 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLMs' Generalized Reasoning Abilities by Graph Problems
Jul 23, 2025Large Language Models (LLMs) have made remarkable strides in reasoning tasks, yet their performance often falters on novel and complex problems. Domain-specific continued pretraining (CPT) methods, such as those tailored for mathematical reasoning, have shown promise but lack transferability to broader reasoning tasks. In this work, we pioneer the use of Graph Problem Reasoning (GPR) to enhance the general reasoning capabilities of LLMs. GPR tasks, spanning pathfinding, network analysis, numerical computation, and topological reasoning, require sophisticated logical and relational reasoning, making them ideal for teaching diverse reasoning patterns. To achieve this, we introduce GraphPile, the first large-scale corpus specifically designed for CPT using GPR data. Spanning 10.9 billion tokens across 23 graph tasks, the dataset includes chain-of-thought, program-of-thought, trace of execution, and real-world graph data. Using GraphPile, we train GraphMind on popular base models Llama 3 and 3.1, as well as Gemma 2, achieving up to 4.9 percent higher accuracy in mathematical reasoning and up to 21.2 percent improvement in non-mathematical reasoning tasks such as logical and commonsense reasoning. By being the first to harness GPR for enhancing reasoning patterns and introducing the first dataset of its kind, our work bridges the gap between domain-specific pretraining and universal reasoning capabilities, advancing the adaptability and robustness of LLMs.
Decentralized Uplink Adaptive Compression for Cell-Free MIMO with Limited Fronthaul
Jun 12, 2025We study the problem of uplink compression for cell-free multi-input multi-output networks with limited fronthaul capacity. In compress-forward mode, remote radio heads (RRHs) compress the received signal and forward it to a central unit for joint processing. While previous work has focused on a transform-based approach, which optimizes the transform matrix that reduces signals of high dimension to a static pre-determined lower dimension, we propose a rate-based approach that simultaneously finds both dimension and compression adaptively. Our approach accommodates for changes to network traffic and fronthaul limits. Using mutual information as the objective, we obtain the theoretical network capacity for adaptive compression and decouple the expression to enable decentralization. Furthermore, using channel statistics and user traffic density, we show different approaches to compute an efficient representation of side information that summarizes global channel state information and is shared with RRHs to assist compression. While keeping the information exchange overhead low, our decentralized implementation of adaptive compression shows competitive overall network performance compared to a centralized approach.
Uplink resource allocation optimization for user-centric cell-free MIMO networks
Jun 08, 2024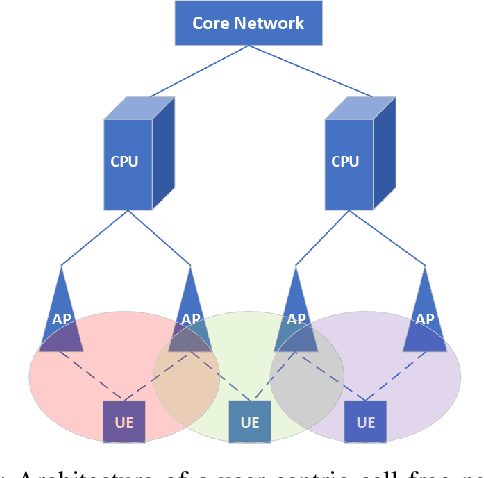
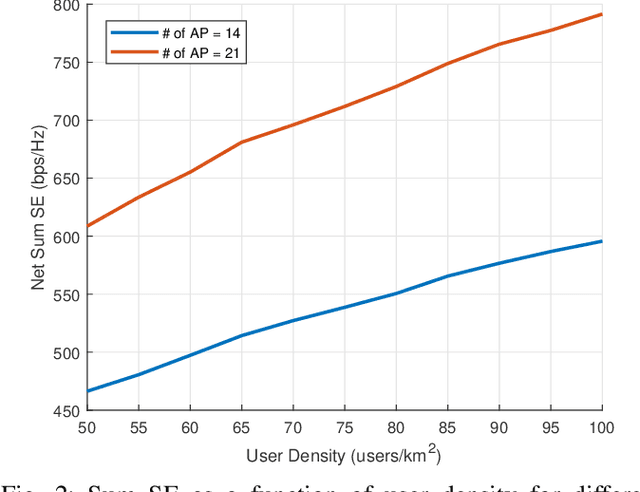
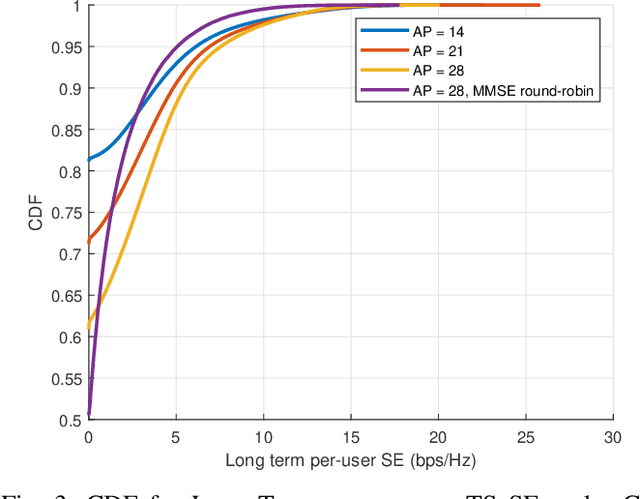
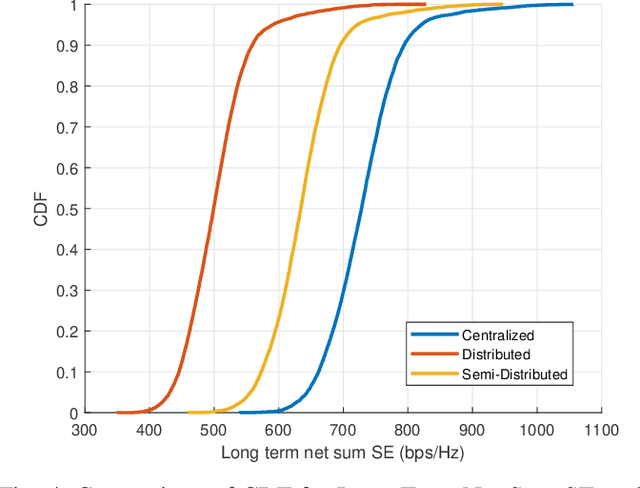
We examine the problem of optimizing resource allocation in the uplink for a user-centric, cell-free, multi-input multi-output network. We start by modeling and developing resource allocation algorithms for two standard network operation modes. The centralized mode provides high data rates but suffers multiple issues, including scalability. On the other hand, the distributed mode has the opposite problem: relatively low rates, but is scalable. To address these challenges, we combine the strength of the two standard modes, creating a new semi-distributed operation mode. To avoid the need for information exchange between access points, we introduce a new quality of service metric to decentralize the resource allocation algorithms. Our results show that we can eliminate the need for information exchange with a relatively small penalty on data rates.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
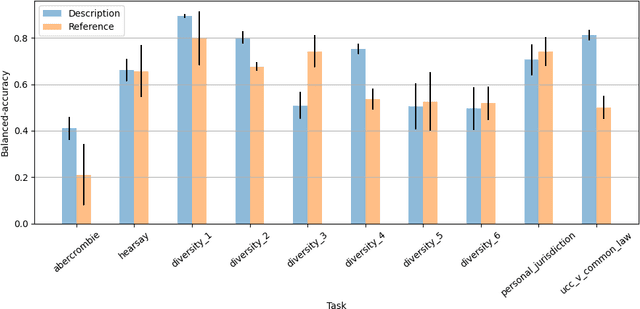
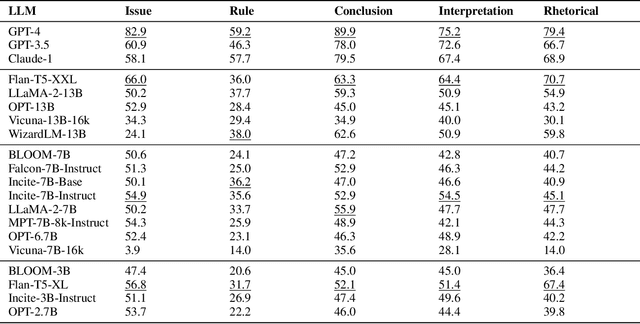
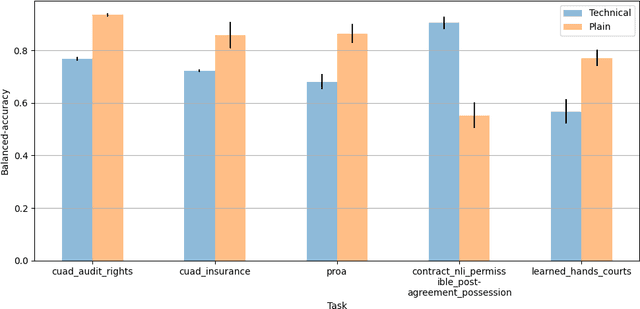
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
Matching Tweets With Applicable Fact-Checks Across Languages
Feb 14, 2022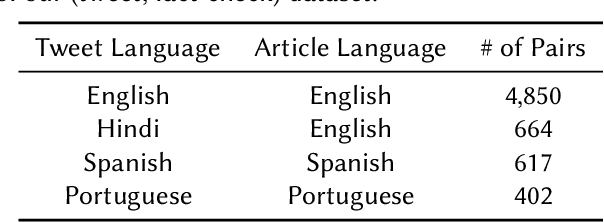
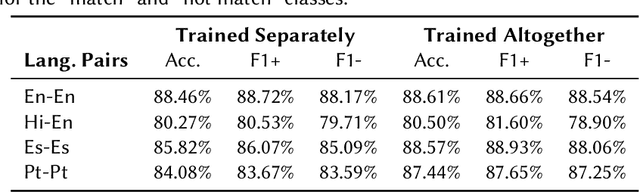
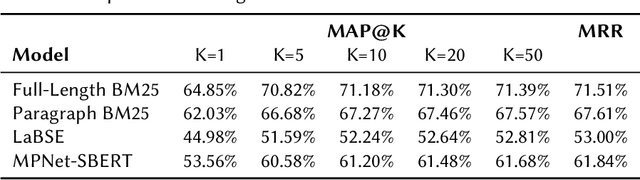
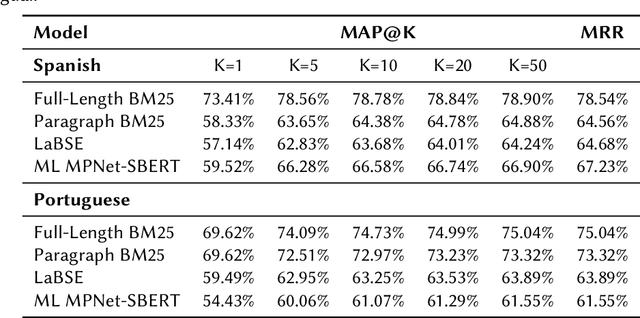
An important challenge for news fact-checking is the effective dissemination of existing fact-checks. This in turn brings the need for reliable methods to detect previously fact-checked claims. In this paper, we focus on automatically finding existing fact-checks for claims made in social media posts (tweets). We conduct both classification and retrieval experiments, in monolingual (English only), multilingual (Spanish, Portuguese), and cross-lingual (Hindi-English) settings using multilingual transformer models such as XLM-RoBERTa and multilingual embeddings such as LaBSE and SBERT. We present promising results for "match" classification (93% average accuracy) in four language pairs. We also find that a BM25 baseline outperforms state-of-the-art multilingual embedding models for the retrieval task during our monolingual experiments. We highlight and discuss NLP challenges while addressing this problem in different languages, and we introduce a novel curated dataset of fact-checks and corresponding tweets for future research.
Extractive and Abstractive Explanations for Fact-Checking and Evaluation of News
Apr 27, 2021


In this paper, we explore the construction of natural language explanations for news claims, with the goal of assisting fact-checking and news evaluation applications. We experiment with two methods: (1) an extractive method based on Biased TextRank -- a resource-effective unsupervised graph-based algorithm for content extraction; and (2) an abstractive method based on the GPT-2 language model. We perform comparative evaluations on two misinformation datasets in the political and health news domains, and find that the extractive method shows the most promise.