 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptainCook4D: A dataset for understanding errors in procedural activities
Dec 22, 2023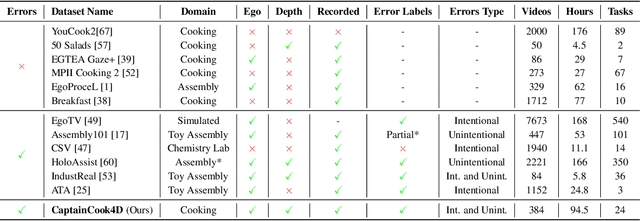


Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: supervised error recognition, multistep localization, and procedure learning
LiteMuL: A Lightweight On-Device Sequence Tagger using Multi-task Learning
Dec 15, 2020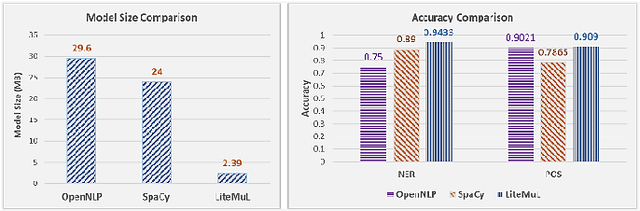
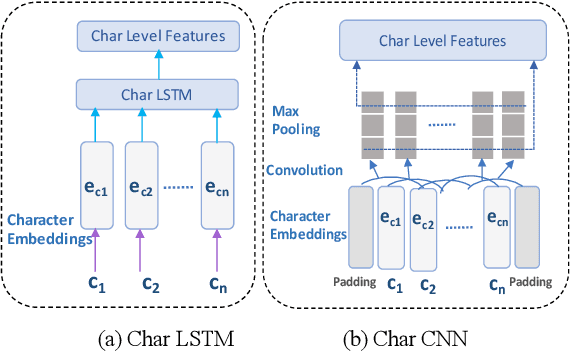
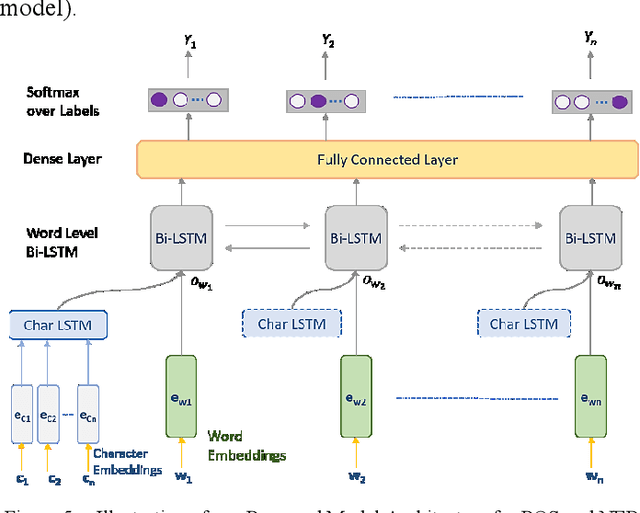
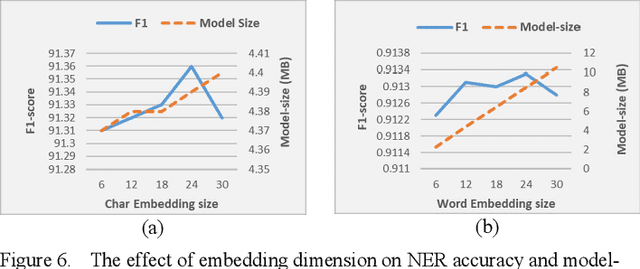
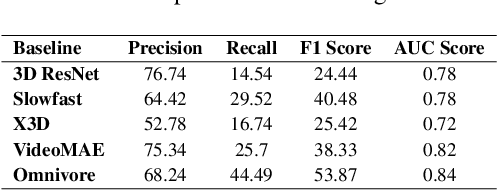
Named entity detection and Parts-of-speech tagging are the key tasks for many NLP applications. Although the current state of the art methods achieved near perfection for long, formal, structured text there are hindrances in deploying these models on memory-constrained devices such as mobile phones. Furthermore, the performance of these models is degraded when they encounter short, informal, and casual conversations. To overcome these difficulties, we present LiteMuL - a lightweight on-device sequence tagger that can efficiently process the user conversations using a Multi-Task Learning (MTL) approach. To the best of our knowledge, the proposed model is the first on-device MTL neural model for sequence tagging. Our LiteMuL model is about 2.39 MB in size and achieved an accuracy of 0.9433 (for NER), 0.9090 (for POS) on the CoNLL 2003 dataset. The proposed LiteMuL not only outperforms the current state of the art results but also surpasses the results of our proposed on-device task-specific models, with accuracy gains of up to 11% and model-size reduction by 50%-56%. Our model is competitive with other MTL approaches for NER and POS tasks while outshines them with a low memory footprint. We also evaluated our model on custom-curated user conversations and observed impressive results.
EmpLite: A Lightweight Sequence Labeling Model for Emphasis Selection of Short Texts
Dec 15, 2020
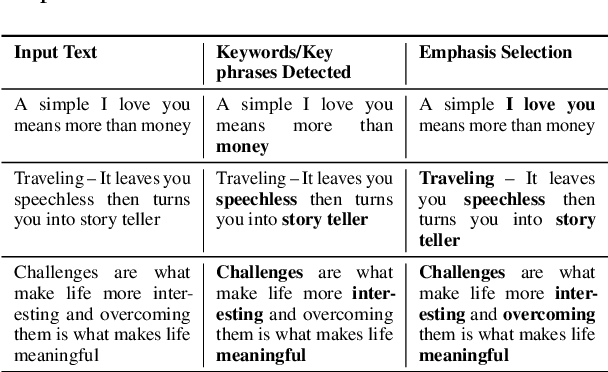

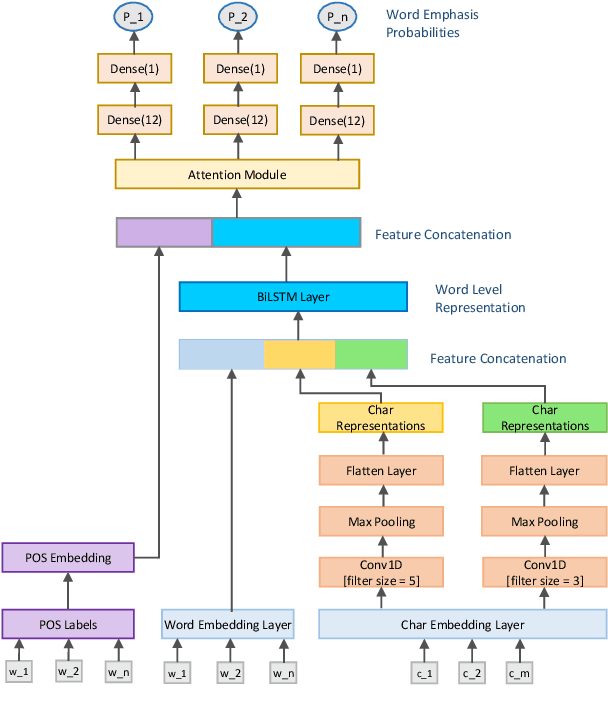
Word emphasis in textual content aims at conveying the desired intention by changing the size, color, typeface, style (bold, italic, etc.), and other typographical features. The emphasized words are extremely helpful in drawing the readers' attention to specific information that the authors wish to emphasize. However, performing such emphasis using a soft keyboard for social media interactions is time-consuming and has an associated learning curve. In this paper, we propose a novel approach to automate the emphasis word detection on short written texts. To the best of our knowledge, this work presents the first lightweight deep learning approach for smartphone deployment of emphasis selection. Experimental results show that our approach achieves comparable accuracy at a much lower model size than existing models. Our best lightweight model has a memory footprint of 2.82 MB with a matching score of 0.716 on SemEval-2020 public benchmark dataset.