 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Exploration Method for Reinforcement Learning under Existence of Disturbance
Sep 30, 2022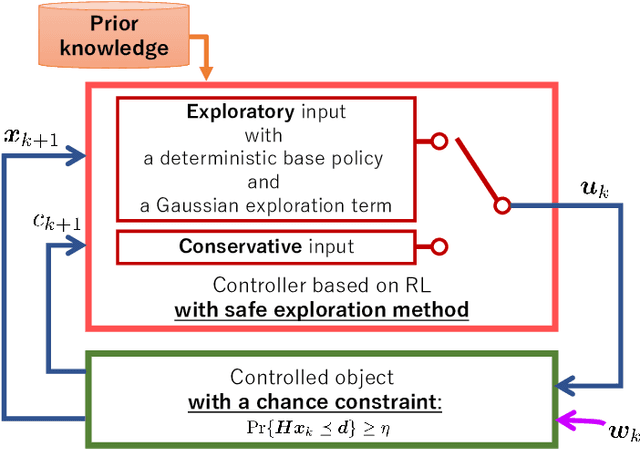
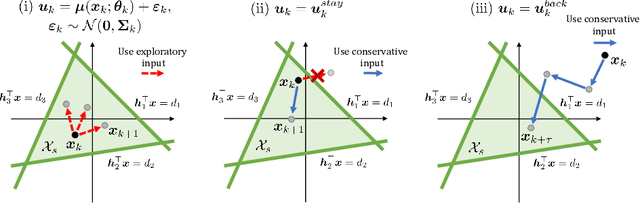
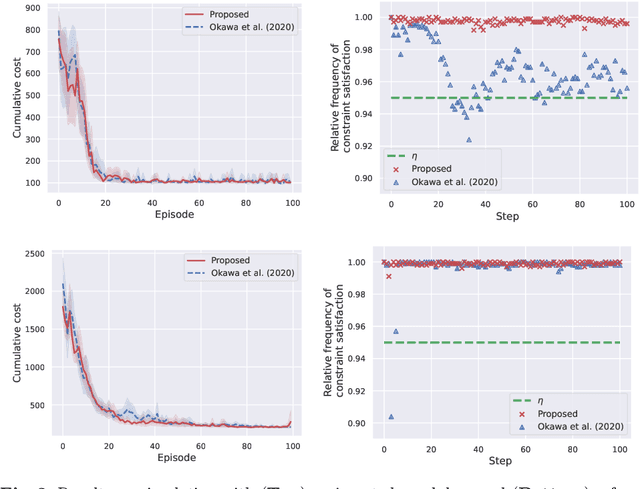

Recent rapid developments in reinforcement learning algorithms have been giving us novel possibilities in many fields. However, due to their exploring property, we have to take the risk into consideration when we apply those algorithms to safety-critical problems especially in real environments. In this study, we deal with a safe exploration problem in reinforcement learning under the existence of disturbance. We define the safety during learning as satisfaction of the constraint conditions explicitly defined in terms of the state and propose a safe exploration method that uses partial prior knowledge of a controlled object and disturbance. The proposed method assures the satisfaction of the explicit state constraints with a pre-specified probability even if the controlled object is exposed to a stochastic disturbance following a normal distribution. As theoretical results, we introduce sufficient conditions to construct conservative inputs not containing an exploring aspect used in the proposed method and prove that the safety in the above explained sense is guaranteed with the proposed method. Furthermore, we illustrate the validity and effectiveness of the proposed method through numerical simulations of an inverted pendulum and a four-bar parallel link robot manipulator.
Model-free two-step design for improving transient learning performance in nonlinear optimal regulator problems
Mar 05, 2021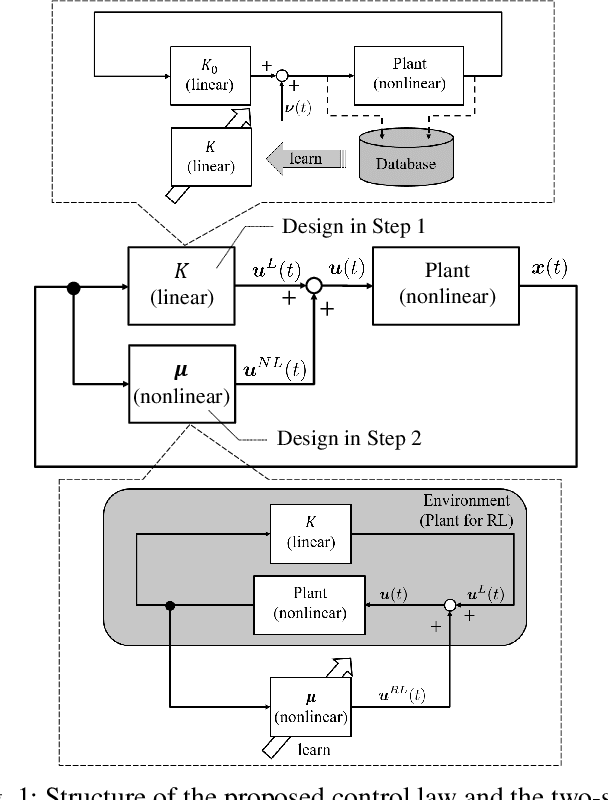
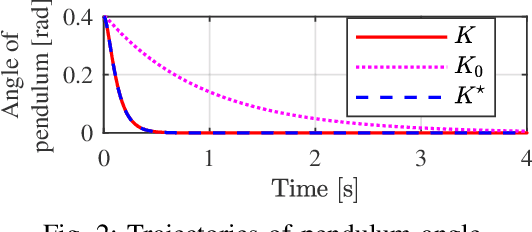
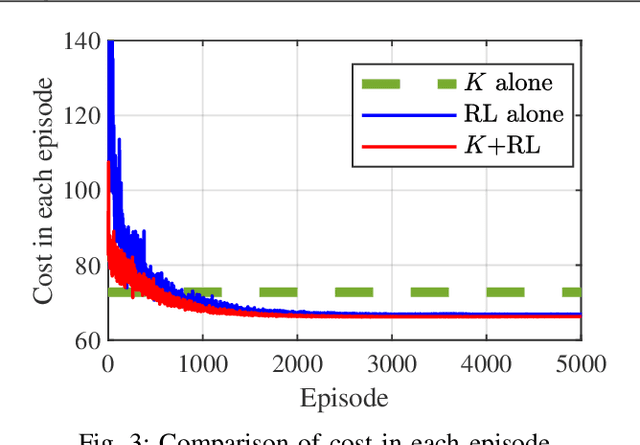

Reinforcement learning (RL) provides a model-free approach to designing an optimal controller for nonlinear dynamical systems. However, the learning process requires a considerable number of trial-and-error experiments using the poorly controlled system, and accumulates wear and tear on the plant. Thus, it is desirable to maintain some degree of control performance during the learning process. In this paper, we propose a model-free two-step design approach to improve the transient learning performance of RL in an optimal regulator design problem for unknown nonlinear systems. Specifically, a linear control law pre-designed in a model-free manner is used in parallel with online RL to ensure a certain level of performance at the early stage of learning. Numerical simulations show that the proposed method improves the transient learning performance and efficiency in hyperparameter tuning of RL.
Automatic Exploration Process Adjustment for Safe Reinforcement Learning with Joint Chance Constraint Satisfaction
Mar 05, 2021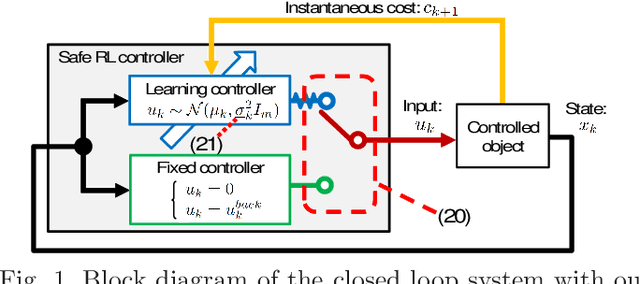

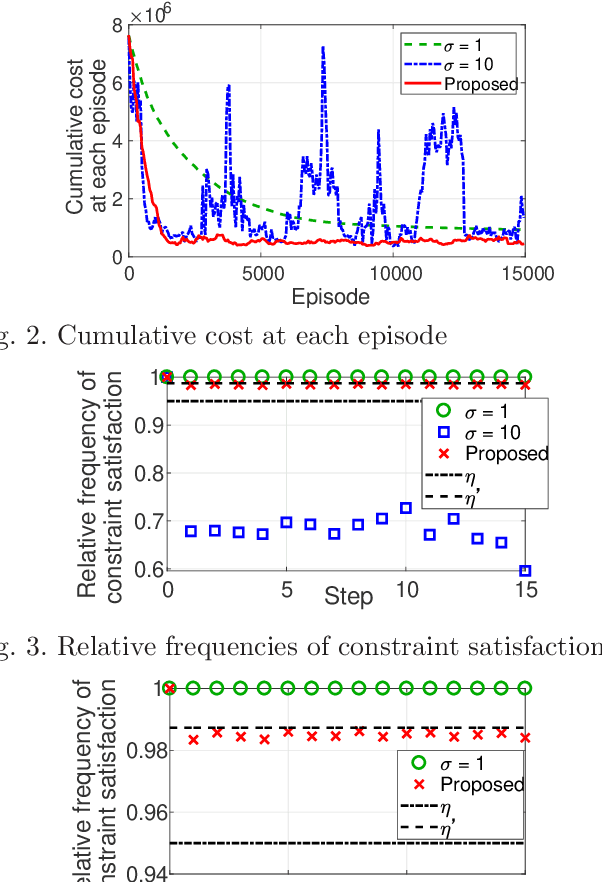
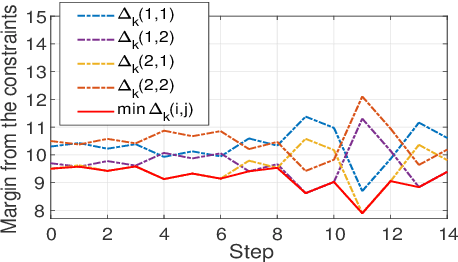
In reinforcement learning (RL) algorithms, exploratory control inputs are used during learning to acquire knowledge for decision making and control, while the true dynamics of a controlled object is unknown. However, this exploring property sometimes causes undesired situations by violating constraints regarding the state of the controlled object. In this paper, we propose an automatic exploration process adjustment method for safe RL in continuous state and action spaces utilizing a linear nominal model of the controlled object. Specifically, our proposed method automatically selects whether the exploratory input is used or not at each time depending on the state and its predicted value as well as adjusts the variance-covariance matrix used in the Gaussian policy for exploration. We also show that our exploration process adjustment method theoretically guarantees the satisfaction of the constraints with the pre-specified probability, that is, the satisfaction of a joint chance constraint at every time. Finally, we illustrate the validity and the effectiveness of our method through numerical simulation.