 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBelief-Sim: Towards Belief-Driven Simulation of Demographic Misinformation Susceptibility
Mar 03, 2026Misinformation is a growing societal threat, and susceptibility to misinformative claims varies across demographic groups due to differences in underlying beliefs. As Large Language Models (LLMs) are increasingly used to simulate human behaviors, we investigate whether they can simulate demographic misinformation susceptibility, treating beliefs as a primary driving factor. We introduce BeliefSim, a simulation framework that constructs demographic belief profiles using psychology-informed taxonomies and survey priors. We study prompt-based conditioning and post-training adaptation, and conduct a multi-fold evaluation using: (i) susceptibility accuracy and (ii) counterfactual demographic sensitivity. Across both datasets and modeling strategies, we show that beliefs provide a strong prior for simulating misinformation susceptibility, with accuracy up to 92%.
Persuasion at Play: Understanding Misinformation Dynamics in Demographic-Aware Human-LLM Interactions
Mar 03, 2025



Existing challenges in misinformation exposure and susceptibility vary across demographic groups, as some populations are more vulnerable to misinformation than others. Large language models (LLMs) introduce new dimensions to these challenges through their ability to generate persuasive content at scale and reinforcing existing biases. This study investigates the bidirectional persuasion dynamics between LLMs and humans when exposed to misinformative content. We analyze human-to-LLM influence using human-stance datasets and assess LLM-to-human influence by generating LLM-based persuasive arguments. Additionally, we use a multi-agent LLM framework to analyze the spread of misinformation under persuasion among demographic-oriented LLM agents. Our findings show that demographic factors influence susceptibility to misinformation in LLMs, closely reflecting the demographic-based patterns seen in human susceptibility. We also find that, similar to human demographic groups, multi-agent LLMs exhibit echo chamber behavior. This research explores the interplay between humans and LLMs, highlighting demographic differences in the context of misinformation and offering insights for future interventions.
Examining Spanish Counseling with MIDAS: a Motivational Interviewing Dataset in Spanish
Feb 12, 2025



Cultural and language factors significantly influence counseling, but Natural Language Processing research has not yet examined whether the findings of conversational analysis for counseling conducted in English apply to other languages. This paper presents a first step towards this direction. We introduce MIDAS (Motivational Interviewing Dataset in Spanish), a counseling dataset created from public video sources that contains expert annotations for counseling reflections and questions. Using this dataset, we explore language-based differences in counselor behavior in English and Spanish and develop classifiers in monolingual and multilingual settings, demonstrating its applications in counselor behavioral coding tasks.
VERVE: Template-based ReflectiVE Rewriting for MotiVational IntErviewing
Nov 14, 2023



Reflective listening is a fundamental skill that counselors must acquire to achieve proficiency in motivational interviewing (MI). It involves responding in a manner that acknowledges and explores the meaning of what the client has expressed in the conversation. In this work, we introduce the task of counseling response rewriting, which transforms non-reflective statements into reflective responses. We introduce VERVE, a template-based rewriting system with paraphrase-augmented training and adaptive template updating. VERVE first creates a template by identifying and filtering out tokens that are not relevant to reflections and constructs a reflective response using the template. Paraphrase-augmented training allows the model to learn less-strict fillings of masked spans, and adaptive template updating helps discover effective templates for rewriting without significantly removing the original content. Using both automatic and human evaluations, we compare our method against text rewriting baselines and show that our framework is effective in turning non-reflective statements into more reflective responses while achieving a good content preservation-reflection style trade-off.
Adaptable Claim Rewriting with Offline Reinforcement Learning for Effective Misinformation Discovery
Oct 14, 2022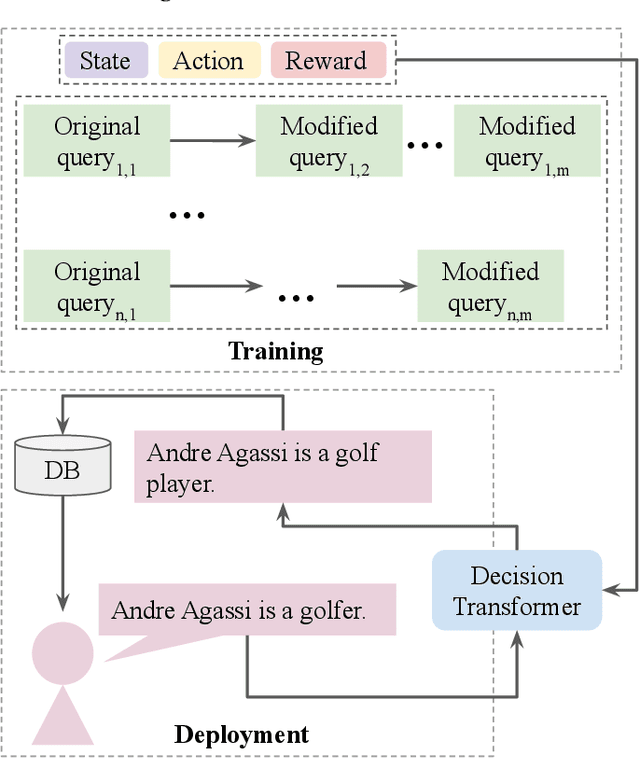
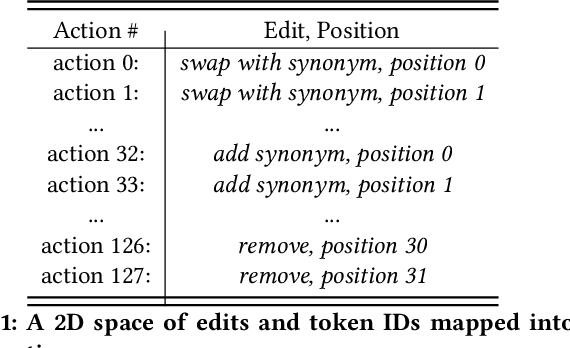
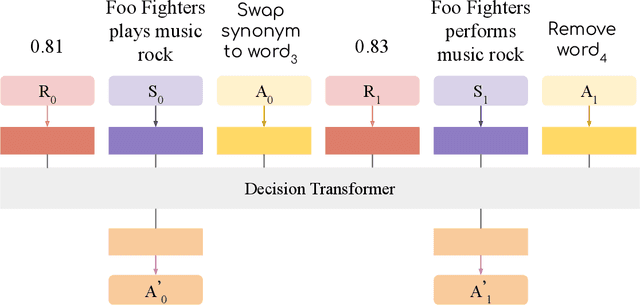

We propose a novel system to help fact-checkers formulate search queries for known misinformation claims and effectively search across multiple social media platforms. We introduce an adaptable rewriting strategy, where editing actions (e.g., swap a word with its synonym; change verb tense into present simple) for queries containing claims are automatically learned through offline reinforcement learning. Specifically, we use a decision transformer to learn a sequence of editing actions that maximize query retrieval metrics such as mean average precision. Through several experiments, we show that our approach can increase the effectiveness of the queries by up to 42\% relatively, while producing editing action sequences that are human readable, thus making the system easy to use and explain.
Matching Tweets With Applicable Fact-Checks Across Languages
Feb 14, 2022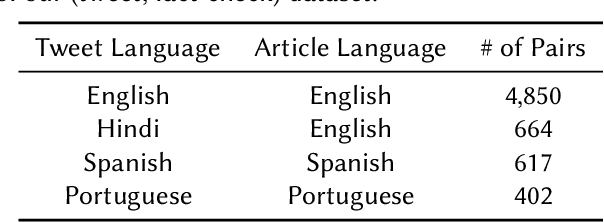
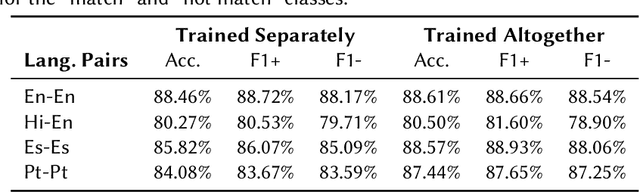
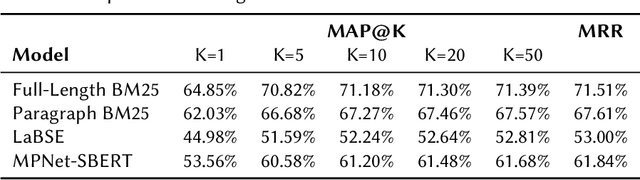
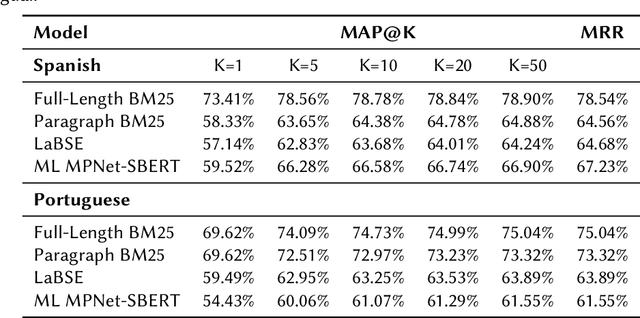
An important challenge for news fact-checking is the effective dissemination of existing fact-checks. This in turn brings the need for reliable methods to detect previously fact-checked claims. In this paper, we focus on automatically finding existing fact-checks for claims made in social media posts (tweets). We conduct both classification and retrieval experiments, in monolingual (English only), multilingual (Spanish, Portuguese), and cross-lingual (Hindi-English) settings using multilingual transformer models such as XLM-RoBERTa and multilingual embeddings such as LaBSE and SBERT. We present promising results for "match" classification (93% average accuracy) in four language pairs. We also find that a BM25 baseline outperforms state-of-the-art multilingual embedding models for the retrieval task during our monolingual experiments. We highlight and discuss NLP challenges while addressing this problem in different languages, and we introduce a novel curated dataset of fact-checks and corresponding tweets for future research.
Exploring Self-Identified Counseling Expertise in Online Support Forums
Jun 24, 2021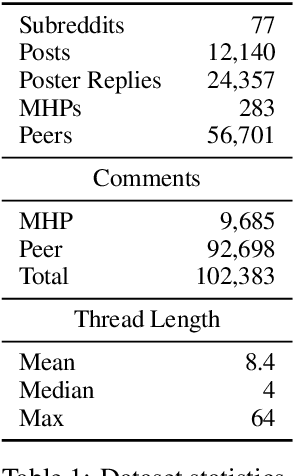
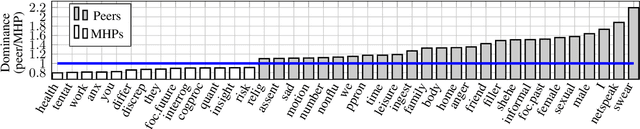

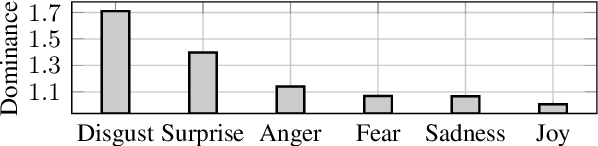
A growing number of people engage in online health forums, making it important to understand the quality of the advice they receive. In this paper, we explore the role of expertise in responses provided to help-seeking posts regarding mental health. We study the differences between (1) interactions with peers; and (2) interactions with self-identified mental health professionals. First, we show that a classifier can distinguish between these two groups, indicating that their language use does in fact differ. To understand this difference, we perform several analyses addressing engagement aspects, including whether their comments engage the support-seeker further as well as linguistic aspects, such as dominant language and linguistic style matching. Our work contributes toward the developing efforts of understanding how health experts engage with health information- and support-seekers in social networks. More broadly, it is a step toward a deeper understanding of the styles of interactions that cultivate supportive engagement in online communities.
Extractive and Abstractive Explanations for Fact-Checking and Evaluation of News
Apr 27, 2021


In this paper, we explore the construction of natural language explanations for news claims, with the goal of assisting fact-checking and news evaluation applications. We experiment with two methods: (1) an extractive method based on Biased TextRank -- a resource-effective unsupervised graph-based algorithm for content extraction; and (2) an abstractive method based on the GPT-2 language model. We perform comparative evaluations on two misinformation datasets in the political and health news domains, and find that the extractive method shows the most promise.
Exploring the Value of Personalized Word Embeddings
Nov 11, 2020
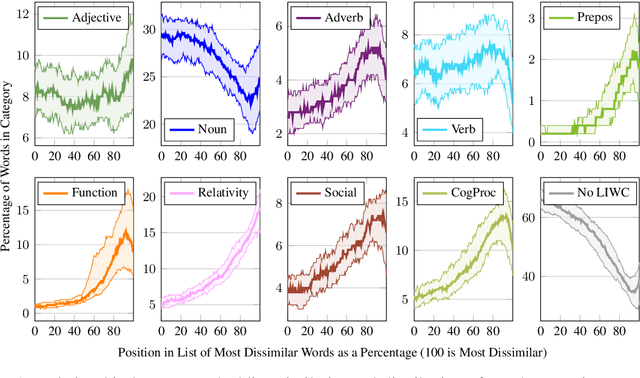
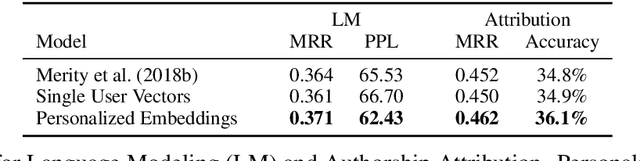
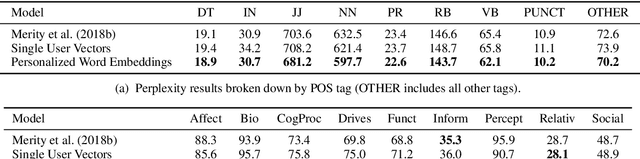
In this paper, we introduce personalized word embeddings, and examine their value for language modeling. We compare the performance of our proposed prediction model when using personalized versus generic word representations, and study how these representations can be leveraged for improved performance. We provide insight into what types of words can be more accurately predicted when building personalized models. Our results show that a subset of words belonging to specific psycholinguistic categories tend to vary more in their representations across users and that combining generic and personalized word embeddings yields the best performance, with a 4.7% relative reduction in perplexity. Additionally, we show that a language model using personalized word embeddings can be effectively used for authorship attribution.
Biased TextRank: Unsupervised Graph-Based Content Extraction
Nov 02, 2020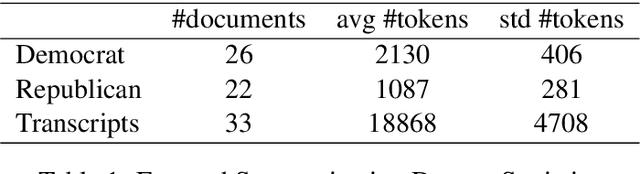
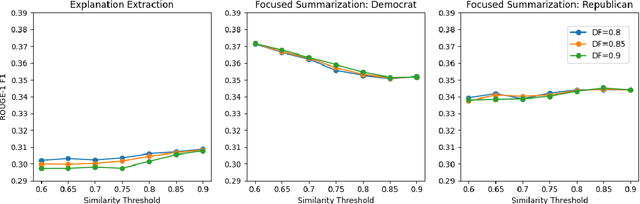
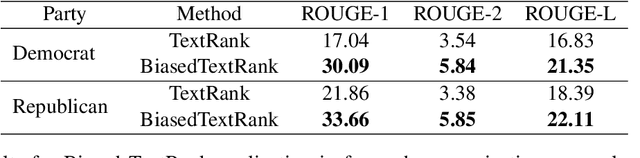

We introduce Biased TextRank, a graph-based content extraction method inspired by the popular TextRank algorithm that ranks text spans according to their importance for language processing tasks and according to their relevance to an input "focus." Biased TextRank enables focused content extraction for text by modifying the random restarts in the execution of TextRank. The random restart probabilities are assigned based on the relevance of the graph nodes to the focus of the task. We present two applications of Biased TextRank: focused summarization and explanation extraction, and show that our algorithm leads to improved performance on two different datasets by significant ROUGE-N score margins. Much like its predecessor, Biased TextRank is unsupervised, easy to implement and orders of magnitude faster and lighter than current state-of-the-art Natural Language Processing methods for similar tasks.