 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Minimal Model of Bounded Trade-Off Screening in Multi-Attribute Choice
Jun 11, 2026Human decision-making often involves choosing between multi-attribute alternatives, yet classical models assume fully compensatory utility aggregation despite evidence that people reject options with poor performance on critical attributes. We propose a bounded trade-off reasoning framework in which decisions are governed by a screening process that evaluates the balance between gains and losses across attributes. The model introduces a trade-off tolerance parameter that controls acceptable imbalance and can vary across contexts. Through simulation, we show that this mechanism produces preference patterns that differ from standard utility-based models and captures context-dependent variation in trade-off behavior. These results establish bounded trade-off screening as a plausible computational mechanism for multi-attribute choice and generate testable predictions for future behavioral studies.
Modularity Trumps Invariance for Compositional Robustness
Jun 15, 2023
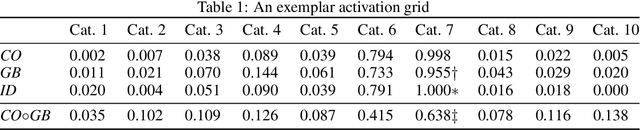
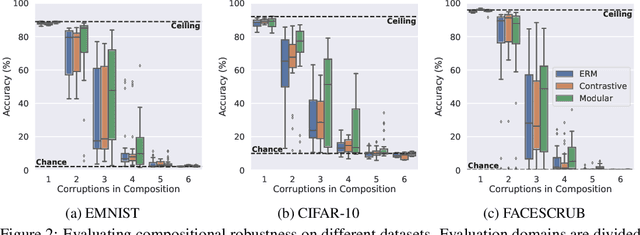
By default neural networks are not robust to changes in data distribution. This has been demonstrated with simple image corruptions, such as blurring or adding noise, degrading image classification performance. Many methods have been proposed to mitigate these issues but for the most part models are evaluated on single corruptions. In reality, visual space is compositional in nature, that is, that as well as robustness to elemental corruptions, robustness to compositions of corruptions is also needed. In this work we develop a compositional image classification task where, given a few elemental corruptions, models are asked to generalize to compositions of these corruptions. That is, to achieve compositional robustness. We experimentally compare empirical risk minimization with an invariance building pairwise contrastive loss and, counter to common intuitions in domain generalization, achieve only marginal improvements in compositional robustness by encouraging invariance. To move beyond invariance, following previously proposed inductive biases that model architectures should reflect data structure, we introduce a modular architecture whose structure replicates the compositional nature of the task. We then show that this modular approach consistently achieves better compositional robustness than non-modular approaches. We additionally find empirical evidence that the degree of invariance between representations of 'in-distribution' elemental corruptions fails to correlate with robustness to 'out-of-distribution' compositions of corruptions.
Deephys: Deep Electrophysiology, Debugging Neural Networks under Distribution Shifts
Mar 17, 2023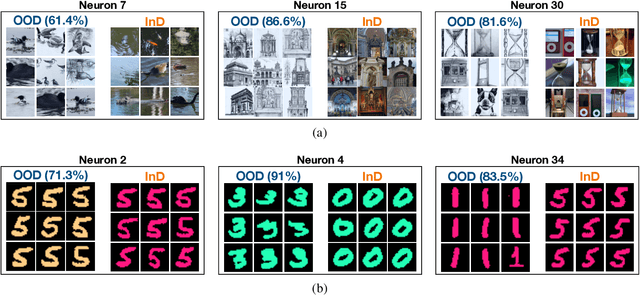
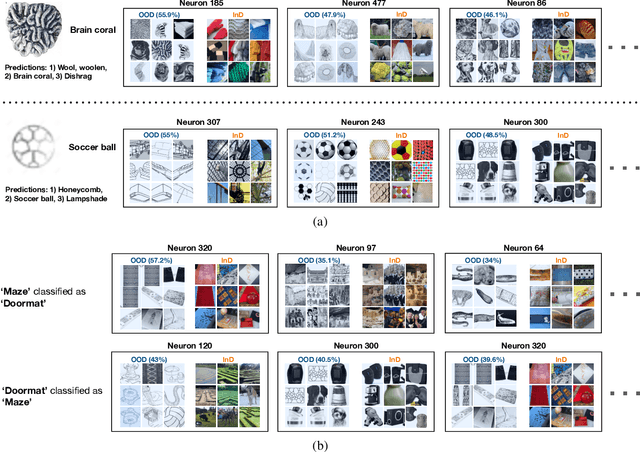
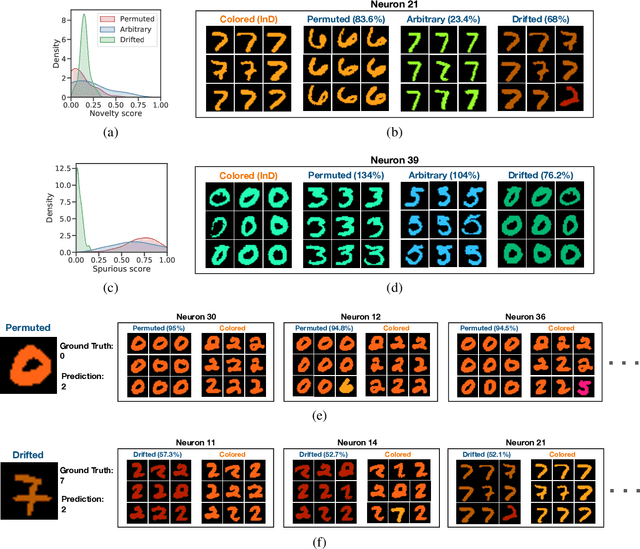
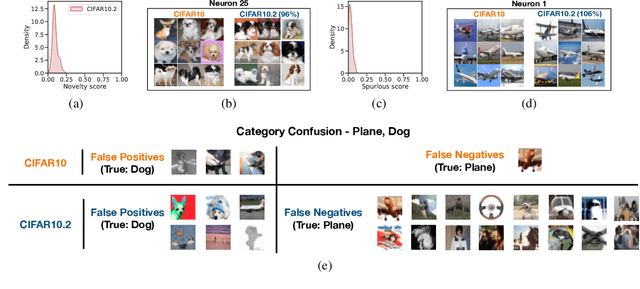
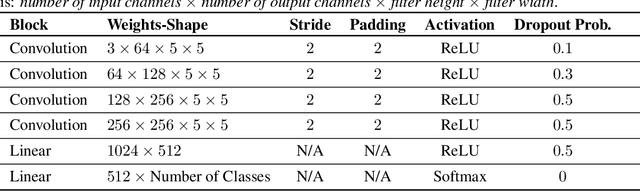
Deep Neural Networks (DNNs) often fail in out-of-distribution scenarios. In this paper, we introduce a tool to visualize and understand such failures. We draw inspiration from concepts from neural electrophysiology, which are based on inspecting the internal functioning of a neural networks by analyzing the feature tuning and invariances of individual units. Deep Electrophysiology, in short Deephys, provides insights of the DNN's failures in out-of-distribution scenarios by comparative visualization of the neural activity in in-distribution and out-of-distribution datasets. Deephys provides seamless analyses of individual neurons, individual images, and a set of set of images from a category, and it is capable of revealing failures due to the presence of spurious features and novel features. We substantiate the validity of the qualitative visualizations of Deephys thorough quantitative analyses using convolutional and transformers architectures, in several datasets and distribution shifts (namely, colored MNIST, CIFAR-10 and ImageNet).
Get Fooled for the Right Reason: Improving Adversarial Robustness through a Teacher-guided Curriculum Learning Approach
Oct 30, 2021
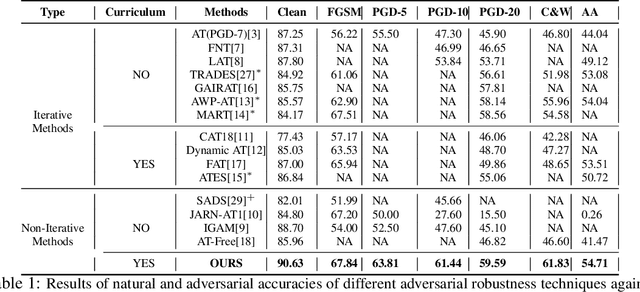

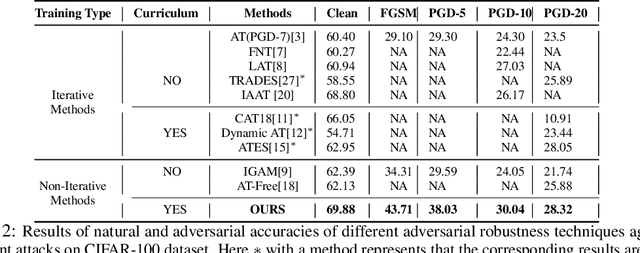
Current SOTA adversarially robust models are mostly based on adversarial training (AT) and differ only by some regularizers either at inner maximization or outer minimization steps. Being repetitive in nature during the inner maximization step, they take a huge time to train. We propose a non-iterative method that enforces the following ideas during training. Attribution maps are more aligned to the actual object in the image for adversarially robust models compared to naturally trained models. Also, the allowed set of pixels to perturb an image (that changes model decision) should be restricted to the object pixels only, which reduces the attack strength by limiting the attack space. Our method achieves significant performance gains with a little extra effort (10-20%) over existing AT models and outperforms all other methods in terms of adversarial as well as natural accuracy. We have performed extensive experimentation with CIFAR-10, CIFAR-100, and TinyImageNet datasets and reported results against many popular strong adversarial attacks to prove the effectiveness of our method.
Inducing Semantic Grouping of Latent Concepts for Explanations: An Ante-Hoc Approach
Aug 25, 2021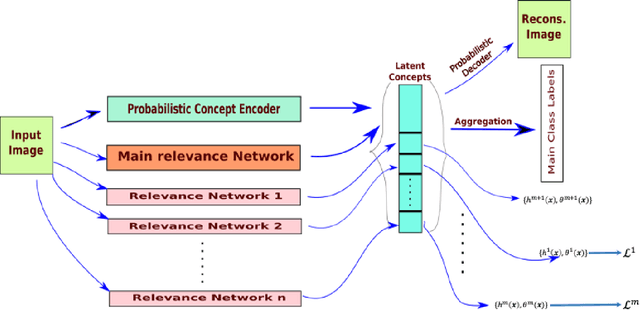

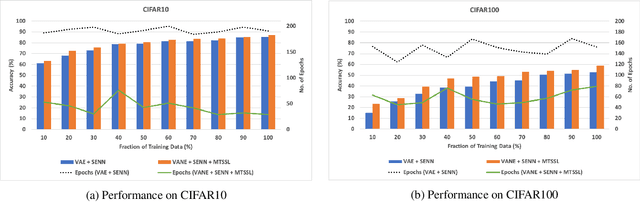

Self-explainable deep models are devised to represent the hidden concepts in the dataset without requiring any posthoc explanation generation technique. We worked with one of such models motivated by explicitly representing the classifier function as a linear function and showed that by exploiting probabilistic latent and properly modifying different parts of the model can result better explanation as well as provide superior predictive performance. Apart from standard visualization techniques, we proposed a new technique which can strengthen human understanding towards hidden concepts. We also proposed a technique of using two different self-supervision techniques to extract meaningful concepts related to the type of self-supervision considered and achieved significant performance boost. The most important aspect of our method is that it works nicely in a low data regime and reaches the desired accuracy in a few number of epochs. We reported exhaustive results with CIFAR10, CIFAR100, and AWA2 datasets to show effect of our method with moderate and relatively complex datasets.
Enhanced Regularizers for Attributional Robustness
Dec 28, 2020
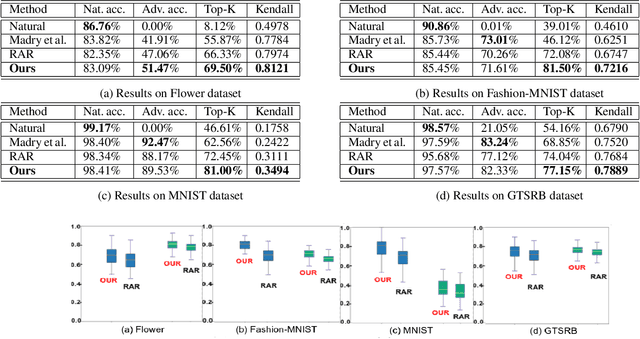
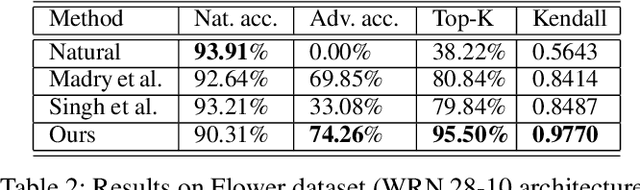
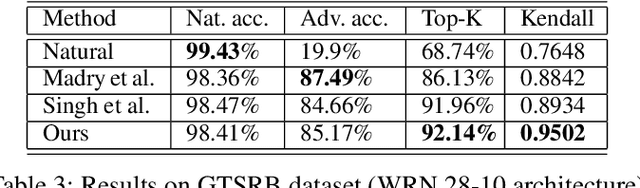
Deep neural networks are the default choice of learning models for computer vision tasks. Extensive work has been carried out in recent years on explaining deep models for vision tasks such as classification. However, recent work has shown that it is possible for these models to produce substantially different attribution maps even when two very similar images are given to the network, raising serious questions about trustworthiness. To address this issue, we propose a robust attribution training strategy to improve attributional robustness of deep neural networks. Our method carefully analyzes the requirements for attributional robustness and introduces two new regularizers that preserve a model's attribution map during attacks. Our method surpasses state-of-the-art attributional robustness methods by a margin of approximately 3% to 9% in terms of attribution robustness measures on several datasets including MNIST, FMNIST, Flower and GTSRB.
Neural Network Attributions: A Causal Perspective
Feb 07, 2019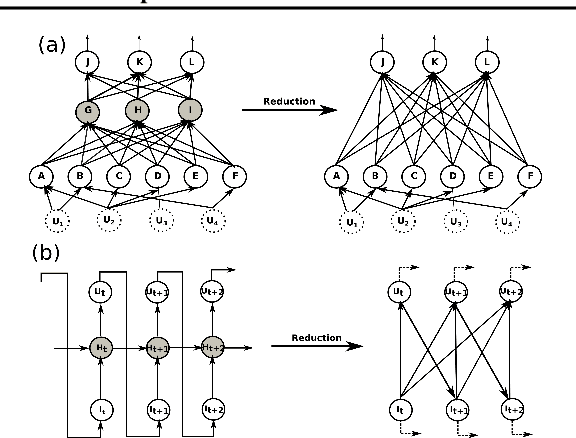
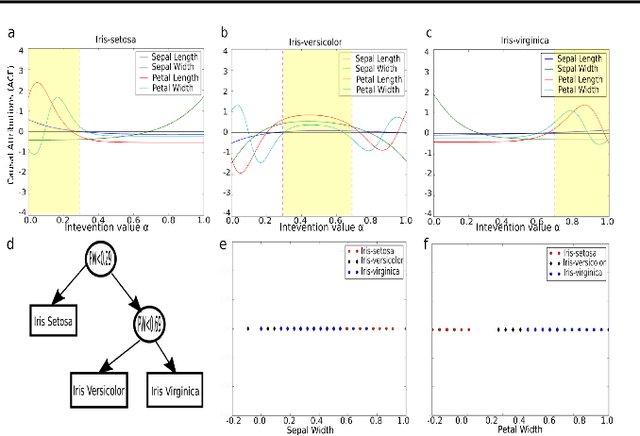
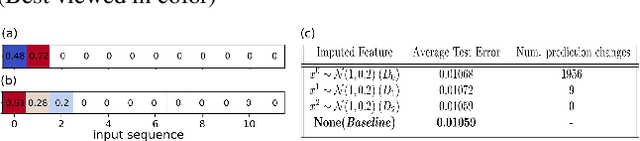
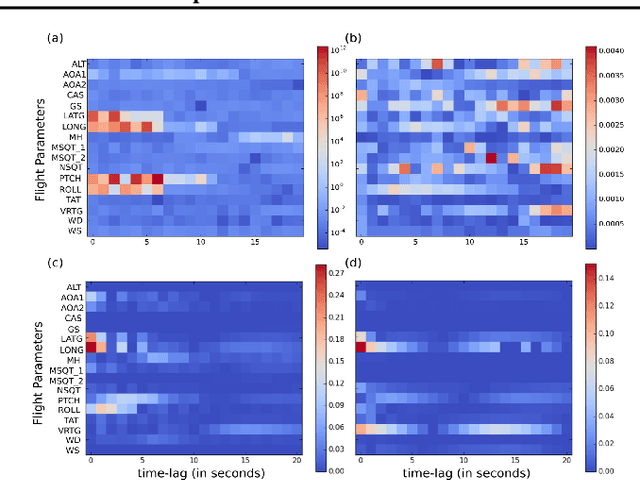
We propose a new attribution method for neural networks developed using first principles of causality (to the best of our knowledge, the first such). The neural network architecture is viewed as a Structural Causal Model, and a methodology to compute the causal effect of each feature on the output is presented. With reasonable assumptions on the causal structure of the input data, we propose algorithms to efficiently compute the causal effects, as well as scale the approach to data with large dimensionality. We also show how this method can be used for recurrent neural networks. We report experimental results on both simulated and real datasets showcasing the promise and usefulness of the proposed algorithm.
Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks
May 08, 2018
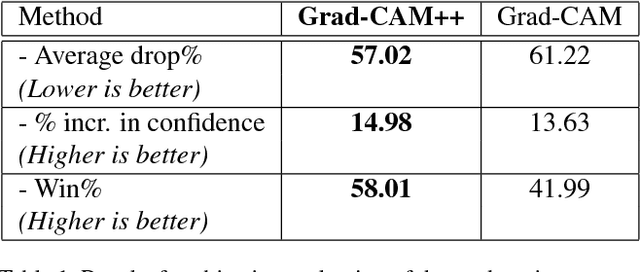
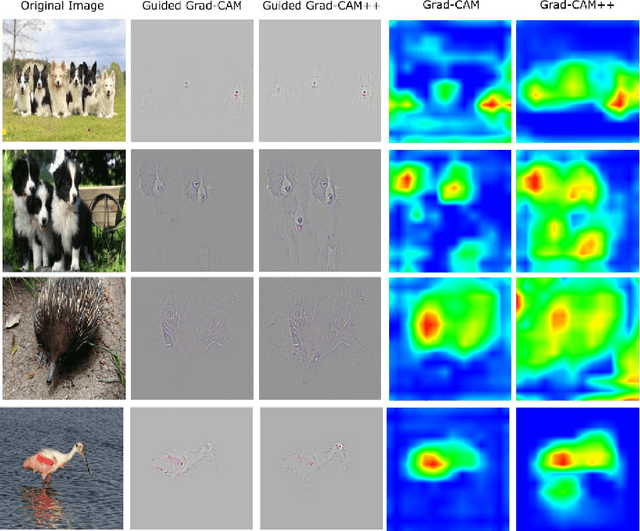
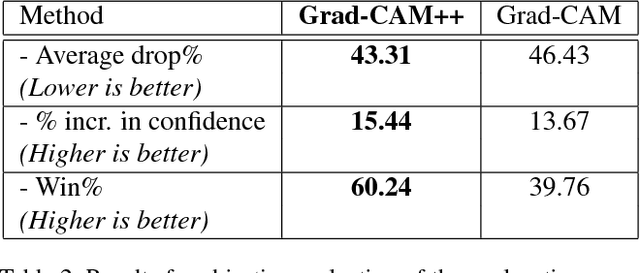
Over the last decade, Convolutional Neural Network (CNN) models have been highly successful in solving complex vision based problems. However, these deep models are perceived as "black box" methods considering the lack of understanding of their internal functioning. There has been a significant recent interest to develop explainable deep learning models, and this paper is an effort in this direction. Building on a recently proposed method called Grad-CAM, we propose a generalized method called Grad-CAM++ that can provide better visual explanations of CNN model predictions, in terms of better object localization as well as explaining occurrences of multiple object instances in a single image, when compared to state-of-the-art. We provide a mathematical derivation for the proposed method, which uses a weighted combination of the positive partial derivatives of the last convolutional layer feature maps with respect to a specific class score as weights to generate a visual explanation for the corresponding class label. Our extensive experiments and evaluations, both subjective and objective, on standard datasets showed that Grad-CAM++ provides promising human-interpretable visual explanations for a given CNN architecture across multiple tasks including classification, image caption generation and 3D action recognition; as well as in new settings such as knowledge distillation.