 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
Jun 09, 2026Conventional LLMs keep the full KV cache loaded during decoding, causing a severe GPU memory bottleneck for ultra-long context serving. In this report, we propose Lookahead Sparse Attention (LSA), a novel inference paradigm powered by a Neural Memory Indexer built upon the DeepSeek-V4 architecture. Rather than passively attending to all historical tokens, LSA proactively predicts future context demands and preserves only the query-critical KV chunks in the GPU memory. Crucially, we instantiate this architecture via a backbone-free decoupled training strategy. By formulating the indexer as a standard dual-encoder architecture, we train it independently using standard retrieval training frameworks without ever loading the massive backbone model into GPU memory. We demonstrate that this "less is more" paradigm significantly maximizes serving efficiency while acting as an effective attention denoiser in tasks that rely on long-term global memory. Across primary long-context evaluation suites (e.g., LongBench-v2, LongMemEval, and RULER), FM-DS-V4 compresses the average physical KV cache footprint down to merely 13.5% of the full-context baseline, while consistently preserving or slightly elevating downstream accuracy (+0.6% absolute margin on average). Crucially, at extreme 500K scales, FlashMemory suppresses the physical KV cache overhead by over 90% without destabilizing the backbone's core reasoning capacities.
Training LLM Agents for Spontaneous, Reward-Free Self-Evolution via World Knowledge Exploration
Apr 20, 2026Most agents today ``self-evolve'' by following rewards and rules defined by humans. However, this process remains fundamentally dependent on external supervision; without human guidance, the evolution stops. In this work, we train agents to possess an intrinsic meta-evolution capability to spontaneously learn about unseen environments prior to task execution. To instill this ability, we design an outcome-based reward mechanism that measures how much an agent's self-generated world knowledge improves its success rate on downstream tasks. This reward signal is used exclusively during the training phase to teach the model how to explore and summarize effectively. At inference time, the agent requires no external rewards or human instructions. It spontaneously performs native self-evolution to adapt to unknown environments using its internal parameters. When applied to Qwen3-30B and Seed-OSS-36B, this shift to native evolution yields a 20% performance increase on WebVoyager and WebWalker. Most strikingly, the generated world knowledge even enables a compact 14B Qwen3 model to outperform the unassisted Gemini-2.5-Flash, establishing a new paradigm for truly evolving agents.
From Local Matches to Global Masks: Novel Instance Detection in Open-World Scenes
Mar 03, 2026Detecting and segmenting novel object instances in open-world environments is a fundamental problem in robotic perception. Given only a small set of template images, a robot must locate and segment a specific object instance in a cluttered, previously unseen scene. Existing proposal-based approaches are highly sensitive to proposal quality and often fail under occlusion and background clutter. We propose L2G-Det, a local-to-global instance detection framework that bypasses explicit object proposals by leveraging dense patch-level matching between templates and the query image. Locally matched patches generate candidate points, which are refined through a candidate selection module to suppress false positives. The filtered points are then used to prompt an augmented Segment Anything Model (SAM) with instance-specific object tokens, enabling reliable reconstruction of complete instance masks. Experiments demonstrate improved performance over proposal-based methods in challenging open-world settings.
Exposing Weaknesses of Large Reasoning Models through Graph Algorithm Problems
Feb 06, 2026Large Reasoning Models (LRMs) have advanced rapidly; however, existing benchmarks in mathematics, code, and common-sense reasoning remain limited. They lack long-context evaluation, offer insufficient challenge, and provide answers that are difficult to verify programmatically. We introduce GrAlgoBench, a benchmark designed to evaluate LRMs through graph algorithm problems. Such problems are particularly well suited for probing reasoning abilities: they demand long-context reasoning, allow fine-grained control of difficulty levels, and enable standardized, programmatic evaluation. Across nine tasks, our systematic experiments reveal two major weaknesses of current LRMs. First, accuracy deteriorates sharply as context length increases, falling below 50% once graphs exceed 120 nodes. This degradation is driven by frequent execution errors, weak memory, and redundant reasoning. Second, LRMs suffer from an over-thinking phenomenon, primarily caused by extensive yet largely ineffective self-verification, which inflates reasoning traces without improving correctness. By exposing these limitations, GrAlgoBench establishes graph algorithm problems as a rigorous, multidimensional, and practically relevant testbed for advancing the study of reasoning in LRMs. Code is available at https://github.com/Bklight999/GrAlgoBench.
Improving LLMs' Generalized Reasoning Abilities by Graph Problems
Jul 23, 2025Large Language Models (LLMs) have made remarkable strides in reasoning tasks, yet their performance often falters on novel and complex problems. Domain-specific continued pretraining (CPT) methods, such as those tailored for mathematical reasoning, have shown promise but lack transferability to broader reasoning tasks. In this work, we pioneer the use of Graph Problem Reasoning (GPR) to enhance the general reasoning capabilities of LLMs. GPR tasks, spanning pathfinding, network analysis, numerical computation, and topological reasoning, require sophisticated logical and relational reasoning, making them ideal for teaching diverse reasoning patterns. To achieve this, we introduce GraphPile, the first large-scale corpus specifically designed for CPT using GPR data. Spanning 10.9 billion tokens across 23 graph tasks, the dataset includes chain-of-thought, program-of-thought, trace of execution, and real-world graph data. Using GraphPile, we train GraphMind on popular base models Llama 3 and 3.1, as well as Gemma 2, achieving up to 4.9 percent higher accuracy in mathematical reasoning and up to 21.2 percent improvement in non-mathematical reasoning tasks such as logical and commonsense reasoning. By being the first to harness GPR for enhancing reasoning patterns and introducing the first dataset of its kind, our work bridges the gap between domain-specific pretraining and universal reasoning capabilities, advancing the adaptability and robustness of LLMs.
R$^2$: A LLM Based Novel-to-Screenplay Generation Framework with Causal Plot Graphs
Mar 19, 2025



Automatically adapting novels into screenplays is important for the TV, film, or opera industries to promote products with low costs. The strong performances of large language models (LLMs) in long-text generation call us to propose a LLM based framework Reader-Rewriter (R$^2$) for this task. However, there are two fundamental challenges here. First, the LLM hallucinations may cause inconsistent plot extraction and screenplay generation. Second, the causality-embedded plot lines should be effectively extracted for coherent rewriting. Therefore, two corresponding tactics are proposed: 1) A hallucination-aware refinement method (HAR) to iteratively discover and eliminate the affections of hallucinations; and 2) a causal plot-graph construction method (CPC) based on a greedy cycle-breaking algorithm to efficiently construct plot lines with event causalities. Recruiting those efficient techniques, R$^2$ utilizes two modules to mimic the human screenplay rewriting process: The Reader module adopts a sliding window and CPC to build the causal plot graphs, while the Rewriter module generates first the scene outlines based on the graphs and then the screenplays. HAR is integrated into both modules for accurate inferences of LLMs. Experimental results demonstrate the superiority of R$^2$, which substantially outperforms three existing approaches (51.3%, 22.6%, and 57.1% absolute increases) in pairwise comparison at the overall win rate for GPT-4o.
GCoder: Improving Large Language Model for Generalized Graph Problem Solving
Oct 24, 2024
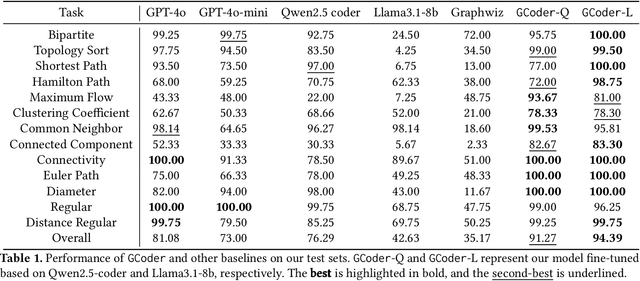


Large Language Models (LLMs) have demonstrated strong reasoning abilities, making them suitable for complex tasks such as graph computation. Traditional reasoning steps paradigm for graph problems is hindered by unverifiable steps, limited long-term reasoning, and poor generalization to graph variations. To overcome these limitations, we introduce GCoder, a code-based LLM designed to enhance problem-solving in generalized graph computation problems. Our method involves constructing an extensive training dataset, GraphWild, featuring diverse graph formats and algorithms. We employ a multi-stage training process, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Compiler Feedback (RLCF), to refine model capabilities. For unseen tasks, a hybrid retrieval technique is used to augment performance. Experiments demonstrate that GCoder outperforms GPT-4o, with an average accuracy improvement of 16.42% across various graph computational problems. Furthermore, GCoder efficiently manages large-scale graphs with millions of nodes and diverse input formats, overcoming the limitations of previous models focused on the reasoning steps paradigm. This advancement paves the way for more intuitive and effective graph problem-solving using LLMs. Code and data are available at here: https://github.com/Bklight999/WWW25-GCoder/tree/master.
Continual Distillation Learning
Jul 18, 2024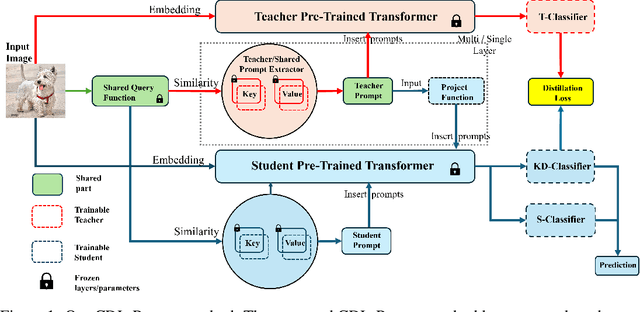



We study the problem of Continual Distillation Learning (CDL) that considers Knowledge Distillation (KD) in the Continual Learning (CL) setup. A teacher model and a student model need to learn a sequence of tasks, and the knowledge of the teacher model will be distilled to the student to improve the student model. We introduce a novel method named CDL-Prompt that utilizes prompt-based continual learning models to build the teacher-student model. We investigate how to utilize the prompts of the teacher model in the student model for knowledge distillation, and propose an attention-based prompt mapping scheme to use the teacher prompts for the student. We demonstrate that our method can be applied to different prompt-based continual learning models such as L2P, DualPrompt and CODA-Prompt to improve their performance using powerful teacher models. Although recent CL methods focus on prompt learning, we show that our method can be utilized to build efficient CL models using prompt-based knowledge distillation.
GraphArena: Benchmarking Large Language Models on Graph Computational Problems
Jun 29, 2024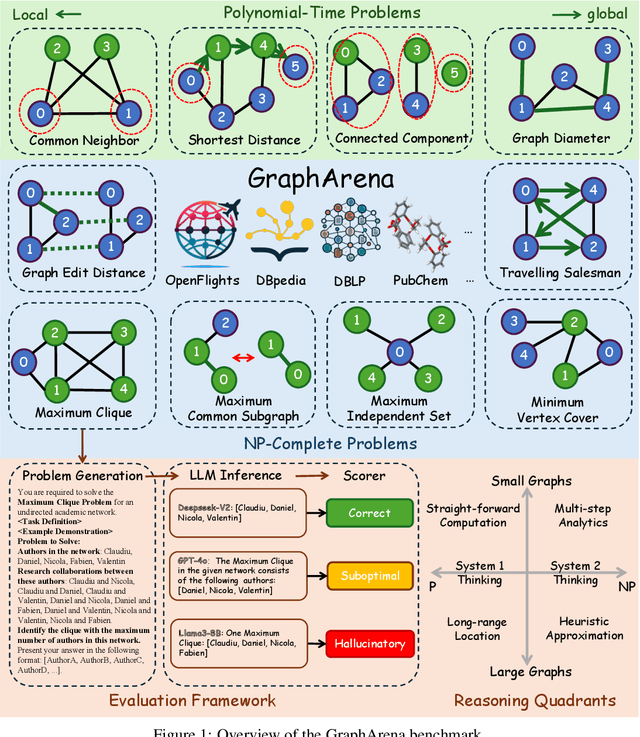
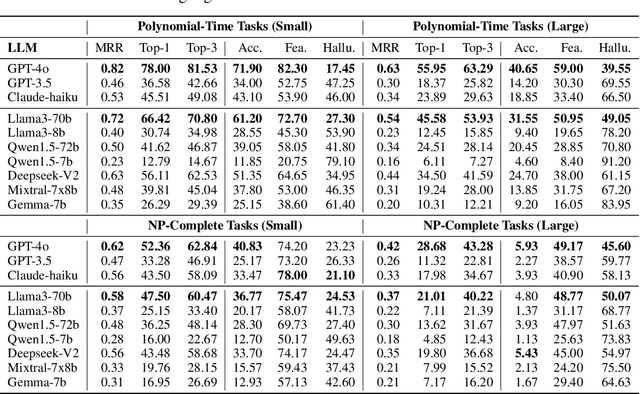
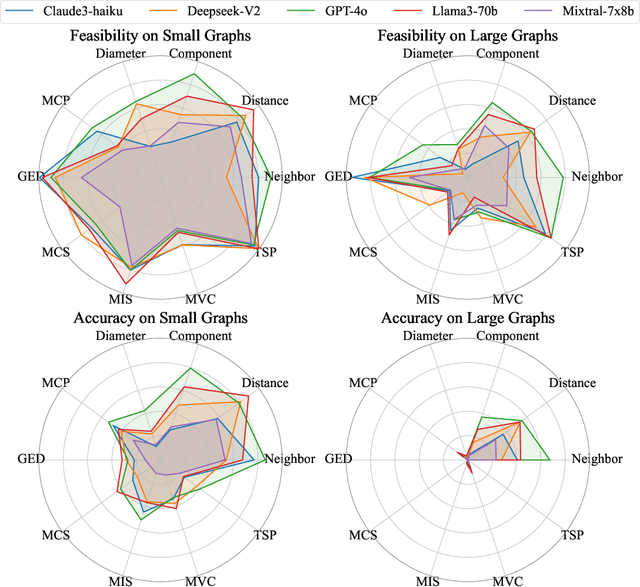
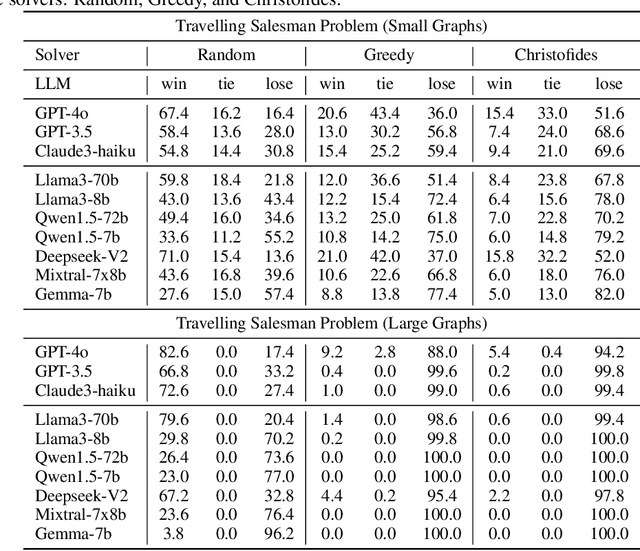
The "arms race" of Large Language Models (LLMs) demands novel, challenging, and diverse benchmarks to faithfully examine their progresses. We introduce GraphArena, a benchmarking tool designed to evaluate LLMs on graph computational problems using million-scale real-world graphs from diverse scenarios such as knowledge graphs, social networks, and molecular structures. GraphArena offers a suite of 10 computational tasks, encompassing four polynomial-time (e.g., Shortest Distance) and six NP-complete challenges (e.g., Travelling Salesman Problem). It features a rigorous evaluation framework that classifies LLM outputs as correct, suboptimal (feasible but not optimal), or hallucinatory (properly formatted but infeasible). Evaluation of 10 leading LLMs, including GPT-4o and LLaMA3-70B-Instruct, reveals that even top-performing models struggle with larger, more complex graph problems and exhibit hallucination issues. Despite the application of strategies such as chain-of-thought prompting, these issues remain unresolved. GraphArena contributes a valuable supplement to the existing LLM benchmarks and is open-sourced at https://github.com/squareRoot3/GraphArena.
HO-Cap: A Capture System and Dataset for 3D Reconstruction and Pose Tracking of Hand-Object Interaction
Jun 10, 2024



We introduce a data capture system and a new dataset named HO-Cap that can be used to study 3D reconstruction and pose tracking of hands and objects in videos. The capture system uses multiple RGB-D cameras and a HoloLens headset for data collection, avoiding the use of expensive 3D scanners or mocap systems. We propose a semi-automatic method to obtain annotations of shape and pose of hands and objects in the collected videos, which significantly reduces the required annotation time compared to manual labeling. With this system, we captured a video dataset of humans using objects to perform different tasks, as well as simple pick-and-place and handover of an object from one hand to the other, which can be used as human demonstrations for embodied AI and robot manipulation research. Our data capture setup and annotation framework can be used by the community to reconstruct 3D shapes of objects and human hands and track their poses in videos.