 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free two-step design for improving transient learning performance in nonlinear optimal regulator problems
Mar 05, 2021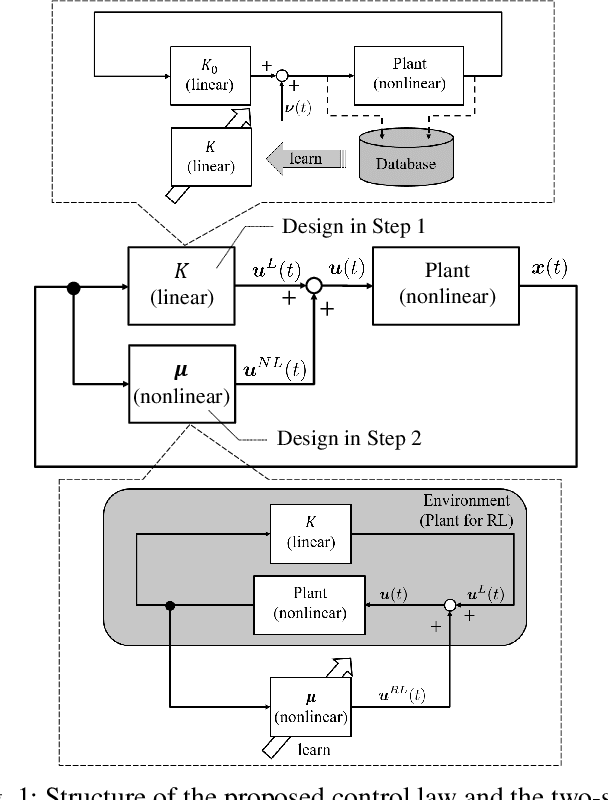
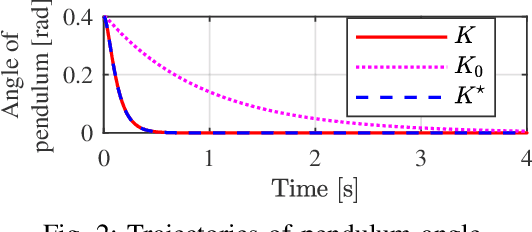
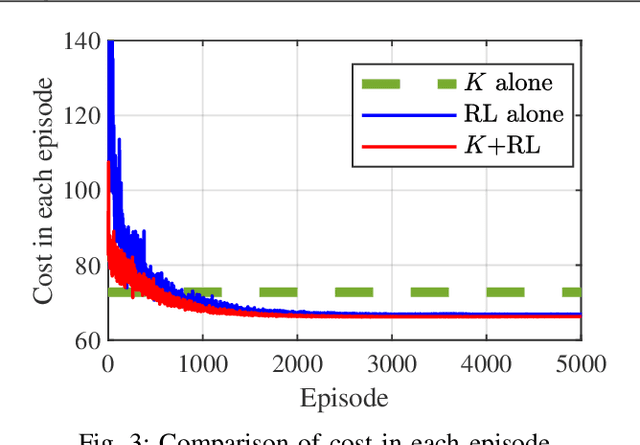

Reinforcement learning (RL) provides a model-free approach to designing an optimal controller for nonlinear dynamical systems. However, the learning process requires a considerable number of trial-and-error experiments using the poorly controlled system, and accumulates wear and tear on the plant. Thus, it is desirable to maintain some degree of control performance during the learning process. In this paper, we propose a model-free two-step design approach to improve the transient learning performance of RL in an optimal regulator design problem for unknown nonlinear systems. Specifically, a linear control law pre-designed in a model-free manner is used in parallel with online RL to ensure a certain level of performance at the early stage of learning. Numerical simulations show that the proposed method improves the transient learning performance and efficiency in hyperparameter tuning of RL.