 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCity-Mesh3R: Simulation-Ready City-Scale 3D Mesh Reconstruction from Multi-View Images
May 28, 2026City-scale 3D surface reconstruction from multiview images for downstream 3D simulation, poses highly challenging problems due to the scale and complexity of urban scenes. Existing city-scale 3D reconstruction methods based on NeRF, Gaussian Splatting etc. often fail to recover 3D meshes ready for simulation due to incomplete/missing geometry and irregular, noisy surfaces. Scaling existing small-scale 3D reconstruction methods to arbitrarily large urban scenes is highly infeasible due to their computational complexity. We present City-Mesh3R, a scalable framework for reconstructing watertight surface meshes directly from large unordered image collections. Unlike recent methods which use global sparse SfM point-cloud initialization followed by a distributed 3D dense reconstruction of large-scale scenes, our method follows an end-to-end images-to-mesh 3D reconstruction approach using a divide-and-conquer strategy. The sparse city map is reconstructed via topological image clustering, cluster-wise independent sparse SfM and map merging, without need for exhaustive image feature matching. Then this map is partitioned spatially to perform geometry-aware camera selection, followed by dense surface reconstruction and surface refinement using curvature-aware adaptive vertex density remeshing. These partition meshes are then stitched together to produce the global mesh of the city. The proposed end-to-end framework is evaluated on city-scale reconstruction datasets. As demonstrated by our qualitative and quantitative results, our proposed method yields high-fidelity watertight 3D meshes with regular geometry, capturing fine surface details, and is suitable for scaling to arbitrarily large scenes owing to the end-to-end processing in a distributed setting.
Task Planning for Object Rearrangement in Multi-room Environments
Jun 01, 2024



Object rearrangement in a multi-room setup should produce a reasonable plan that reduces the agent's overall travel and the number of steps. Recent state-of-the-art methods fail to produce such plans because they rely on explicit exploration for discovering unseen objects due to partial observability and a heuristic planner to sequence the actions for rearrangement. This paper proposes a novel hierarchical task planner to efficiently plan a sequence of actions to discover unseen objects and rearrange misplaced objects within an untidy house to achieve a desired tidy state. The proposed method introduces several novel techniques, including (i) a method for discovering unseen objects using commonsense knowledge from large language models, (ii) a collision resolution and buffer prediction method based on Cross-Entropy Method to handle blocked goal and swap cases, (iii) a directed spatial graph-based state space for scalability, and (iv) deep reinforcement learning (RL) for producing an efficient planner. The planner interleaves the discovery of unseen objects and rearrangement to minimize the number of steps taken and overall traversal of the agent. The paper also presents new metrics and a benchmark dataset called MoPOR to evaluate the effectiveness of the rearrangement planning in a multi-room setting. The experimental results demonstrate that the proposed method effectively addresses the multi-room rearrangement problem.
TrICy: Trigger-guided Data-to-text Generation with Intent aware Attention-Copy
Jan 25, 2024



Data-to-text (D2T) generation is a crucial task in many natural language understanding (NLU) applications and forms the foundation of task-oriented dialog systems. In the context of conversational AI solutions that can work directly with local data on the user's device, architectures utilizing large pre-trained language models (PLMs) are impractical for on-device deployment due to a high memory footprint. To this end, we propose TrICy, a novel lightweight framework for an enhanced D2T task that generates text sequences based on the intent in context and may further be guided by user-provided triggers. We leverage an attention-copy mechanism to predict out-of-vocabulary (OOV) words accurately. Performance analyses on E2E NLG dataset (BLEU: 66.43%, ROUGE-L: 70.14%), WebNLG dataset (BLEU: Seen 64.08%, Unseen 52.35%), and our Custom dataset related to text messaging applications, showcase our architecture's effectiveness. Moreover, we show that by leveraging an optional trigger input, data-to-text generation quality increases significantly and achieves the new SOTA score of 69.29% BLEU for E2E NLG. Furthermore, our analyses show that TrICy achieves at least 24% and 3% improvement in BLEU and METEOR respectively over LLMs like GPT-3, ChatGPT, and Llama 2. We also demonstrate that in some scenarios, performance improvement due to triggers is observed even when they are absent in training.
An Edge Assisted Robust Smart Traffic Management and Signalling System for Guiding Emergency Vehicles During Peak Hours
May 02, 2023Congestion in traffic is an unavoidable circumstance in many cities in India and other countries. It is an issue of major concern. The steep rise in the number of automobiles on the roads followed by old infrastructure, accidents, pedestrian traffic, and traffic rule violations all add to challenging traffic conditions. Given these poor conditions of traffic, there is a critical need for automatically detecting and signaling systems. There are already various technologies that are used for traffic management and signaling systems like video analysis, infrared sensors, and wireless sensors. The main issue with these methods is they are very costly and high maintenance is required. In this paper, we have proposed a three-phase system that can guide emergency vehicles and manage traffic based on the degree of congestion. In the first phase, the system processes the captured images and calculates the Index value which is used to discover the degree of congestion. The Index value of a particular road depends on its width and the length up to which the camera captures images of that road. We have to take input for the parameters (length and width) while setting up the system. In the second phase, the system checks whether there are any emergency vehicles present or not in any lane. In the third phase, the whole processing and decision-making part is performed at the edge server. The proposed model is robust and it takes into consideration adverse weather conditions such as hazy, foggy, and windy. It works very efficiently in low light conditions also. The edge server is a strategically placed server that provides us with low latency and better connectivity. Using Edge technology in this traffic management system reduces the strain on cloud servers and the system becomes more reliable in real-time because the latency and bandwidth get reduced due to processing at the intermediate edge server.
LIP: Lightweight Intelligent Preprocessor for meaningful text-to-speech
Jul 11, 2022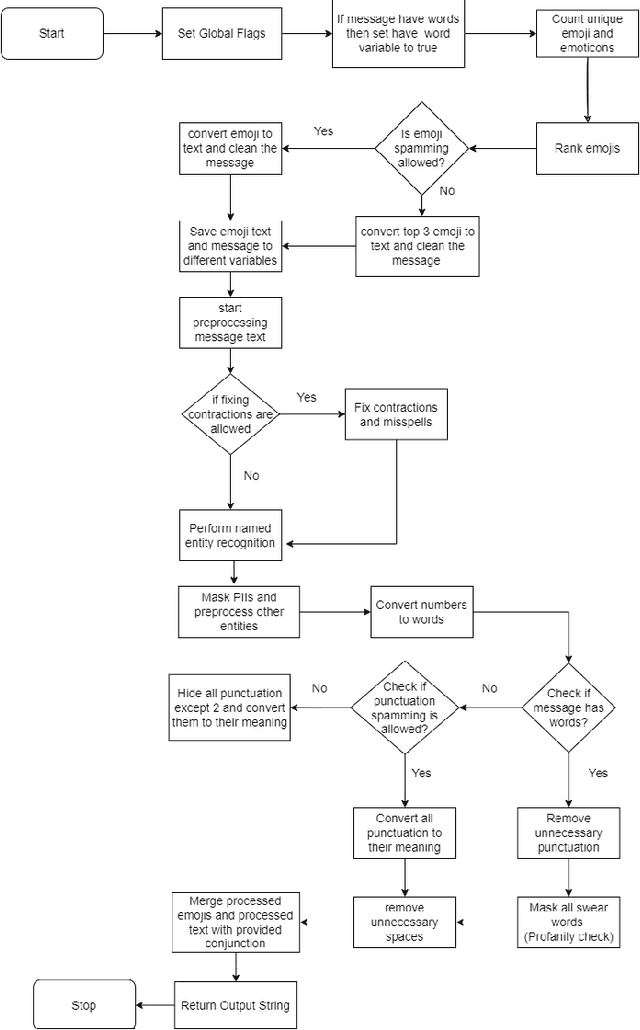
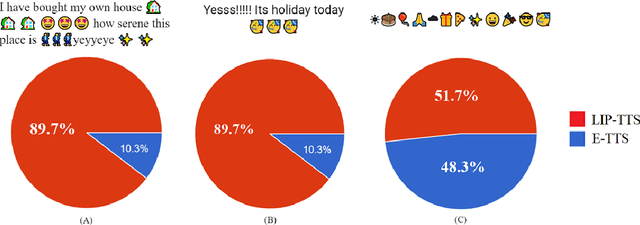
Existing Text-to-Speech (TTS) systems need to read messages from the email which may have Personal Identifiable Information (PII) to text messages that can have a streak of emojis and punctuation. 92% of the world's online population use emoji with more than 10 billion emojis sent everyday. Lack of preprocessor leads to messages being read as-is including punctuation and infographics like emoticons. This problem worsens if there is a continuous sequence of punctuation/emojis that are quite common in real-world communications like messaging, Social Networking Site (SNS) interactions, etc. In this work, we aim to introduce a lightweight intelligent preprocessor (LIP) that can enhance the readability of a message before being passed downstream to existing TTS systems. We propose multiple sub-modules including: expanding contraction, censoring swear words, and masking of PII, as part of our preprocessor to enhance the readability of text. With a memory footprint of only 3.55 MB and inference time of 4 ms for up to 50-character text, our solution is suitable for real-time deployment. This work being the first of its kind, we try to benchmark with an open independent survey, the result of which shows 76.5% preference towards LIP enabled TTS engine as compared to standard TTS.
PrivPAS: A real time Privacy-Preserving AI System and applied ethics
Feb 08, 2022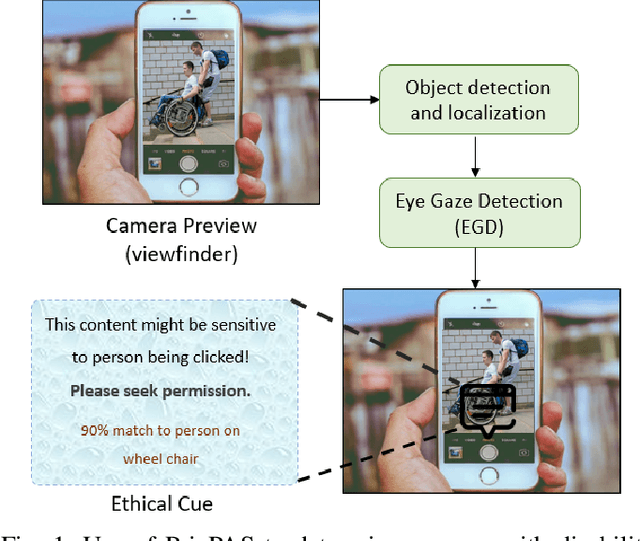

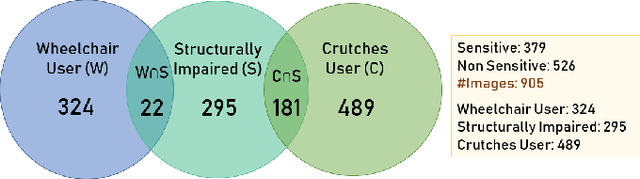

With 3.78 billion social media users worldwide in 2021 (48% of the human population), almost 3 billion images are shared daily. At the same time, a consistent evolution of smartphone cameras has led to a photography explosion with 85% of all new pictures being captured using smartphones. However, lately, there has been an increased discussion of privacy concerns when a person being photographed is unaware of the picture being taken or has reservations about the same being shared. These privacy violations are amplified for people with disabilities, who may find it challenging to raise dissent even if they are aware. Such unauthorized image captures may also be misused to gain sympathy by third-party organizations, leading to a privacy breach. Privacy for people with disabilities has so far received comparatively less attention from the AI community. This motivates us to work towards a solution to generate privacy-conscious cues for raising awareness in smartphone users of any sensitivity in their viewfinder content. To this end, we introduce PrivPAS (A real time Privacy-Preserving AI System) a novel framework to identify sensitive content. Additionally, we curate and annotate a dataset to identify and localize accessibility markers and classify whether an image is sensitive to a featured subject with a disability. We demonstrate that the proposed lightweight architecture, with a memory footprint of a mere 8.49MB, achieves a high mAP of 89.52% on resource-constrained devices. Furthermore, our pipeline, trained on face anonymized data, achieves an F1-score of 73.1%.
Language Detection Engine for Multilingual Texting on Mobile Devices
Jan 07, 2021

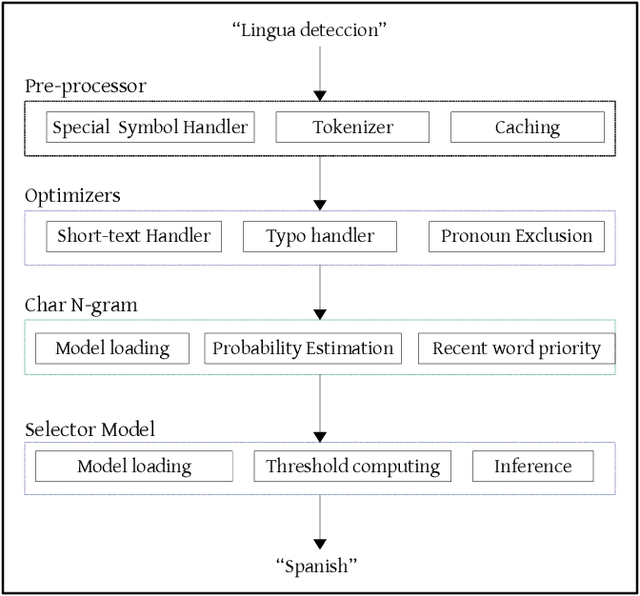

More than 2 billion mobile users worldwide type in multiple languages in the soft keyboard. On a monolingual keyboard, 38% of falsely auto-corrected words are valid in another language. This can be easily avoided by detecting the language of typed words and then validating it in its respective language. Language detection is a well-known problem in natural language processing. In this paper, we present a fast, light-weight and accurate Language Detection Engine (LDE) for multilingual typing that dynamically adapts to user intended language in real-time. We propose a novel approach where the fusion of character N-gram model and logistic regression based selector model is used to identify the language. Additionally, we present a unique method of reducing the inference time significantly by parameter reduction technique. We also discuss various optimizations fabricated across LDE to resolve ambiguity in input text among the languages with the same character pattern. Our method demonstrates an average accuracy of 94.5% for Indian languages in Latin script and that of 98% for European languages on the code-switched data. This model outperforms fastText by 60.39% and ML-Kit by 23.67% in F1 score for European languages. LDE is faster on mobile device with an average inference time of 25.91 microseconds.
* 2020 IEEE 14th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/9031474
Real-Time Optimized N-gram For Mobile Devices
Jan 07, 2021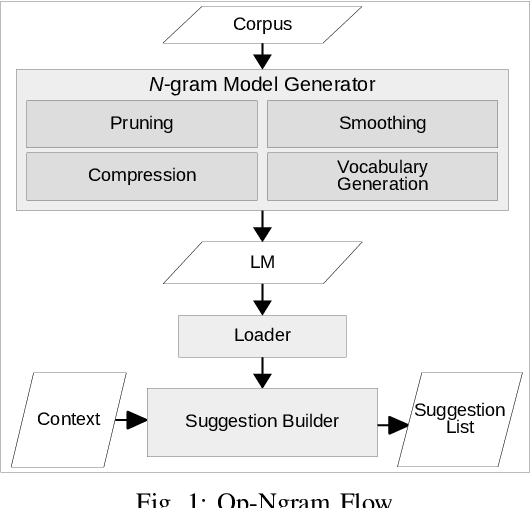
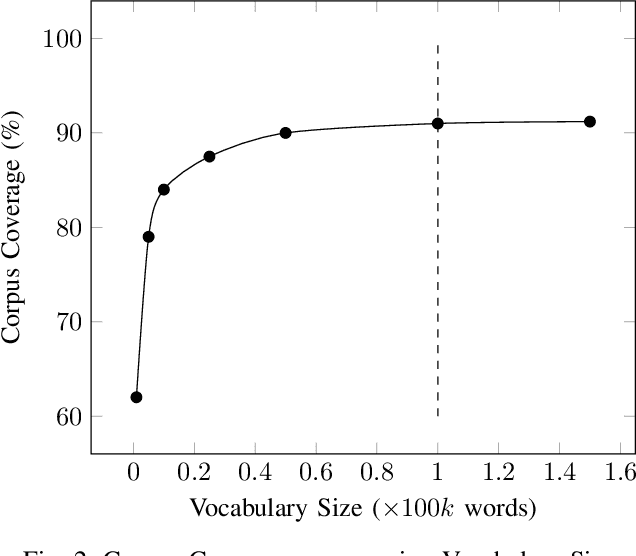
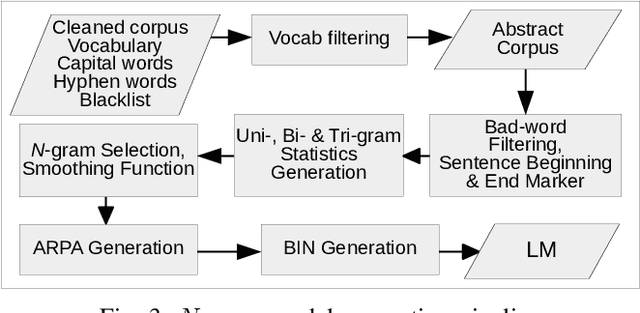

With the increasing number of mobile devices, there has been continuous research on generating optimized Language Models (LMs) for soft keyboard. In spite of advances in this domain, building a single LM for low-end feature phones as well as high-end smartphones is still a pressing need. Hence, we propose a novel technique, Optimized N-gram (Op-Ngram), an end-to-end N-gram pipeline that utilises mobile resources efficiently for faster Word Completion (WC) and Next Word Prediction (NWP). Op-Ngram applies Stupid Backoff and pruning strategies to generate a light-weight model. The LM loading time on mobile is linear with respect to model size. We observed that Op-Ngram gives 37% improvement in Language Model (LM)-ROM size, 76% in LM-RAM size, 88% in loading time and 89% in average suggestion time as compared to SORTED array variant of BerkeleyLM. Moreover, our method shows significant performance improvement over KenLM as well.
* 2019 IEEE 13th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/8665639
edATLAS: An Efficient Disambiguation Algorithm for Texting in Languages with Abugida Scripts
Jan 05, 2021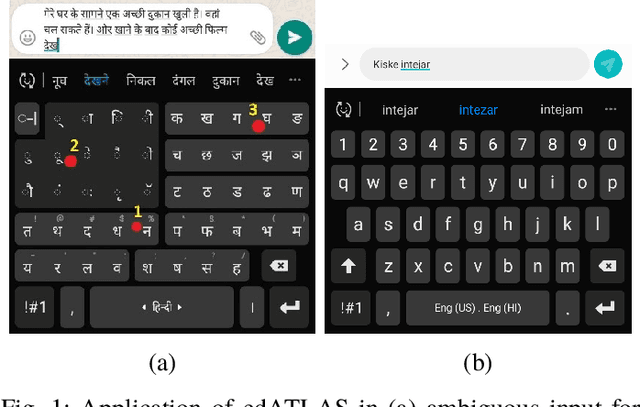
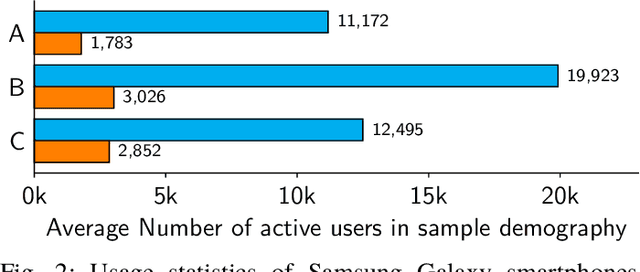
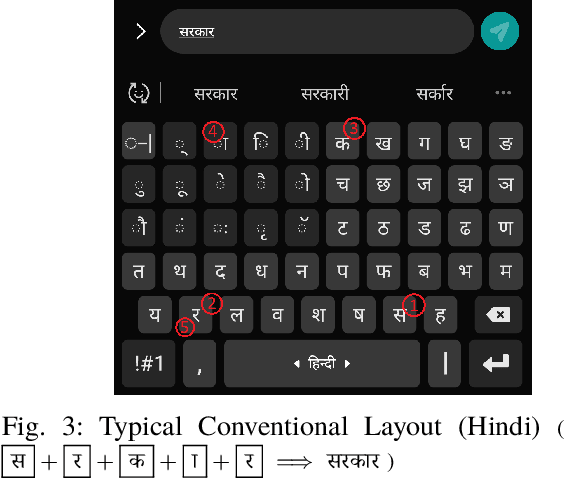
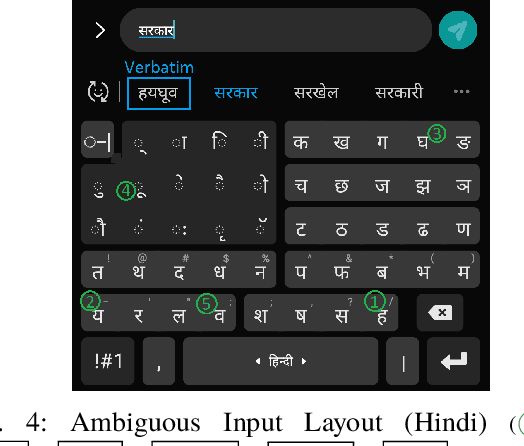
Abugida refers to a phonogram writing system where each syllable is represented using a single consonant or typographic ligature, along with a default vowel or optional diacritic(s) to denote other vowels. However, texting in these languages has some unique challenges in spite of the advent of devices with soft keyboard supporting custom key layouts. The number of characters in these languages is large enough to require characters to be spread over multiple views in the layout. Having to switch between views many times to type a single word hinders the natural thought process. This prevents popular usage of native keyboard layouts. On the other hand, supporting romanized scripts (native words transcribed using Latin characters) with language model based suggestions is also set back by the lack of uniform romanization rules. To this end, we propose a disambiguation algorithm and showcase its usefulness in two novel mutually non-exclusive input methods for languages natively using the abugida writing system: (a) disambiguation of ambiguous input for abugida scripts, and (b) disambiguation of word variants in romanized scripts. We benchmark these approaches using public datasets, and show an improvement in typing speed by 19.49%, 25.13%, and 14.89%, in Hindi, Bengali, and Thai, respectively, using Ambiguous Input, owing to the human ease of locating keys combined with the efficiency of our inference method. Our Word Variant Disambiguation (WDA) maps valid variants of romanized words, previously treated as Out-of-Vocab, to a vocabulary of 100k words with high accuracy, leading to an increase in Error Correction F1 score by 10.03% and Next Word Prediction (NWP) by 62.50% on average.
LiteMuL: A Lightweight On-Device Sequence Tagger using Multi-task Learning
Dec 15, 2020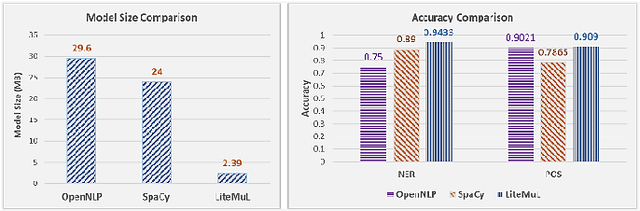
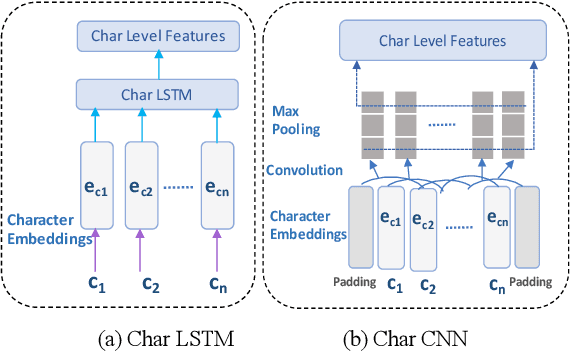
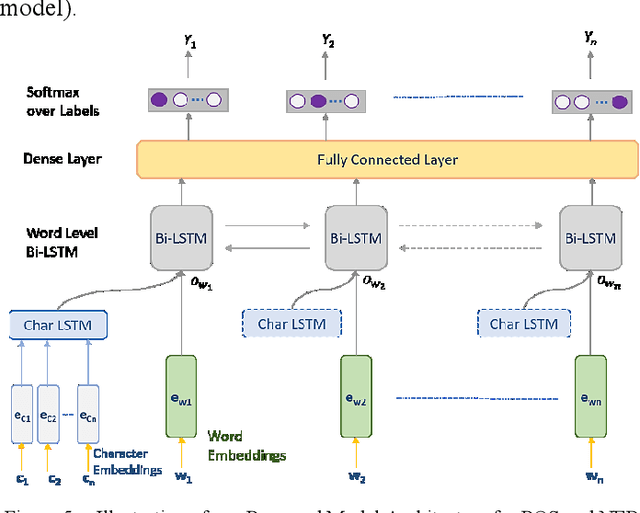
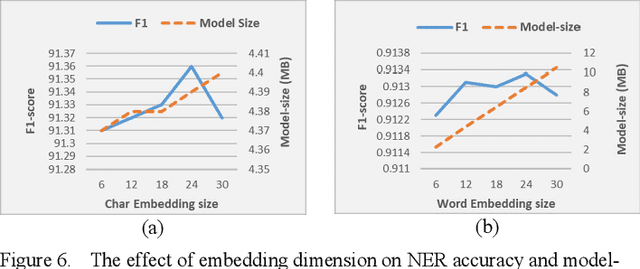
Named entity detection and Parts-of-speech tagging are the key tasks for many NLP applications. Although the current state of the art methods achieved near perfection for long, formal, structured text there are hindrances in deploying these models on memory-constrained devices such as mobile phones. Furthermore, the performance of these models is degraded when they encounter short, informal, and casual conversations. To overcome these difficulties, we present LiteMuL - a lightweight on-device sequence tagger that can efficiently process the user conversations using a Multi-Task Learning (MTL) approach. To the best of our knowledge, the proposed model is the first on-device MTL neural model for sequence tagging. Our LiteMuL model is about 2.39 MB in size and achieved an accuracy of 0.9433 (for NER), 0.9090 (for POS) on the CoNLL 2003 dataset. The proposed LiteMuL not only outperforms the current state of the art results but also surpasses the results of our proposed on-device task-specific models, with accuracy gains of up to 11% and model-size reduction by 50%-56%. Our model is competitive with other MTL approaches for NER and POS tasks while outshines them with a low memory footprint. We also evaluated our model on custom-curated user conversations and observed impressive results.