 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeclembench-2024: A Challenging, Dynamic, Complementary, Multilingual Benchmark and Underlying Flexible Framework for LLMs as Multi-Action Agents
May 31, 2024



It has been established in recent work that Large Language Models (LLMs) can be prompted to "self-play" conversational games that probe certain capabilities (general instruction following, strategic goal orientation, language understanding abilities), where the resulting interactive game play can be automatically scored. In this paper, we take one of the proposed frameworks for setting up such game-play environments, and further test its usefulness as an evaluation instrument, along a number of dimensions: We show that it can easily keep up with new developments while avoiding data contamination, we show that the tests implemented within it are not yet saturated (human performance is substantially higher than that of even the best models), and we show that it lends itself to investigating additional questions, such as the impact of the prompting language on performance. We believe that the approach forms a good basis for making decisions on model choice for building applied interactive systems, and perhaps ultimately setting up a closed-loop development environment of system and simulated evaluator.
clembench: Using Game Play to Evaluate Chat-Optimized Language Models as Conversational Agents
May 22, 2023
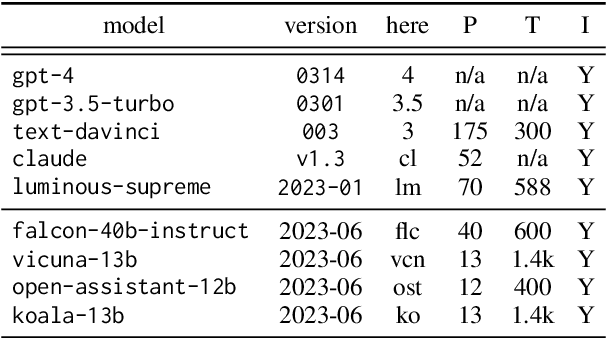
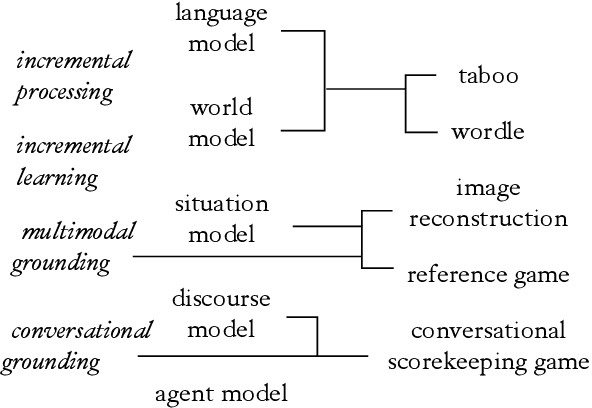
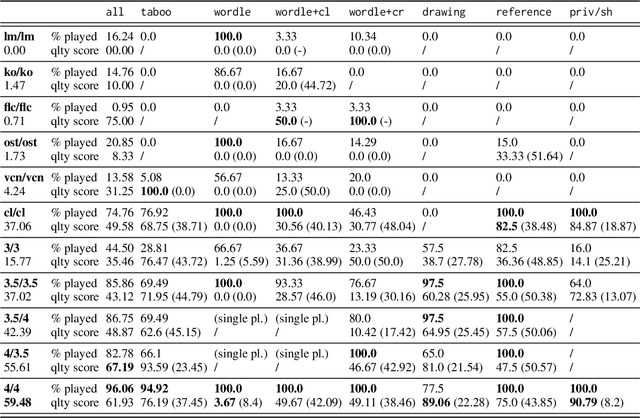
Recent work has proposed a methodology for the systematic evaluation of "Situated Language Understanding Agents"-agents that operate in rich linguistic and non-linguistic contexts-through testing them in carefully constructed interactive settings. Other recent work has argued that Large Language Models (LLMs), if suitably set up, can be understood as (simulators of) such agents. A connection suggests itself, which this paper explores: Can LLMs be evaluated meaningfully by exposing them to constrained game-like settings that are built to challenge specific capabilities? As a proof of concept, this paper investigates five interaction settings, showing that current chat-optimised LLMs are, to an extent, capable to follow game-play instructions. Both this capability and the quality of the game play, measured by how well the objectives of the different games are met, follows the development cycle, with newer models performing better. The metrics even for the comparatively simple example games are far from being saturated, suggesting that the proposed instrument will remain to have diagnostic value. Our general framework for implementing and evaluating games with LLMs is available at https://github.com/clp-research/clembench.
LiteMuL: A Lightweight On-Device Sequence Tagger using Multi-task Learning
Dec 15, 2020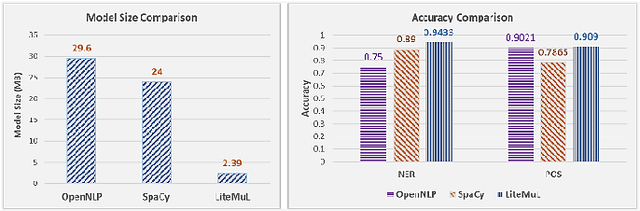
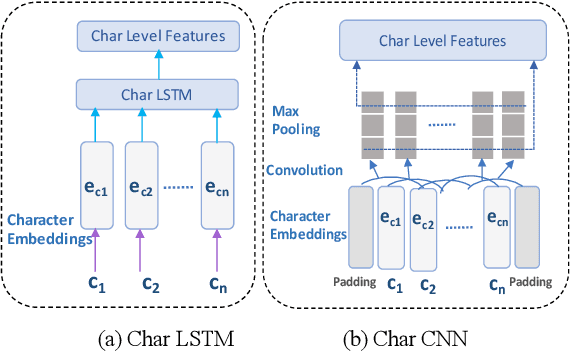
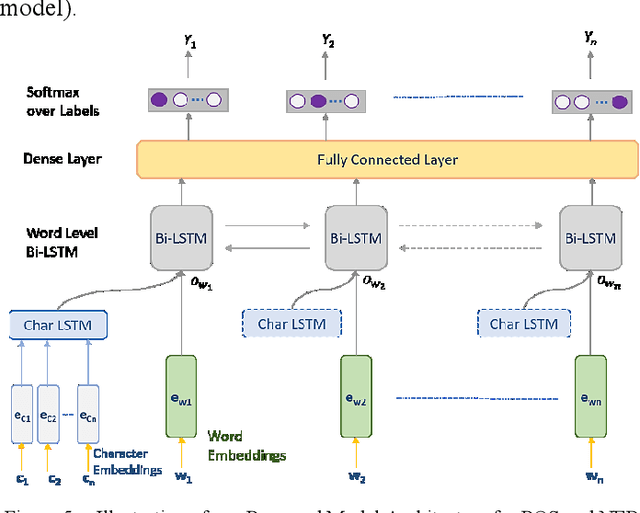
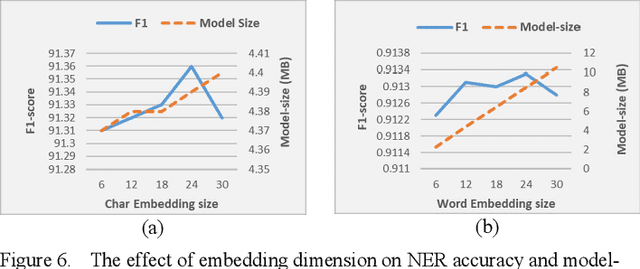
Named entity detection and Parts-of-speech tagging are the key tasks for many NLP applications. Although the current state of the art methods achieved near perfection for long, formal, structured text there are hindrances in deploying these models on memory-constrained devices such as mobile phones. Furthermore, the performance of these models is degraded when they encounter short, informal, and casual conversations. To overcome these difficulties, we present LiteMuL - a lightweight on-device sequence tagger that can efficiently process the user conversations using a Multi-Task Learning (MTL) approach. To the best of our knowledge, the proposed model is the first on-device MTL neural model for sequence tagging. Our LiteMuL model is about 2.39 MB in size and achieved an accuracy of 0.9433 (for NER), 0.9090 (for POS) on the CoNLL 2003 dataset. The proposed LiteMuL not only outperforms the current state of the art results but also surpasses the results of our proposed on-device task-specific models, with accuracy gains of up to 11% and model-size reduction by 50%-56%. Our model is competitive with other MTL approaches for NER and POS tasks while outshines them with a low memory footprint. We also evaluated our model on custom-curated user conversations and observed impressive results.
EmpLite: A Lightweight Sequence Labeling Model for Emphasis Selection of Short Texts
Dec 15, 2020
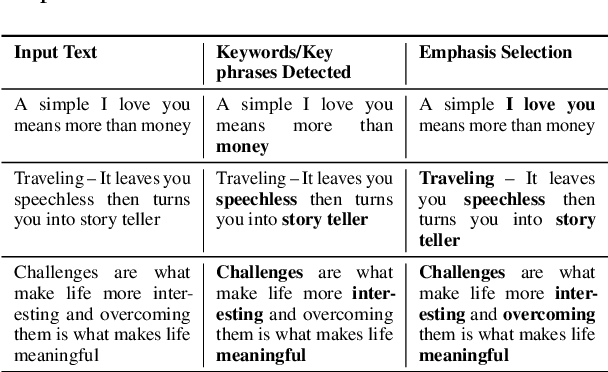

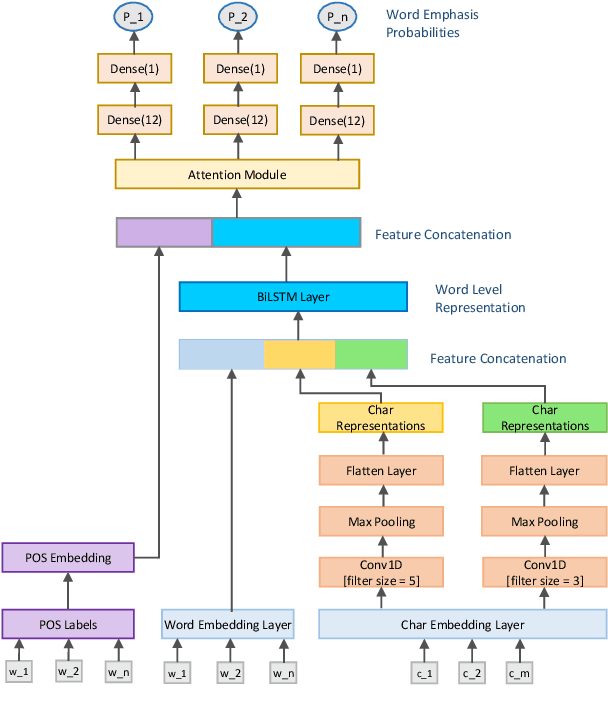
Word emphasis in textual content aims at conveying the desired intention by changing the size, color, typeface, style (bold, italic, etc.), and other typographical features. The emphasized words are extremely helpful in drawing the readers' attention to specific information that the authors wish to emphasize. However, performing such emphasis using a soft keyboard for social media interactions is time-consuming and has an associated learning curve. In this paper, we propose a novel approach to automate the emphasis word detection on short written texts. To the best of our knowledge, this work presents the first lightweight deep learning approach for smartphone deployment of emphasis selection. Experimental results show that our approach achieves comparable accuracy at a much lower model size than existing models. Our best lightweight model has a memory footprint of 2.82 MB with a matching score of 0.716 on SemEval-2020 public benchmark dataset.