
Safe Exploration Method for Reinforcement Learning under Existence of Disturbance
Sep 30, 2022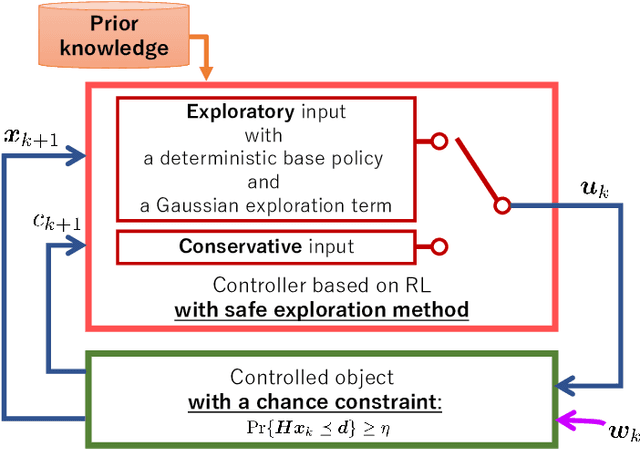
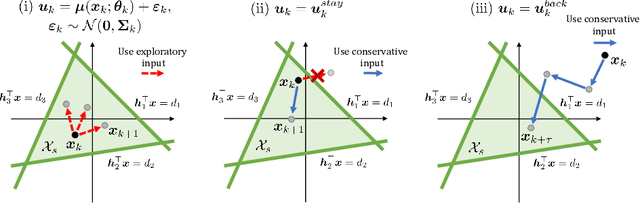
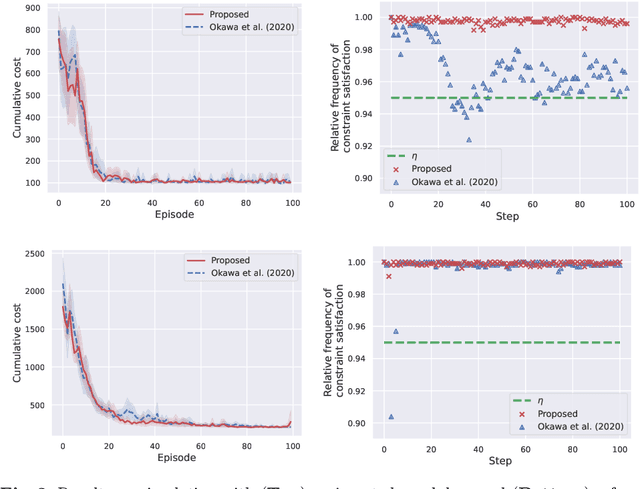

Recent rapid developments in reinforcement learning algorithms have been giving us novel possibilities in many fields. However, due to their exploring property, we have to take the risk into consideration when we apply those algorithms to safety-critical problems especially in real environments. In this study, we deal with a safe exploration problem in reinforcement learning under the existence of disturbance. We define the safety during learning as satisfaction of the constraint conditions explicitly defined in terms of the state and propose a safe exploration method that uses partial prior knowledge of a controlled object and disturbance. The proposed method assures the satisfaction of the explicit state constraints with a pre-specified probability even if the controlled object is exposed to a stochastic disturbance following a normal distribution. As theoretical results, we introduce sufficient conditions to construct conservative inputs not containing an exploring aspect used in the proposed method and prove that the safety in the above explained sense is guaranteed with the proposed method. Furthermore, we illustrate the validity and effectiveness of the proposed method through numerical simulations of an inverted pendulum and a four-bar parallel link robot manipulator.
Transformer Module Networks for Systematic Generalization in Visual Question Answering
Jan 27, 2022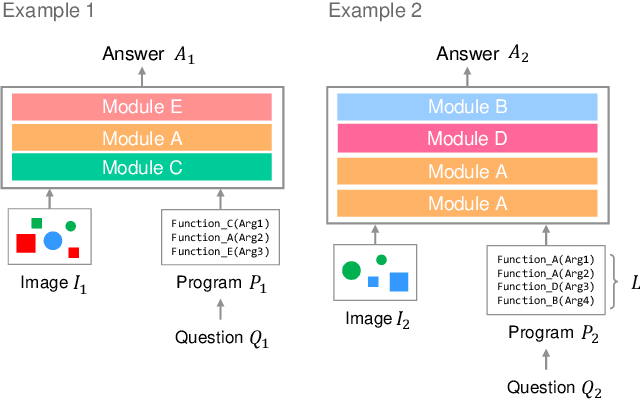
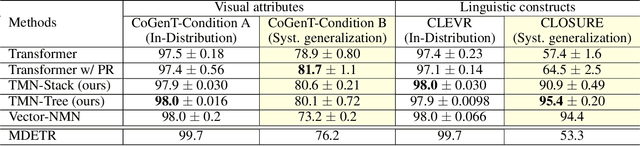
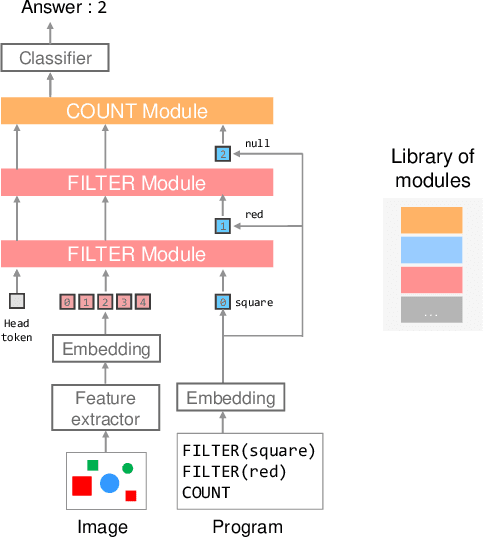

Transformer-based models achieve great performance on Visual Question Answering (VQA). However, when we evaluate them on systematic generalization, i.e., handling novel combinations of known concepts, their performance degrades. Neural Module Networks (NMNs) are a promising approach for systematic generalization that consists on composing modules, i.e., neural networks that tackle a sub-task. Inspired by Transformers and NMNs, we propose Transformer Module Network (TMN), a novel Transformer-based model for VQA that dynamically composes modules into a question-specific Transformer network. TMNs achieve state-of-the-art systematic generalization performance in three VQA datasets, namely, CLEVR-CoGenT, CLOSURE and GQA-SGL, in some cases improving more than 30% over standard Transformers.
Do Neural Networks for Segmentation Understand Insideness?
Jan 25, 2022The insideness problem is an aspect of image segmentation that consists of determining which pixels are inside and outside a region. Deep Neural Networks (DNNs) excel in segmentation benchmarks, but it is unclear if they have the ability to solve the insideness problem as it requires evaluating long-range spatial dependencies. In this paper, the insideness problem is analysed in isolation, without texture or semantic cues, such that other aspects of segmentation do not interfere in the analysis. We demonstrate that DNNs for segmentation with few units have sufficient complexity to solve insideness for any curve. Yet, such DNNs have severe problems with learning general solutions. Only recurrent networks trained with small images learn solutions that generalize well to almost any curve. Recurrent networks can decompose the evaluation of long-range dependencies into a sequence of local operations, and learning with small images alleviates the common difficulties of training recurrent networks with a large number of unrolling steps.
Symmetry Perception by Deep Networks: Inadequacy of Feed-Forward Architectures and Improvements with Recurrent Connections
Dec 08, 2021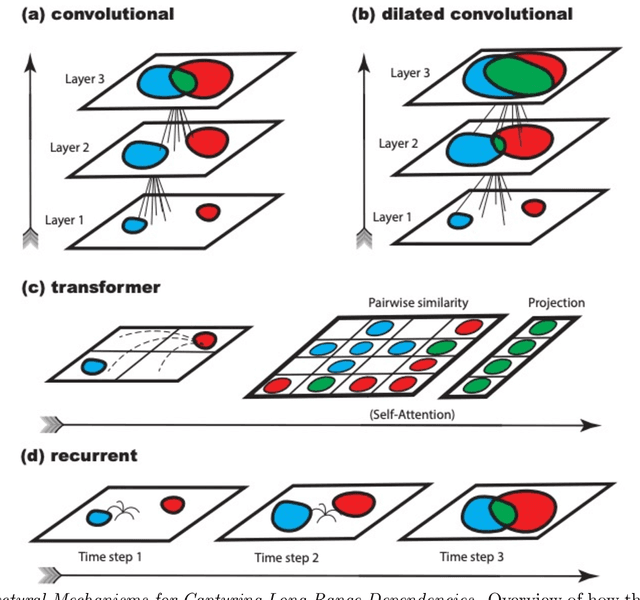

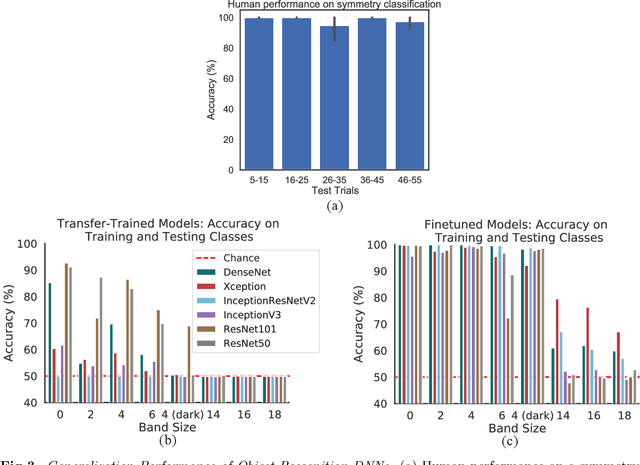
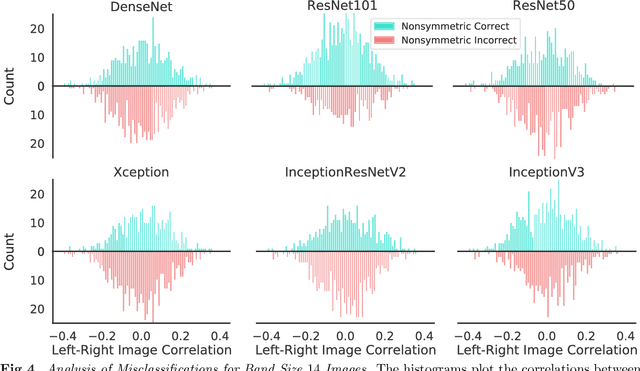
Symmetry is omnipresent in nature and perceived by the visual system of many species, as it facilitates detecting ecologically important classes of objects in our environment. Symmetry perception requires abstraction of non-local spatial dependencies between image regions, and its underlying neural mechanisms remain elusive. In this paper, we evaluate Deep Neural Network (DNN) architectures on the task of learning symmetry perception from examples. We demonstrate that feed-forward DNNs that excel at modelling human performance on object recognition tasks, are unable to acquire a general notion of symmetry. This is the case even when the DNNs are architected to capture non-local spatial dependencies, such as through `dilated' convolutions and the recently introduced `transformers' design. By contrast, we find that recurrent architectures are capable of learning to perceive symmetry by decomposing the non-local spatial dependencies into a sequence of local operations, that are reusable for novel images. These results suggest that recurrent connections likely play an important role in symmetry perception in artificial systems, and possibly, biological ones too.
Three approaches to facilitate DNN generalization to objects in out-of-distribution orientations and illuminations: late-stopping, tuning batch normalization and invariance loss
Oct 30, 2021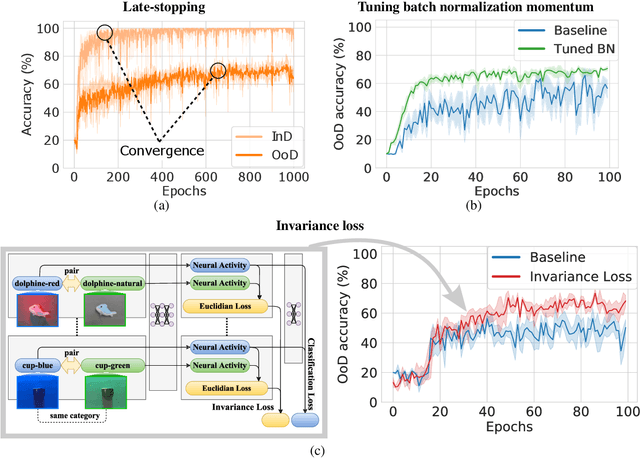



The training data distribution is often biased towards objects in certain orientations and illumination conditions. While humans have a remarkable capability of recognizing objects in out-of-distribution (OoD) orientations and illuminations, Deep Neural Networks (DNNs) severely suffer in this case, even when large amounts of training examples are available. In this paper, we investigate three different approaches to improve DNNs in recognizing objects in OoD orientations and illuminations. Namely, these are (i) training much longer after convergence of the in-distribution (InD) validation accuracy, i.e., late-stopping, (ii) tuning the momentum parameter of the batch normalization layers, and (iii) enforcing invariance of the neural activity in an intermediate layer to orientation and illumination conditions. Each of these approaches substantially improves the DNN's OoD accuracy (more than 20% in some cases). We report results in four datasets: two datasets are modified from the MNIST and iLab datasets, and the other two are novel (one of 3D rendered cars and another of objects taken from various controlled orientations and illumination conditions). These datasets allow to study the effects of different amounts of bias and are challenging as DNNs perform poorly in OoD conditions. Finally, we demonstrate that even though the three approaches focus on different aspects of DNNs, they all tend to lead to the same underlying neural mechanism to enable OoD accuracy gains -- individual neurons in the intermediate layers become more selective to a category and also invariant to OoD orientations and illuminations.
Annotation Cost Reduction of Stream-based Active Learning by Automated Weak Labeling using a Robot Arm
Oct 03, 2021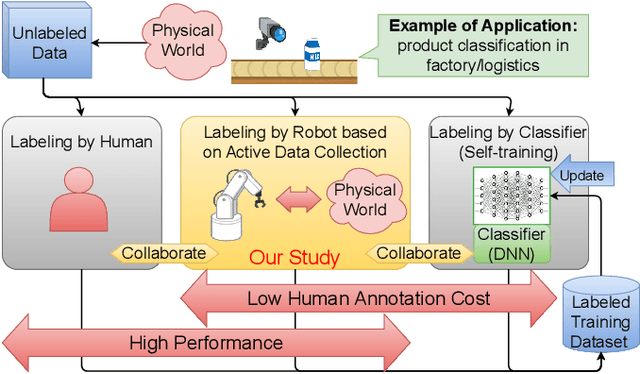
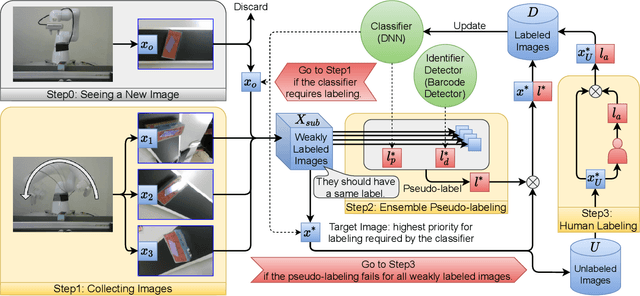


Stream-based active learning (AL) is an efficient training data collection method, and it is used to reduce human annotation cost required in machine learning. However, it is difficult to say that the human cost is low enough because most previous studies have assumed that an oracle is a human with domain knowledge. In this study, we propose a method to replace a part of the oracle's work in stream-based AL by self-training with weak labeling using a robot arm. A camera attached to a robot arm takes a series of image data related to a streamed object, which should have the same label. We use this information as a weak label to connect a pseudo-label (estimated class label) and a target instance. Our method selects two data from a series of image data; high confidence data for correcting pseudo-labels and low confidence data for improving the performance of the classifier. We paired a pseudo-label provided to high confidence data with a target instance (low confidence data). By using this technique, we mitigate the inefficiency in self-training, that is, difficulty in creating pseudo-labeled training data with a high impact on the target classifier. In the experiments, we employed the proposed method in the classification task of objects on a belt conveyor. We evaluated the performance against human cost on multiple scenarios considering the temporal variation of data. The proposed method achieves the same or better performance as the conventional methods while reducing human cost.