 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPS: A Compact On-device Pipeline for real-time Smishing detection
Feb 06, 2024Smartphones have become indispensable in our daily lives and can do almost everything, from communication to online shopping. However, with the increased usage, cybercrime aimed at mobile devices is rocketing. Smishing attacks, in particular, have observed a significant upsurge in recent years. This problem is further exacerbated by the perpetrator creating new deceptive websites daily, with an average life cycle of under 15 hours. This renders the standard practice of keeping a database of malicious URLs ineffective. To this end, we propose a novel on-device pipeline: COPS that intelligently identifies features of fraudulent messages and URLs to alert the user in real-time. COPS is a lightweight pipeline with a detection module based on the Disentangled Variational Autoencoder of size 3.46MB for smishing and URL phishing detection, and we benchmark it on open datasets. We achieve an accuracy of 98.15% and 99.5%, respectively, for both tasks, with a false negative and false positive rate of a mere 0.037 and 0.015, outperforming previous works with the added advantage of ensuring real-time alerts on resource-constrained devices.
PrivPAS: A real time Privacy-Preserving AI System and applied ethics
Feb 08, 2022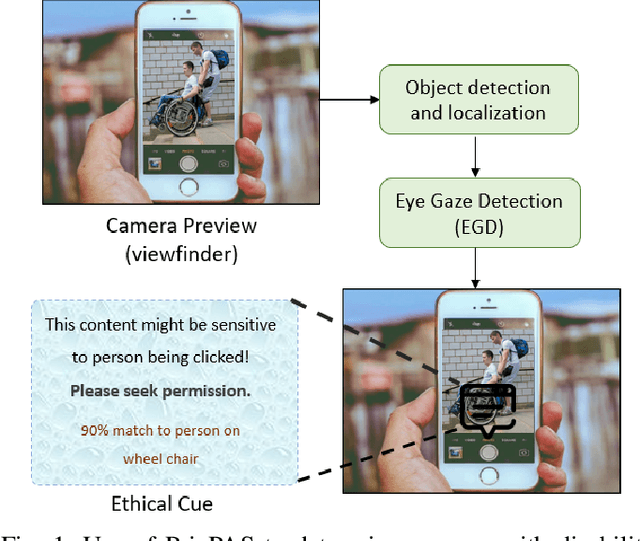

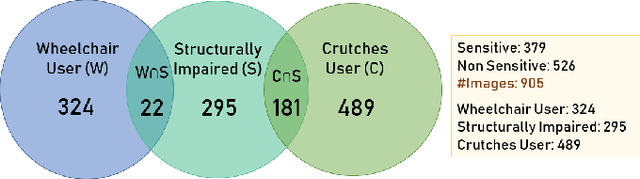

With 3.78 billion social media users worldwide in 2021 (48% of the human population), almost 3 billion images are shared daily. At the same time, a consistent evolution of smartphone cameras has led to a photography explosion with 85% of all new pictures being captured using smartphones. However, lately, there has been an increased discussion of privacy concerns when a person being photographed is unaware of the picture being taken or has reservations about the same being shared. These privacy violations are amplified for people with disabilities, who may find it challenging to raise dissent even if they are aware. Such unauthorized image captures may also be misused to gain sympathy by third-party organizations, leading to a privacy breach. Privacy for people with disabilities has so far received comparatively less attention from the AI community. This motivates us to work towards a solution to generate privacy-conscious cues for raising awareness in smartphone users of any sensitivity in their viewfinder content. To this end, we introduce PrivPAS (A real time Privacy-Preserving AI System) a novel framework to identify sensitive content. Additionally, we curate and annotate a dataset to identify and localize accessibility markers and classify whether an image is sensitive to a featured subject with a disability. We demonstrate that the proposed lightweight architecture, with a memory footprint of a mere 8.49MB, achieves a high mAP of 89.52% on resource-constrained devices. Furthermore, our pipeline, trained on face anonymized data, achieves an F1-score of 73.1%.
LEAPMood: Light and Efficient Architecture to Predict Mood with Genetic Algorithm driven Hyperparameter Tuning
Feb 08, 2022
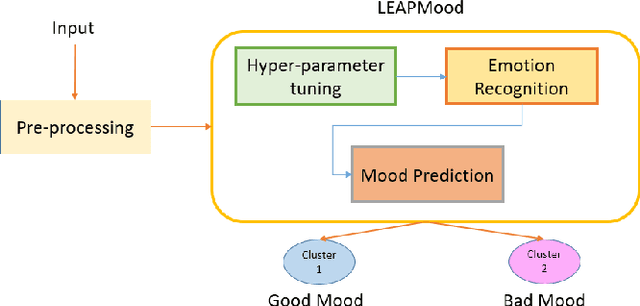
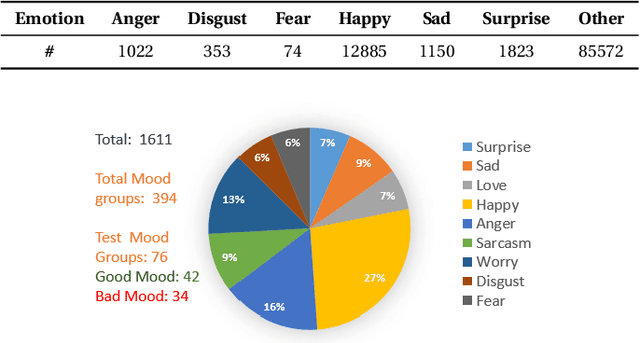
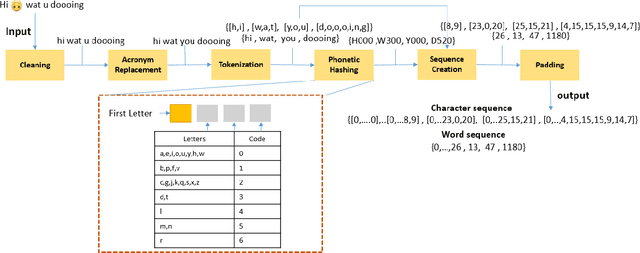
Accurate and automatic detection of mood serves as a building block for use cases like user profiling which in turn power applications such as advertising, recommendation systems, and many more. One primary source indicative of an individual's mood is textual data. While there has been extensive research on emotion recognition, the field of mood prediction has been barely explored. In addition, very little work is done in the area of on-device inferencing, which is highly important from the user privacy point of view. In this paper, we propose for the first time, an on-device deep learning approach for mood prediction from textual data, LEAPMood. We use a novel on-device deployment-focused objective function for hyperparameter tuning based on the Genetic Algorithm (GA) and optimize the parameters concerning both performance and size. LEAPMood consists of Emotion Recognition in Conversion (ERC) as the first building block followed by mood prediction using K-means clustering. We show that using a combination of character embedding, phonetic hashing, and attention along with Conditional Random Fields (CRF), results in a performance closely comparable to that of the current State-Of-the-Art with a significant reduction in model size (> 90%) for the task of ERC. We achieve a Micro F1 score of 62.05% with a memory footprint of a mere 1.67MB on the DailyDialog dataset. Furthermore, we curate a dataset for the task of mood prediction achieving a Macro F1-score of 72.12% with LEAPMood.
VoiceMoji: A Novel On-Device Pipeline for Seamless Emoji Insertion in Dictation
Dec 22, 2021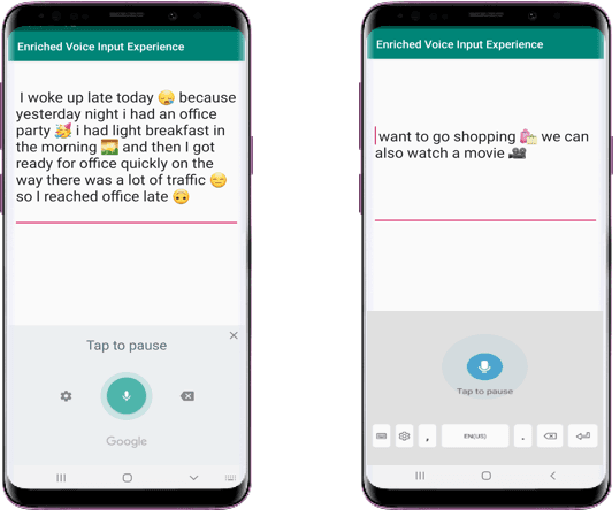
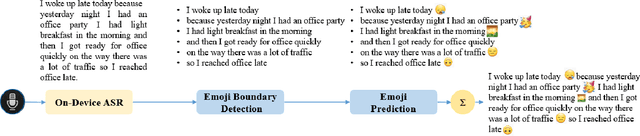

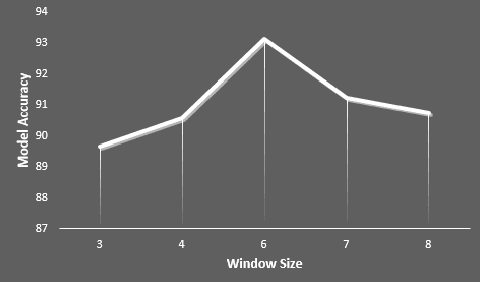
Most of the speech recognition systems recover only words in the speech and fail to capture emotions. Users have to manually add emoji(s) in text for adding tone and making communication fun. Though there is much work done on punctuation addition on transcribed speech, the area of emotion addition is untouched. In this paper, we propose a novel on-device pipeline to enrich the voice input experience. It involves, given a blob of transcribed text, intelligently processing and identifying structure where emoji insertion makes sense. Moreover, it includes semantic text analysis to predict emoji for each of the sub-parts for which we propose a novel architecture Attention-based Char Aware (ACA) LSTM which handles Out-Of-Vocabulary (OOV) words as well. All these tasks are executed completely on-device and hence can aid on-device dictation systems. To the best of our knowledge, this is the first work that shows how to add emoji(s) in the transcribed text. We demonstrate that our components achieve comparable results to previous neural approaches for punctuation addition and emoji prediction with 80% fewer parameters. Overall, our proposed model has a very small memory footprint of a mere 4MB to suit on-device deployment.
Adaptive Beam Search to Enhance On-device Abstractive Summarization
Dec 22, 2021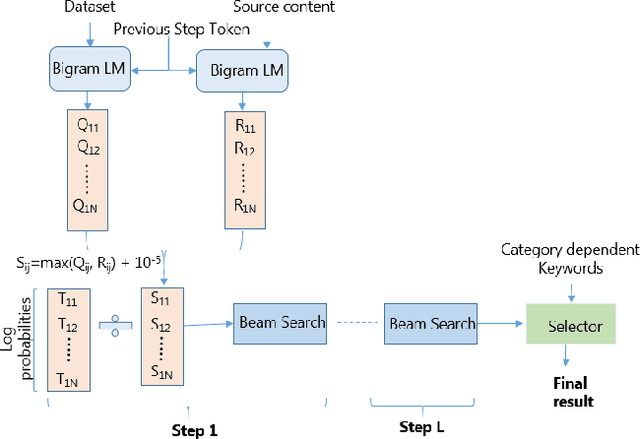
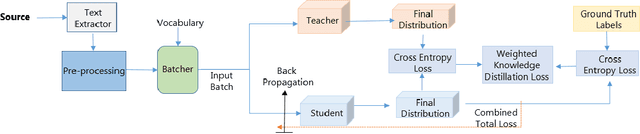
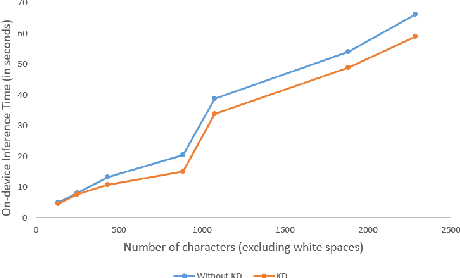
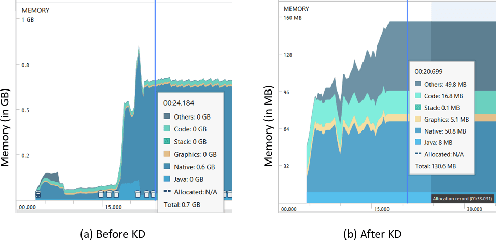
We receive several essential updates on our smartphones in the form of SMS, documents, voice messages, etc. that get buried beneath the clutter of content. We often do not realize the key information without going through the full content. SMS notifications sometimes help by giving an idea of what the message is about, however, they merely offer a preview of the beginning content. One way to solve this is to have a single efficient model that can adapt and summarize data from varied sources. In this paper, we tackle this issue and for the first time, propose a novel Adaptive Beam Search to improve the quality of on-device abstractive summarization that can be applied to SMS, voice messages and can be extended to documents. To the best of our knowledge, this is the first on-device abstractive summarization pipeline to be proposed that can adapt to multiple data sources addressing privacy concerns of users as compared to the majority of existing summarization systems that send data to a server. We reduce the model size by 30.9% using knowledge distillation and show that this model with a 97.6% lesser memory footprint extracts the same or more key information as compared to BERT.
A character representation enhanced on-device Intent Classification
Jan 12, 2021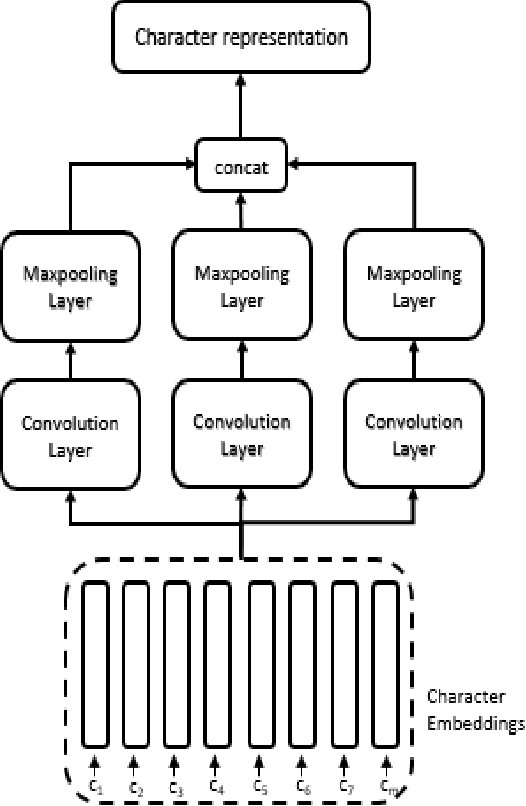
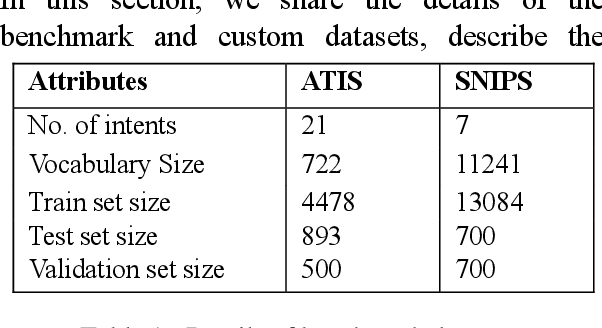
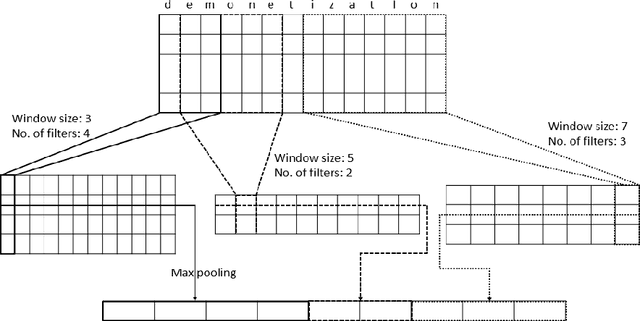

Intent classification is an important task in natural language understanding systems. Existing approaches have achieved perfect scores on the benchmark datasets. However they are not suitable for deployment on low-resource devices like mobiles, tablets, etc. due to their massive model size. Therefore, in this paper, we present a novel light-weight architecture for intent classification that can run efficiently on a device. We use character features to enrich the word representation. Our experiments prove that our proposed model outperforms existing approaches and achieves state-of-the-art results on benchmark datasets. We also report that our model has tiny memory footprint of ~5 MB and low inference time of ~2 milliseconds, which proves its efficiency in a resource-constrained environment.