 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience-Guided Adaptation of Inference-Time Reasoning Strategies
Nov 14, 2025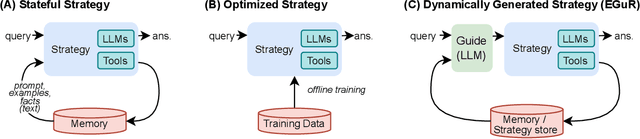
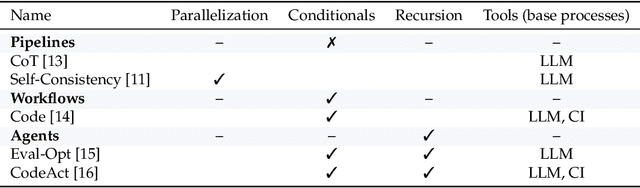

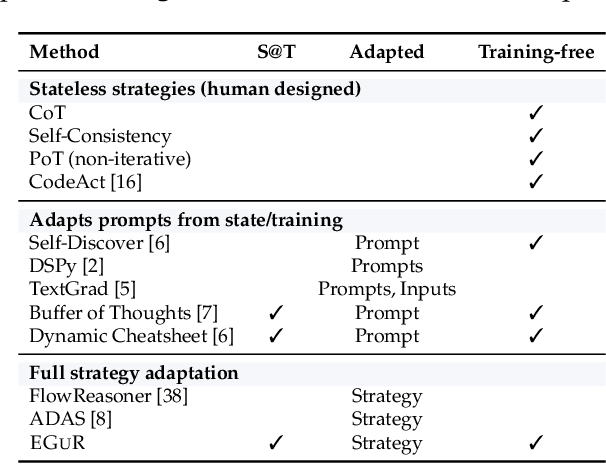
Enabling agentic AI systems to adapt their problem-solving approaches based on post-training interactions remains a fundamental challenge. While systems that update and maintain a memory at inference time have been proposed, existing designs only steer the system by modifying textual input to a language model or agent, which means that they cannot change sampling parameters, remove tools, modify system prompts, or switch between agentic and workflow paradigms. On the other hand, systems that adapt more flexibly require offline optimization and remain static once deployed. We present Experience-Guided Reasoner (EGuR), which generates tailored strategies -- complete computational procedures involving LLM calls, tools, sampling parameters, and control logic -- dynamically at inference time based on accumulated experience. We achieve this using an LLM-based meta-strategy -- a strategy that outputs strategies -- enabling adaptation of all strategy components (prompts, sampling parameters, tool configurations, and control logic). EGuR operates through two components: a Guide generates multiple candidate strategies conditioned on the current problem and structured memory of past experiences, while a Consolidator integrates execution feedback to improve future strategy generation. This produces complete, ready-to-run strategies optimized for each problem, which can be cached, retrieved, and executed as needed without wasting resources. Across five challenging benchmarks (AIME 2025, 3-SAT, and three Big Bench Extra Hard tasks), EGuR achieves up to 14% accuracy improvements over the strongest baselines while reducing computational costs by up to 111x, with both metrics improving as the system gains experience.
PaCE: Parsimonious Concept Engineering for Large Language Models
Jun 06, 2024



Large Language Models (LLMs) are being used for a wide variety of tasks. While they are capable of generating human-like responses, they can also produce undesirable output including potentially harmful information, racist or sexist language, and hallucinations. Alignment methods are designed to reduce such undesirable output, via techniques such as fine-tuning, prompt engineering, and representation engineering. However, existing methods face several challenges: some require costly fine-tuning for every alignment task; some do not adequately remove undesirable concepts, failing alignment; some remove benign concepts, lowering the linguistic capabilities of LLMs. To address these issues, we propose Parsimonious Concept Engineering (PaCE), a novel activation engineering framework for alignment. First, to sufficiently model the concepts, we construct a large-scale concept dictionary in the activation space, in which each atom corresponds to a semantic concept. Then, given any alignment task, we instruct a concept partitioner to efficiently annotate the concepts as benign or undesirable. Finally, at inference time, we decompose the LLM activations along the concept dictionary via sparse coding, to accurately represent the activation as a linear combination of the benign and undesirable components. By removing the latter ones from the activation, we reorient the behavior of LLMs towards alignment goals. We conduct experiments on tasks such as response detoxification, faithfulness enhancement, and sentiment revising, and show that PaCE achieves state-of-the-art alignment performance while maintaining linguistic capabilities.
Learning Interpretable Queries for Explainable Image Classification with Information Pursuit
Dec 16, 2023
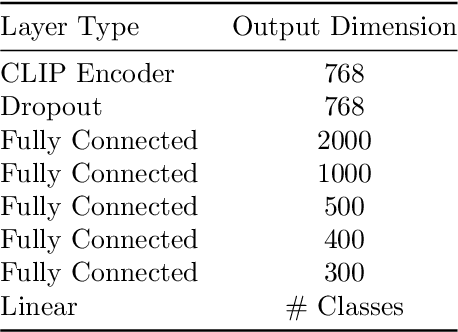
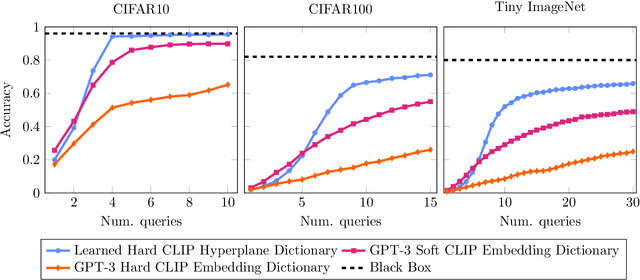
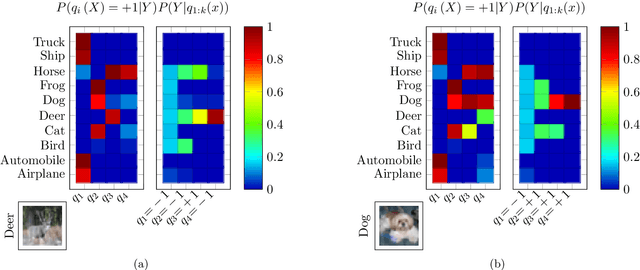
Information Pursuit (IP) is an explainable prediction algorithm that greedily selects a sequence of interpretable queries about the data in order of information gain, updating its posterior at each step based on observed query-answer pairs. The standard paradigm uses hand-crafted dictionaries of potential data queries curated by a domain expert or a large language model after a human prompt. However, in practice, hand-crafted dictionaries are limited by the expertise of the curator and the heuristics of prompt engineering. This paper introduces a novel approach: learning a dictionary of interpretable queries directly from the dataset. Our query dictionary learning problem is formulated as an optimization problem by augmenting IP's variational formulation with learnable dictionary parameters. To formulate learnable and interpretable queries, we leverage the latent space of large vision and language models like CLIP. To solve the optimization problem, we propose a new query dictionary learning algorithm inspired by classical sparse dictionary learning. Our experiments demonstrate that learned dictionaries significantly outperform hand-crafted dictionaries generated with large language models.
Variational Information Pursuit with Large Language and Multimodal Models for Interpretable Predictions
Aug 24, 2023



Variational Information Pursuit (V-IP) is a framework for making interpretable predictions by design by sequentially selecting a short chain of task-relevant, user-defined and interpretable queries about the data that are most informative for the task. While this allows for built-in interpretability in predictive models, applying V-IP to any task requires data samples with dense concept-labeling by domain experts, limiting the application of V-IP to small-scale tasks where manual data annotation is feasible. In this work, we extend the V-IP framework with Foundational Models (FMs) to address this limitation. More specifically, we use a two-step process, by first leveraging Large Language Models (LLMs) to generate a sufficiently large candidate set of task-relevant interpretable concepts, then using Large Multimodal Models to annotate each data sample by semantic similarity with each concept in the generated concept set. While other interpretable-by-design frameworks such as Concept Bottleneck Models (CBMs) require an additional step of removing repetitive and non-discriminative concepts to have good interpretability and test performance, we mathematically and empirically justify that, with a sufficiently informative and task-relevant query (concept) set, the proposed FM+V-IP method does not require any type of concept filtering. In addition, we show that FM+V-IP with LLM generated concepts can achieve better test performance than V-IP with human annotated concepts, demonstrating the effectiveness of LLMs at generating efficient query sets. Finally, when compared to other interpretable-by-design frameworks such as CBMs, FM+V-IP can achieve competitive test performance using fewer number of concepts/queries in both cases with filtered or unfiltered concept sets.
Variational Information Pursuit for Interpretable Predictions
Feb 16, 2023There is a growing interest in the machine learning community in developing predictive algorithms that are "interpretable by design". Towards this end, recent work proposes to make interpretable decisions by sequentially asking interpretable queries about data until a prediction can be made with high confidence based on the answers obtained (the history). To promote short query-answer chains, a greedy procedure called Information Pursuit (IP) is used, which adaptively chooses queries in order of information gain. Generative models are employed to learn the distribution of query-answers and labels, which is in turn used to estimate the most informative query. However, learning and inference with a full generative model of the data is often intractable for complex tasks. In this work, we propose Variational Information Pursuit (V-IP), a variational characterization of IP which bypasses the need for learning generative models. V-IP is based on finding a query selection strategy and a classifier that minimizes the expected cross-entropy between true and predicted labels. We then demonstrate that the IP strategy is the optimal solution to this problem. Therefore, instead of learning generative models, we can use our optimal strategy to directly pick the most informative query given any history. We then develop a practical algorithm by defining a finite-dimensional parameterization of our strategy and classifier using deep networks and train them end-to-end using our objective. Empirically, V-IP is 10-100x faster than IP on different Vision and NLP tasks with competitive performance. Moreover, V-IP finds much shorter query chains when compared to reinforcement learning which is typically used in sequential-decision-making problems. Finally, we demonstrate the utility of V-IP on challenging tasks like medical diagnosis where the performance is far superior to the generative modelling approach.
Interpretable by Design: Learning Predictors by Composing Interpretable Queries
Jul 03, 2022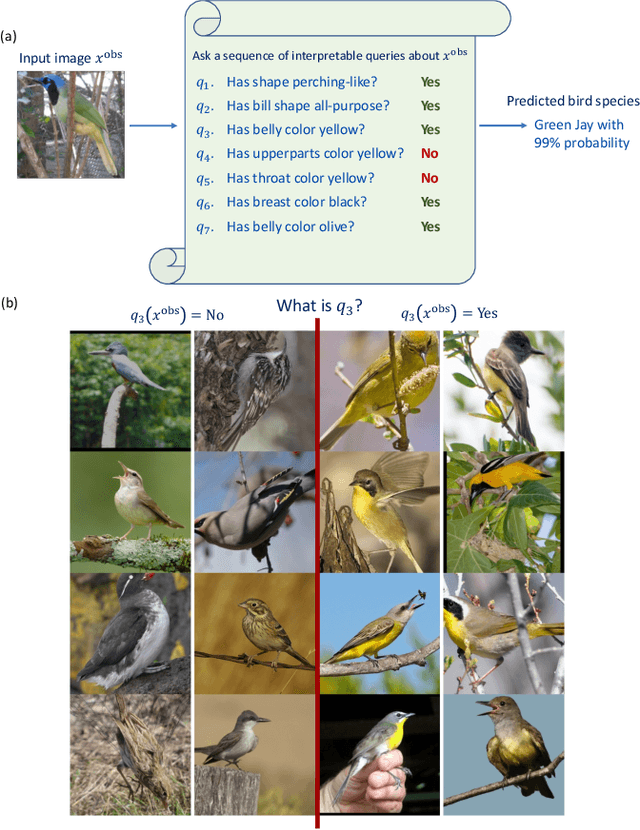



There is a growing concern about typically opaque decision-making with high-performance machine learning algorithms. Providing an explanation of the reasoning process in domain-specific terms can be crucial for adoption in risk-sensitive domains such as healthcare. We argue that machine learning algorithms should be interpretable by design and that the language in which these interpretations are expressed should be domain- and task-dependent. Consequently, we base our model's prediction on a family of user-defined and task-specific binary functions of the data, each having a clear interpretation to the end-user. We then minimize the expected number of queries needed for accurate prediction on any given input. As the solution is generally intractable, following prior work, we choose the queries sequentially based on information gain. However, in contrast to previous work, we need not assume the queries are conditionally independent. Instead, we leverage a stochastic generative model (VAE) and an MCMC algorithm (Unadjusted Langevin) to select the most informative query about the input based on previous query-answers. This enables the online determination of a query chain of whatever depth is required to resolve prediction ambiguities. Finally, experiments on vision and NLP tasks demonstrate the efficacy of our approach and its superiority over post-hoc explanations.
Structured Graph Variational Autoencoders for Indoor Furniture layout Generation
Apr 13, 2022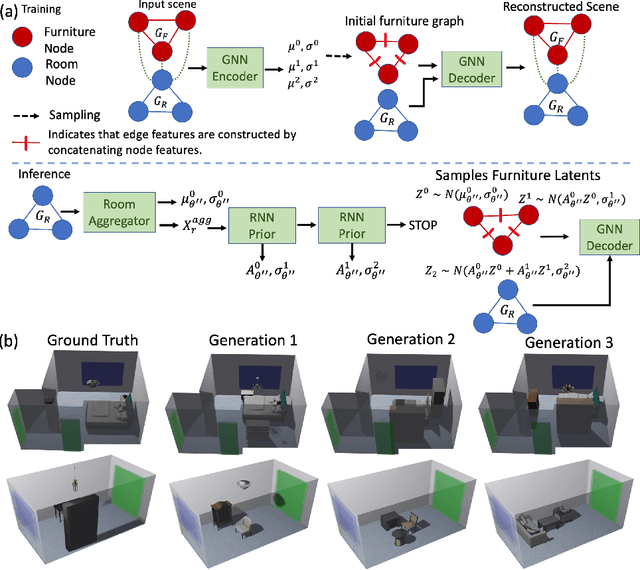
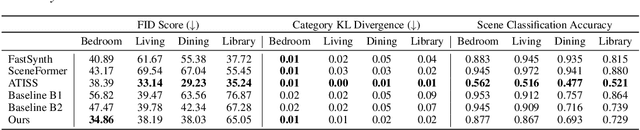
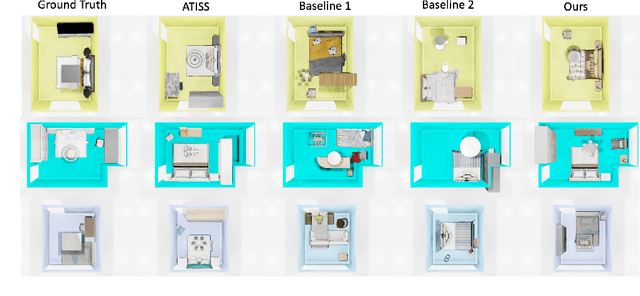
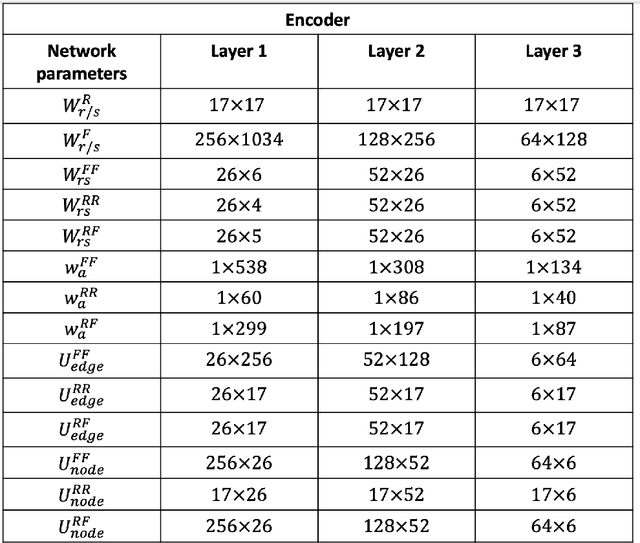
We present a structured graph variational autoencoder for generating the layout of indoor 3D scenes. Given the room type (e.g., living room or library) and the room layout (e.g., room elements such as floor and walls), our architecture generates a collection of objects (e.g., furniture items such as sofa, table and chairs) that is consistent with the room type and layout. This is a challenging problem because the generated scene should satisfy multiple constrains, e.g., each object must lie inside the room and two objects cannot occupy the same volume. To address these challenges, we propose a deep generative model that encodes these relationships as soft constraints on an attributed graph (e.g., the nodes capture attributes of room and furniture elements, such as class, pose and size, and the edges capture geometric relationships such as relative orientation). The architecture consists of a graph encoder that maps the input graph to a structured latent space, and a graph decoder that generates a furniture graph, given a latent code and the room graph. The latent space is modeled with auto-regressive priors, which facilitates the generation of highly structured scenes. We also propose an efficient training procedure that combines matching and constrained learning. Experiments on the 3D-FRONT dataset show that our method produces scenes that are diverse and are adapted to the room layout.
Neural Network Attributions: A Causal Perspective
Feb 07, 2019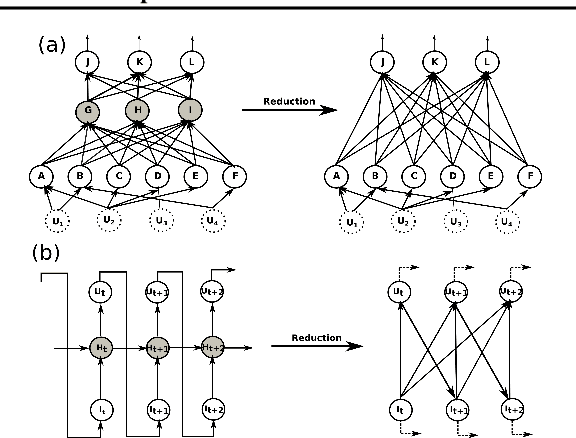
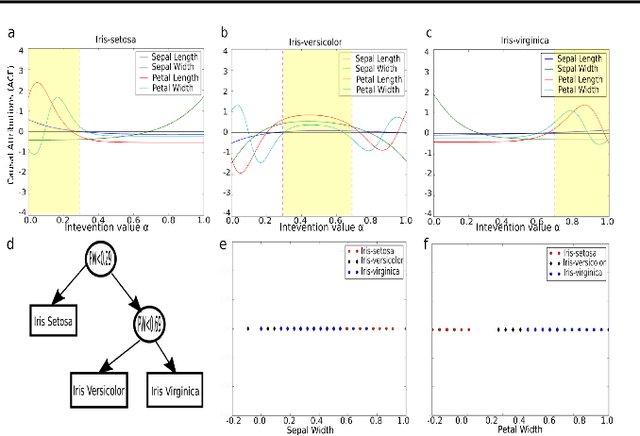
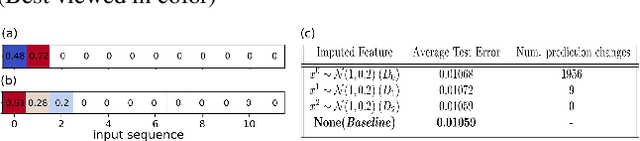
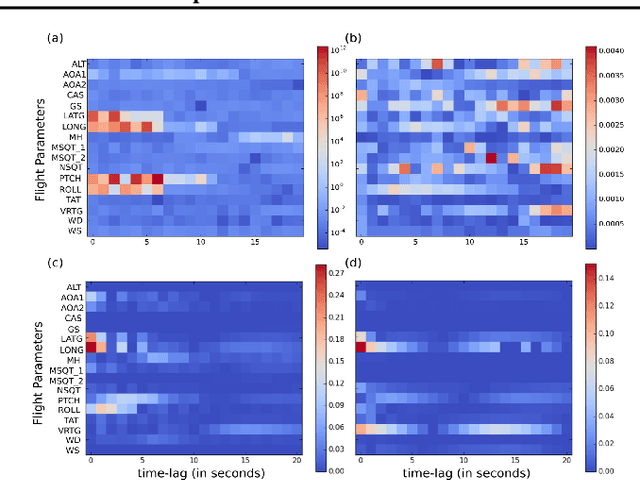
We propose a new attribution method for neural networks developed using first principles of causality (to the best of our knowledge, the first such). The neural network architecture is viewed as a Structural Causal Model, and a methodology to compute the causal effect of each feature on the output is presented. With reasonable assumptions on the causal structure of the input data, we propose algorithms to efficiently compute the causal effects, as well as scale the approach to data with large dimensionality. We also show how this method can be used for recurrent neural networks. We report experimental results on both simulated and real datasets showcasing the promise and usefulness of the proposed algorithm.
Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks
May 08, 2018
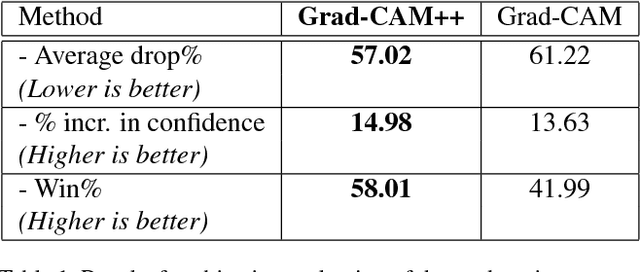
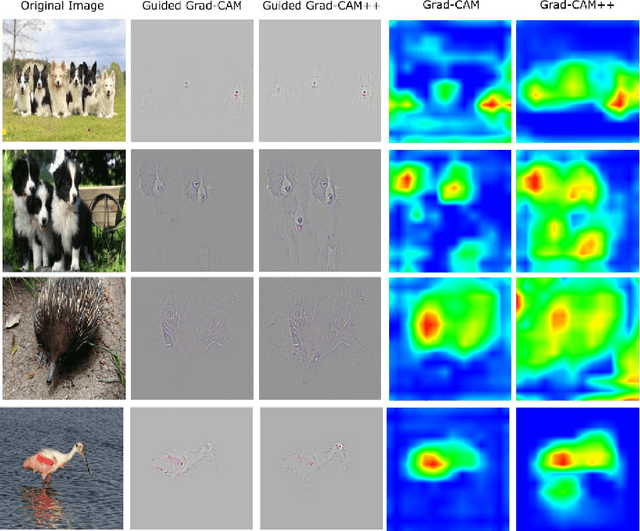
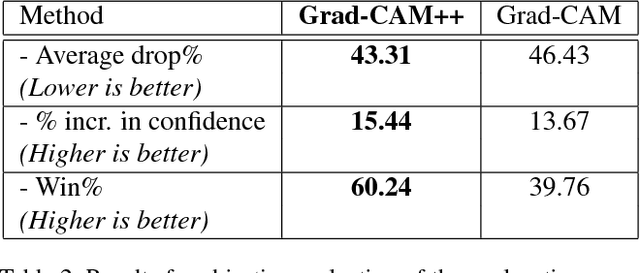
Over the last decade, Convolutional Neural Network (CNN) models have been highly successful in solving complex vision based problems. However, these deep models are perceived as "black box" methods considering the lack of understanding of their internal functioning. There has been a significant recent interest to develop explainable deep learning models, and this paper is an effort in this direction. Building on a recently proposed method called Grad-CAM, we propose a generalized method called Grad-CAM++ that can provide better visual explanations of CNN model predictions, in terms of better object localization as well as explaining occurrences of multiple object instances in a single image, when compared to state-of-the-art. We provide a mathematical derivation for the proposed method, which uses a weighted combination of the positive partial derivatives of the last convolutional layer feature maps with respect to a specific class score as weights to generate a visual explanation for the corresponding class label. Our extensive experiments and evaluations, both subjective and objective, on standard datasets showed that Grad-CAM++ provides promising human-interpretable visual explanations for a given CNN architecture across multiple tasks including classification, image caption generation and 3D action recognition; as well as in new settings such as knowledge distillation.