 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrICy: Trigger-guided Data-to-text Generation with Intent aware Attention-Copy
Jan 25, 2024



Data-to-text (D2T) generation is a crucial task in many natural language understanding (NLU) applications and forms the foundation of task-oriented dialog systems. In the context of conversational AI solutions that can work directly with local data on the user's device, architectures utilizing large pre-trained language models (PLMs) are impractical for on-device deployment due to a high memory footprint. To this end, we propose TrICy, a novel lightweight framework for an enhanced D2T task that generates text sequences based on the intent in context and may further be guided by user-provided triggers. We leverage an attention-copy mechanism to predict out-of-vocabulary (OOV) words accurately. Performance analyses on E2E NLG dataset (BLEU: 66.43%, ROUGE-L: 70.14%), WebNLG dataset (BLEU: Seen 64.08%, Unseen 52.35%), and our Custom dataset related to text messaging applications, showcase our architecture's effectiveness. Moreover, we show that by leveraging an optional trigger input, data-to-text generation quality increases significantly and achieves the new SOTA score of 69.29% BLEU for E2E NLG. Furthermore, our analyses show that TrICy achieves at least 24% and 3% improvement in BLEU and METEOR respectively over LLMs like GPT-3, ChatGPT, and Llama 2. We also demonstrate that in some scenarios, performance improvement due to triggers is observed even when they are absent in training.
Automated Material Properties Extraction For Enhanced Beauty Product Discovery and Makeup Virtual Try-on
Dec 01, 2023The multitude of makeup products available can make it challenging to find the ideal match for desired attributes. An intelligent approach for product discovery is required to enhance the makeup shopping experience to make it more convenient and satisfying. However, enabling accurate and efficient product discovery requires extracting detailed attributes like color and finish type. Our work introduces an automated pipeline that utilizes multiple customized machine learning models to extract essential material attributes from makeup product images. Our pipeline is versatile and capable of handling various makeup products. To showcase the efficacy of our pipeline, we conduct extensive experiments on eyeshadow products (both single and multi-shade ones), a challenging makeup product known for its diverse range of shapes, colors, and finish types. Furthermore, we demonstrate the applicability of our approach by successfully extending it to other makeup categories like lipstick and foundation, showcasing its adaptability and effectiveness across different beauty products. Additionally, we conduct ablation experiments to demonstrate the superiority of our machine learning pipeline over human labeling methods in terms of reliability. Our proposed method showcases its effectiveness in cross-category product discovery, specifically in recommending makeup products that perfectly match a specified outfit. Lastly, we also demonstrate the application of these material attributes in enabling virtual-try-on experiences which makes makeup shopping experience significantly more engaging.
Unsupervised Scene Sketch to Photo Synthesis
Sep 06, 2022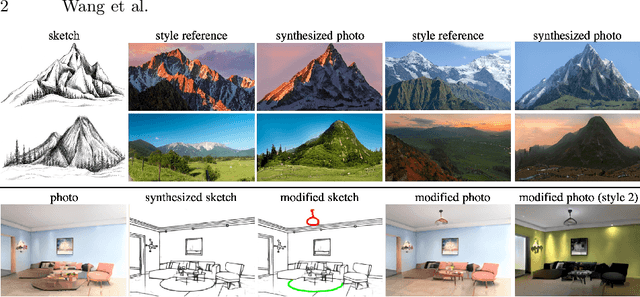
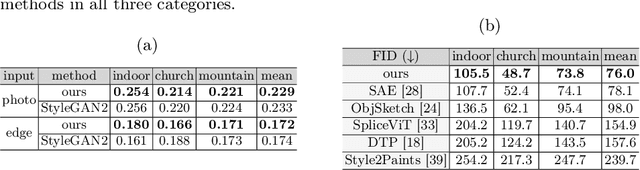
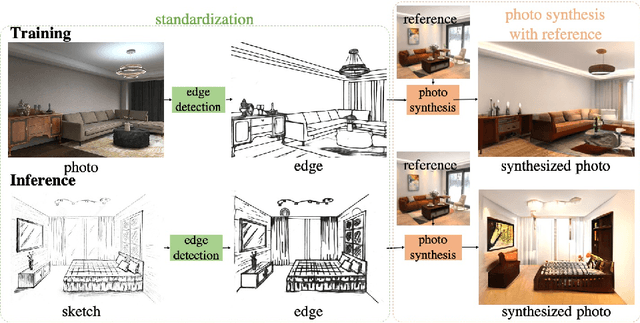

Sketches make an intuitive and powerful visual expression as they are fast executed freehand drawings. We present a method for synthesizing realistic photos from scene sketches. Without the need for sketch and photo pairs, our framework directly learns from readily available large-scale photo datasets in an unsupervised manner. To this end, we introduce a standardization module that provides pseudo sketch-photo pairs during training by converting photos and sketches to a standardized domain, i.e. the edge map. The reduced domain gap between sketch and photo also allows us to disentangle them into two components: holistic scene structures and low-level visual styles such as color and texture. Taking this advantage, we synthesize a photo-realistic image by combining the structure of a sketch and the visual style of a reference photo. Extensive experimental results on perceptual similarity metrics and human perceptual studies show the proposed method could generate realistic photos with high fidelity from scene sketches and outperform state-of-the-art photo synthesis baselines. We also demonstrate that our framework facilitates a controllable manipulation of photo synthesis by editing strokes of corresponding sketches, delivering more fine-grained details than previous approaches that rely on region-level editing.
Structured Graph Variational Autoencoders for Indoor Furniture layout Generation
Apr 13, 2022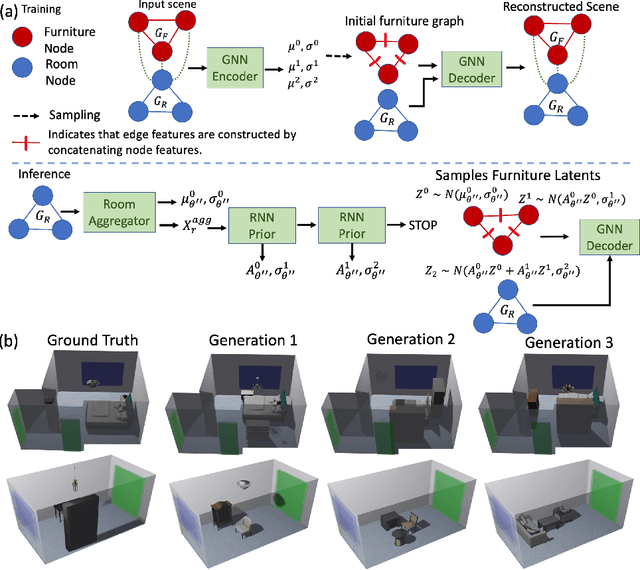
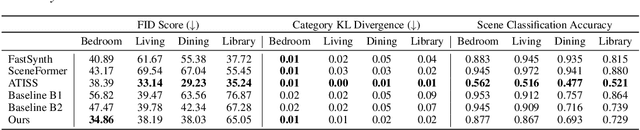
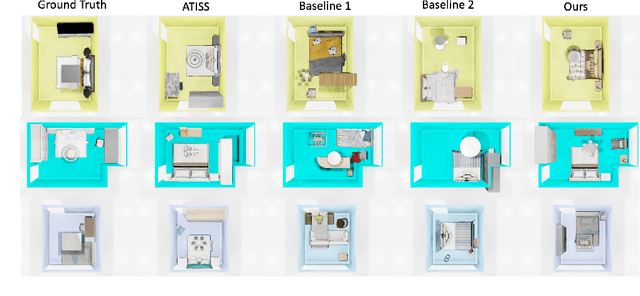
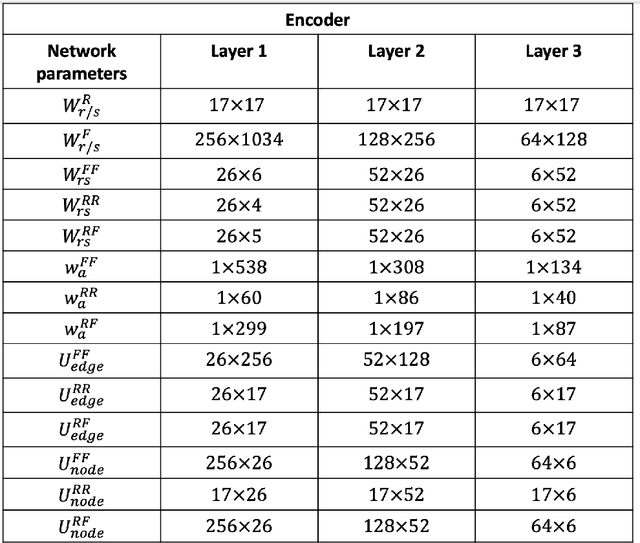
We present a structured graph variational autoencoder for generating the layout of indoor 3D scenes. Given the room type (e.g., living room or library) and the room layout (e.g., room elements such as floor and walls), our architecture generates a collection of objects (e.g., furniture items such as sofa, table and chairs) that is consistent with the room type and layout. This is a challenging problem because the generated scene should satisfy multiple constrains, e.g., each object must lie inside the room and two objects cannot occupy the same volume. To address these challenges, we propose a deep generative model that encodes these relationships as soft constraints on an attributed graph (e.g., the nodes capture attributes of room and furniture elements, such as class, pose and size, and the edges capture geometric relationships such as relative orientation). The architecture consists of a graph encoder that maps the input graph to a structured latent space, and a graph decoder that generates a furniture graph, given a latent code and the room graph. The latent space is modeled with auto-regressive priors, which facilitates the generation of highly structured scenes. We also propose an efficient training procedure that combines matching and constrained learning. Experiments on the 3D-FRONT dataset show that our method produces scenes that are diverse and are adapted to the room layout.
VoiceMoji: A Novel On-Device Pipeline for Seamless Emoji Insertion in Dictation
Dec 22, 2021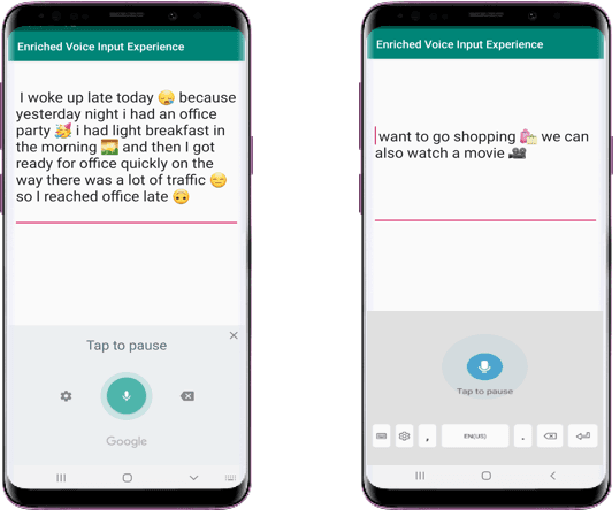
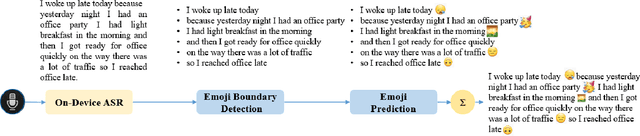

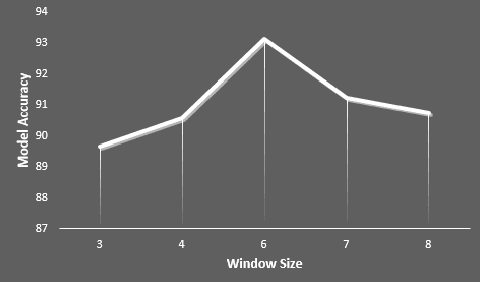
Most of the speech recognition systems recover only words in the speech and fail to capture emotions. Users have to manually add emoji(s) in text for adding tone and making communication fun. Though there is much work done on punctuation addition on transcribed speech, the area of emotion addition is untouched. In this paper, we propose a novel on-device pipeline to enrich the voice input experience. It involves, given a blob of transcribed text, intelligently processing and identifying structure where emoji insertion makes sense. Moreover, it includes semantic text analysis to predict emoji for each of the sub-parts for which we propose a novel architecture Attention-based Char Aware (ACA) LSTM which handles Out-Of-Vocabulary (OOV) words as well. All these tasks are executed completely on-device and hence can aid on-device dictation systems. To the best of our knowledge, this is the first work that shows how to add emoji(s) in the transcribed text. We demonstrate that our components achieve comparable results to previous neural approaches for punctuation addition and emoji prediction with 80% fewer parameters. Overall, our proposed model has a very small memory footprint of a mere 4MB to suit on-device deployment.
ABO: Dataset and Benchmarks for Real-World 3D Object Understanding
Oct 12, 2021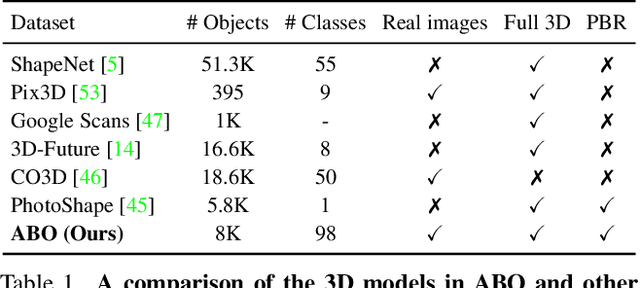
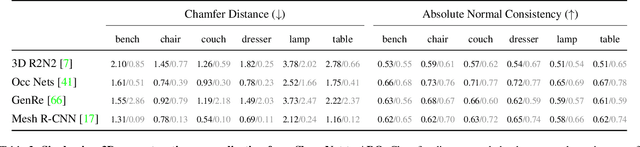
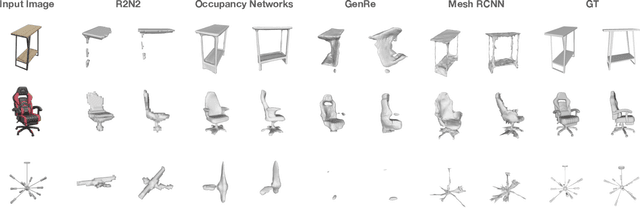
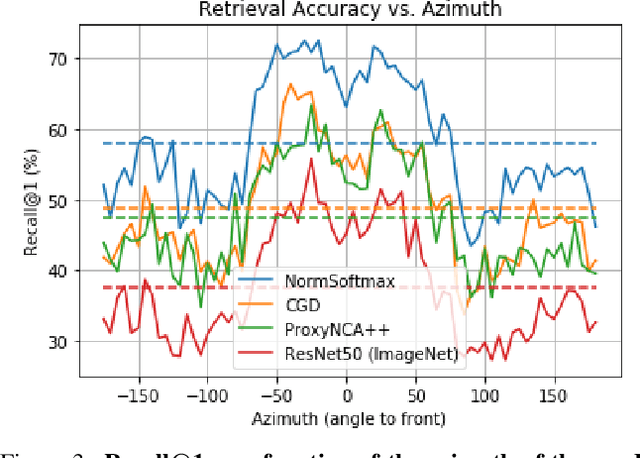
We introduce Amazon-Berkeley Objects (ABO), a new large-scale dataset of product images and 3D models corresponding to real household objects. We use this realistic, object-centric 3D dataset to measure the domain gap for single-view 3D reconstruction networks trained on synthetic objects. We also use multi-view images from ABO to measure the robustness of state-of-the-art metric learning approaches to different camera viewpoints. Finally, leveraging the physically-based rendering materials in ABO, we perform single- and multi-view material estimation for a variety of complex, real-world geometries. The full dataset is available for download at https://amazon-berkeley-objects.s3.amazonaws.com/index.html.
RoomStructNet: Learning to Rank Non-Cuboidal Room Layouts From Single View
Oct 01, 2021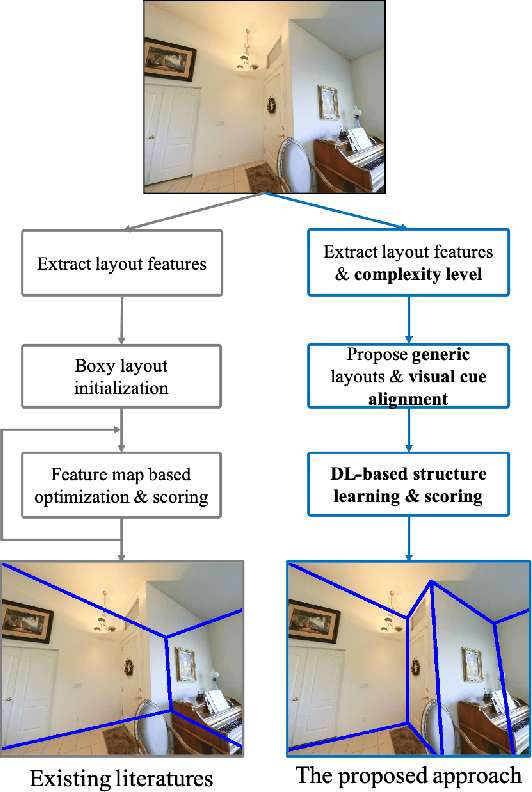
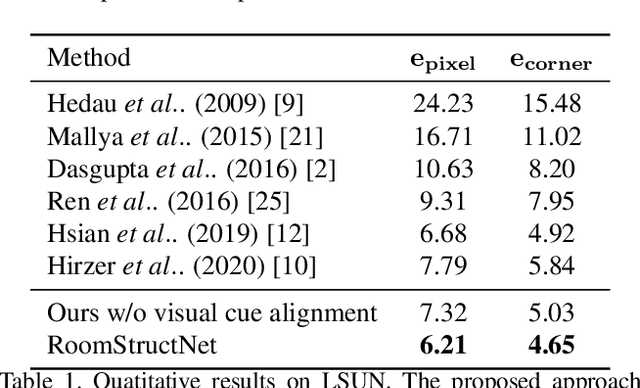
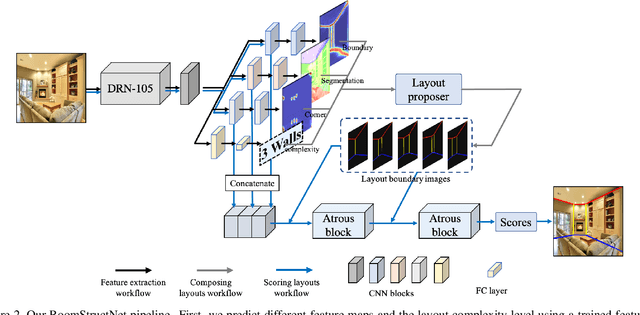
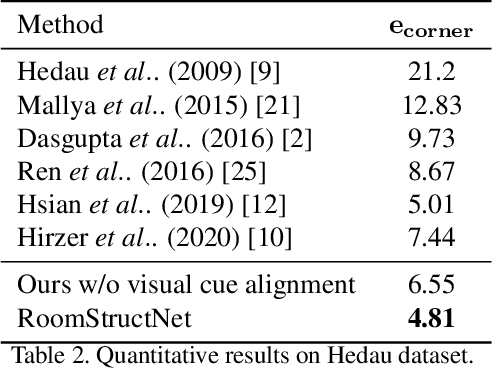
In this paper, we present a new approach to estimate the layout of a room from its single image. While recent approaches for this task use robust features learnt from data, they resort to optimization for detecting the final layout. In addition to using learnt robust features, our approach learns an additional ranking function to estimate the final layout instead of using optimization. To learn this ranking function, we propose a framework to train a CNN using max-margin structure cost. Also, while most approaches aim at detecting cuboidal layouts, our approach detects non-cuboidal layouts for which we explicitly estimates layout complexity parameters. We use these parameters to propose layout candidates in a novel way. Our approach shows state-of-the-art results on standard datasets with mostly cuboidal layouts and also performs well on a dataset containing rooms with non-cuboidal layouts.
Multimodal Shape Completion via IMLE
Jul 07, 2021

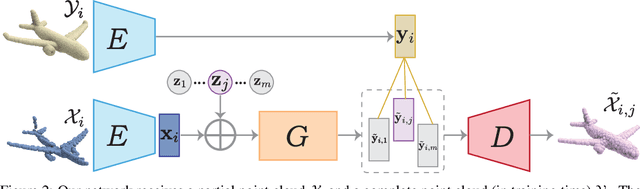

Shape completion is the problem of completing partial input shapes such as partial scans. This problem finds important applications in computer vision and robotics due to issues such as occlusion or sparsity in real-world data. However, most of the existing research related to shape completion has been focused on completing shapes by learning a one-to-one mapping which limits the diversity and creativity of the produced results. We propose a novel multimodal shape completion technique that is effectively able to learn a one-to-many mapping and generates diverse complete shapes. Our approach is based on the conditional Implicit MaximumLikelihood Estimation (IMLE) technique wherein we condition our inputs on partial 3D point clouds. We extensively evaluate our approach by comparing it to various baselines both quantitatively and qualitatively. We show that our method is superior to alternatives in terms of completeness and diversity of shapes.
A character representation enhanced on-device Intent Classification
Jan 12, 2021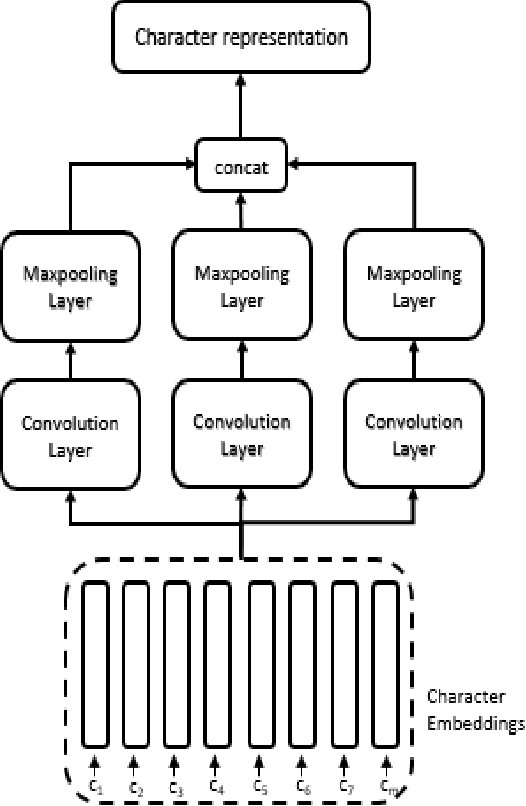
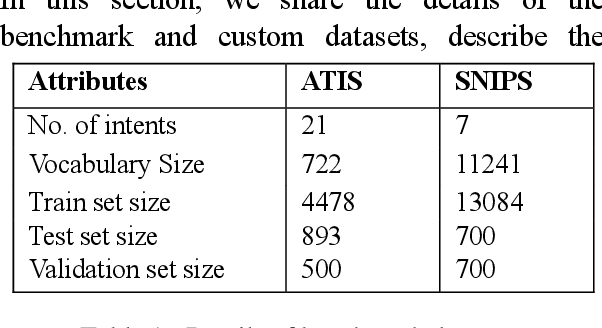
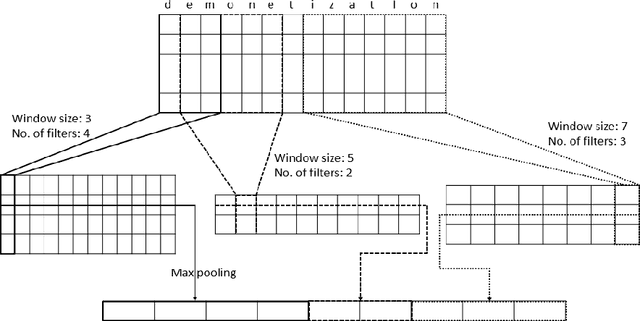

Intent classification is an important task in natural language understanding systems. Existing approaches have achieved perfect scores on the benchmark datasets. However they are not suitable for deployment on low-resource devices like mobiles, tablets, etc. due to their massive model size. Therefore, in this paper, we present a novel light-weight architecture for intent classification that can run efficiently on a device. We use character features to enrich the word representation. Our experiments prove that our proposed model outperforms existing approaches and achieves state-of-the-art results on benchmark datasets. We also report that our model has tiny memory footprint of ~5 MB and low inference time of ~2 milliseconds, which proves its efficiency in a resource-constrained environment.
Contextual Diversity for Active Learning
Aug 13, 2020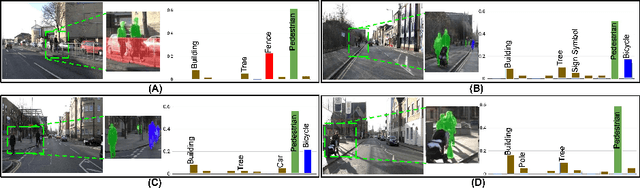
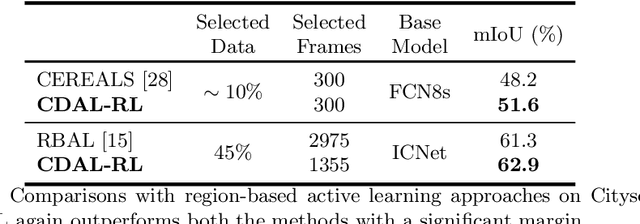
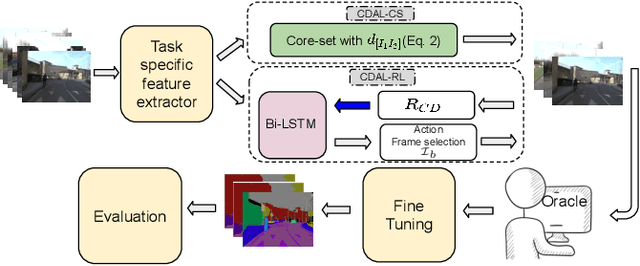

Requirement of large annotated datasets restrict the use of deep convolutional neural networks (CNNs) for many practical applications. The problem can be mitigated by using active learning (AL) techniques which, under a given annotation budget, allow to select a subset of data that yields maximum accuracy upon fine tuning. State of the art AL approaches typically rely on measures of visual diversity or prediction uncertainty, which are unable to effectively capture the variations in spatial context. On the other hand, modern CNN architectures make heavy use of spatial context for achieving highly accurate predictions. Since the context is difficult to evaluate in the absence of ground-truth labels, we introduce the notion of contextual diversity that captures the confusion associated with spatially co-occurring classes. Contextual Diversity (CD) hinges on a crucial observation that the probability vector predicted by a CNN for a region of interest typically contains information from a larger receptive field. Exploiting this observation, we use the proposed CD measure within two AL frameworks: (1) a core-set based strategy and (2) a reinforcement learning based policy, for active frame selection. Our extensive empirical evaluation establish state of the art results for active learning on benchmark datasets of Semantic Segmentation, Object Detection and Image Classification. Our ablation studies show clear advantages of using contextual diversity for active learning. The source code and additional results are available at https://github.com/sharat29ag/CDAL.