 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraming Migration: A Computational Analysis of UK Parliamentary Discourse
Sep 17, 2025We present a large-scale computational analysis of migration-related discourse in UK parliamentary debates spanning over 75 years and compare it with US congressional discourse. Using open-weight LLMs, we annotate each statement with high-level stances toward migrants and track the net tone toward migrants across time and political parties. For the UK, we extend this with a semi-automated framework for extracting fine-grained narrative frames to capture nuances of migration discourse. Our findings show that, while US discourse has grown increasingly polarised, UK parliamentary attitudes remain relatively aligned across parties, with a persistent ideological gap between Labour and the Conservatives, reaching its most negative level in 2025. The analysis of narrative frames in the UK parliamentary statements reveals a shift toward securitised narratives such as border control and illegal immigration, while longer-term integration-oriented frames such as social integration have declined. Moreover, discussions of national law about immigration have been replaced over time by international law and human rights, revealing nuances in discourse trends. Taken together broadly, our findings demonstrate how LLMs can support scalable, fine-grained discourse analysis in political and historical contexts.
AI-Powered Detection of Inappropriate Language in Medical School Curricula
Aug 27, 2025The use of inappropriate language -- such as outdated, exclusionary, or non-patient-centered terms -- medical instructional materials can significantly influence clinical training, patient interactions, and health outcomes. Despite their reputability, many materials developed over past decades contain examples now considered inappropriate by current medical standards. Given the volume of curricular content, manually identifying instances of inappropriate use of language (IUL) and its subcategories for systematic review is prohibitively costly and impractical. To address this challenge, we conduct a first-in-class evaluation of small language models (SLMs) fine-tuned on labeled data and pre-trained LLMs with in-context learning on a dataset containing approximately 500 documents and over 12,000 pages. For SLMs, we consider: (1) a general IUL classifier, (2) subcategory-specific binary classifiers, (3) a multilabel classifier, and (4) a two-stage hierarchical pipeline for general IUL detection followed by multilabel classification. For LLMs, we consider variations of prompts that include subcategory definitions and/or shots. We found that both LLama-3 8B and 70B, even with carefully curated shots, are largely outperformed by SLMs. While the multilabel classifier performs best on annotated data, supplementing training with unflagged excerpts as negative examples boosts the specific classifiers' AUC by up to 25%, making them most effective models for mitigating harmful language in medical curricula.
Why human-AI relationships need socioaffective alignment
Feb 04, 2025Humans strive to design safe AI systems that align with our goals and remain under our control. However, as AI capabilities advance, we face a new challenge: the emergence of deeper, more persistent relationships between humans and AI systems. We explore how increasingly capable AI agents may generate the perception of deeper relationships with users, especially as AI becomes more personalised and agentic. This shift, from transactional interaction to ongoing sustained social engagement with AI, necessitates a new focus on socioaffective alignment-how an AI system behaves within the social and psychological ecosystem co-created with its user, where preferences and perceptions evolve through mutual influence. Addressing these dynamics involves resolving key intrapersonal dilemmas, including balancing immediate versus long-term well-being, protecting autonomy, and managing AI companionship alongside the desire to preserve human social bonds. By framing these challenges through a notion of basic psychological needs, we seek AI systems that support, rather than exploit, our fundamental nature as social and emotional beings.
HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter
Nov 23, 2024
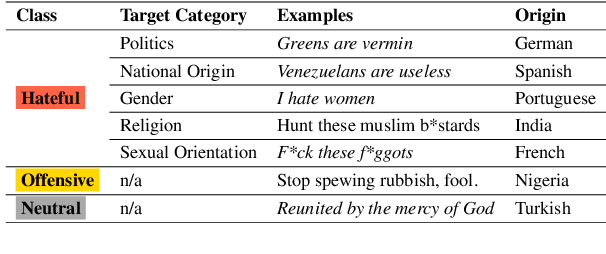
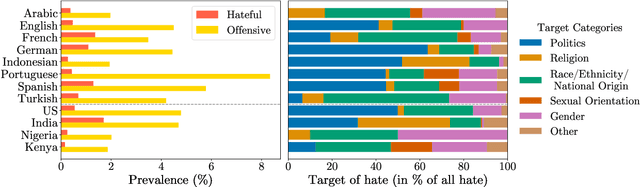

To tackle the global challenge of online hate speech, a large body of research has developed detection models to flag hate speech in the sea of online content. Yet, due to systematic biases in evaluation datasets, detection performance in real-world settings remains unclear, let alone across geographies. To address this issue, we introduce HateDay, the first global hate speech dataset representative of social media settings, randomly sampled from all tweets posted on September 21, 2022 for eight languages and four English-speaking countries. Using HateDay, we show how the prevalence and composition of hate speech varies across languages and countries. We also find that evaluation on academic hate speech datasets overestimates real-world detection performance, which we find is very low, especially for non-European languages. We identify several factors explaining poor performance, including models' inability to distinguish between hate and offensive speech, and the misalignment between academic target focus and real-world target prevalence. We finally argue that such low performance renders hate speech moderation with public detection models unfeasible, even in a human-in-the-loop setting which we find is prohibitively costly. Overall, we emphasize the need to evaluate future detection models from academia and platforms in real-world settings to address this global challenge.
LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low-Resource and Extinct Languages
Jun 11, 2024



In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.
SynDy: Synthetic Dynamic Dataset Generation Framework for Misinformation Tasks
May 17, 2024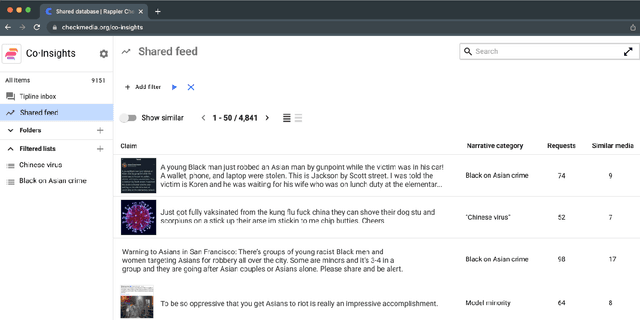
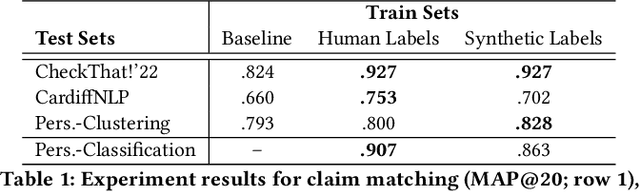
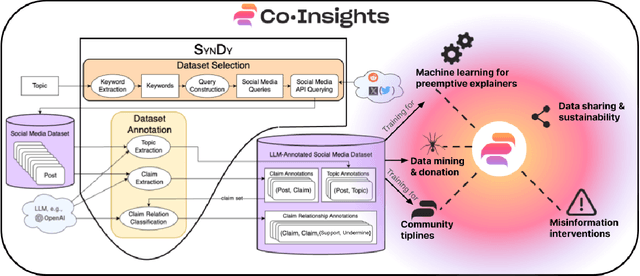
Diaspora communities are disproportionately impacted by off-the-radar misinformation and often neglected by mainstream fact-checking efforts, creating a critical need to scale-up efforts of nascent fact-checking initiatives. In this paper we present SynDy, a framework for Synthetic Dynamic Dataset Generation to leverage the capabilities of the largest frontier Large Language Models (LLMs) to train local, specialized language models. To the best of our knowledge, SynDy is the first paper utilizing LLMs to create fine-grained synthetic labels for tasks of direct relevance to misinformation mitigation, namely Claim Matching, Topical Clustering, and Claim Relationship Classification. SynDy utilizes LLMs and social media queries to automatically generate distantly-supervised, topically-focused datasets with synthetic labels on these three tasks, providing essential tools to scale up human-led fact-checking at a fraction of the cost of human-annotated data. Training on SynDy's generated labels shows improvement over a standard baseline and is not significantly worse compared to training on human labels (which may be infeasible to acquire). SynDy is being integrated into Meedan's chatbot tiplines that are used by over 50 organizations, serve over 230K users annually, and automatically distribute human-written fact-checks via messaging apps such as WhatsApp. SynDy will also be integrated into our deployed Co-Insights toolkit, enabling low-resource organizations to launch tiplines for their communities. Finally, we envision SynDy enabling additional fact-checking tools such as matching new misinformation claims to high-quality explainers on common misinformation topics.
Global News Synchrony and Diversity During the Start of the COVID-19 Pandemic
May 01, 2024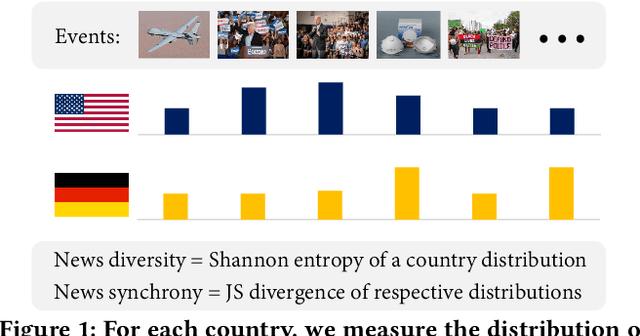
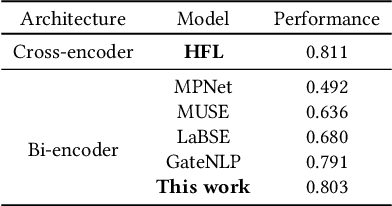
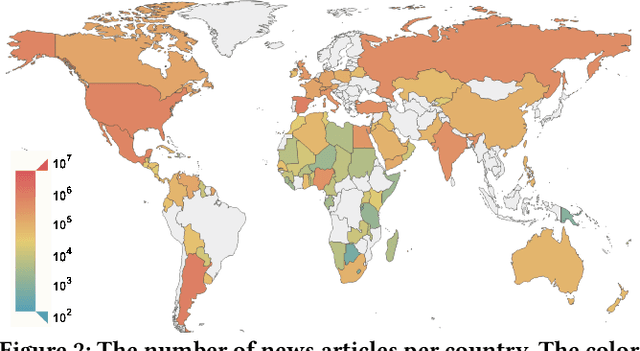

News coverage profoundly affects how countries and individuals behave in international relations. Yet, we have little empirical evidence of how news coverage varies across countries. To enable studies of global news coverage, we develop an efficient computational methodology that comprises three components: (i) a transformer model to estimate multilingual news similarity; (ii) a global event identification system that clusters news based on a similarity network of news articles; and (iii) measures of news synchrony across countries and news diversity within a country, based on country-specific distributions of news coverage of the global events. Each component achieves state-of-the art performance, scaling seamlessly to massive datasets of millions of news articles. We apply the methodology to 60 million news articles published globally between January 1 and June 30, 2020, across 124 countries and 10 languages, detecting 4357 news events. We identify the factors explaining diversity and synchrony of news coverage across countries. Our study reveals that news media tend to cover a more diverse set of events in countries with larger Internet penetration, more official languages, larger religious diversity, higher economic inequality, and larger populations. Coverage of news events is more synchronized between countries that not only actively participate in commercial and political relations -- such as, pairs of countries with high bilateral trade volume, and countries that belong to the NATO military alliance or BRICS group of major emerging economies -- but also countries that share certain traits: an official language, high GDP, and high democracy indices.
From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
Apr 27, 2024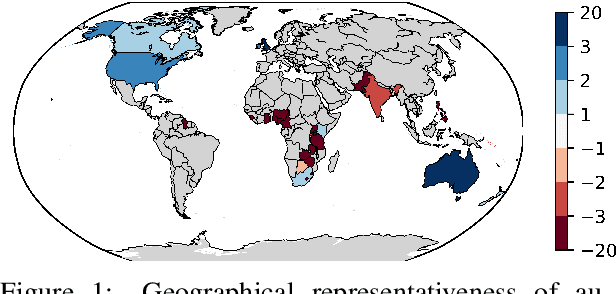
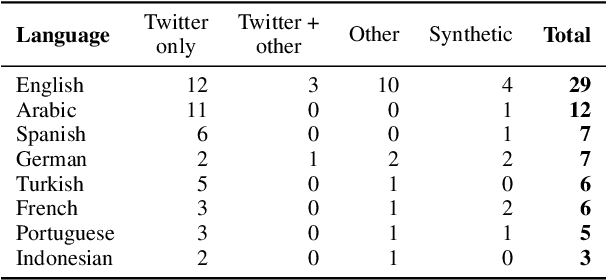
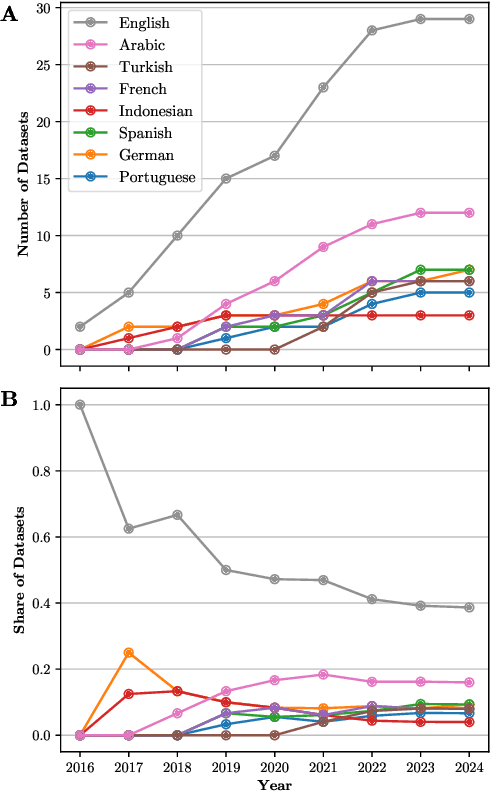
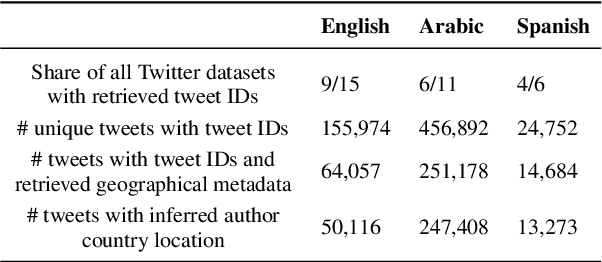
Perceptions of hate can vary greatly across cultural contexts. Hate speech (HS) datasets, however, have traditionally been developed by language. This hides potential cultural biases, as one language may be spoken in different countries home to different cultures. In this work, we evaluate cultural bias in HS datasets by leveraging two interrelated cultural proxies: language and geography. We conduct a systematic survey of HS datasets in eight languages and confirm past findings on their English-language bias, but also show that this bias has been steadily decreasing in the past few years. For three geographically-widespread languages -- English, Arabic and Spanish -- we then leverage geographical metadata from tweets to approximate geo-cultural contexts by pairing language and country information. We find that HS datasets for these languages exhibit a strong geo-cultural bias, largely overrepresenting a handful of countries (e.g., US and UK for English) relative to their prominence in both the broader social media population and the general population speaking these languages. Based on these findings, we formulate recommendations for the creation of future HS datasets.
The PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
Apr 24, 2024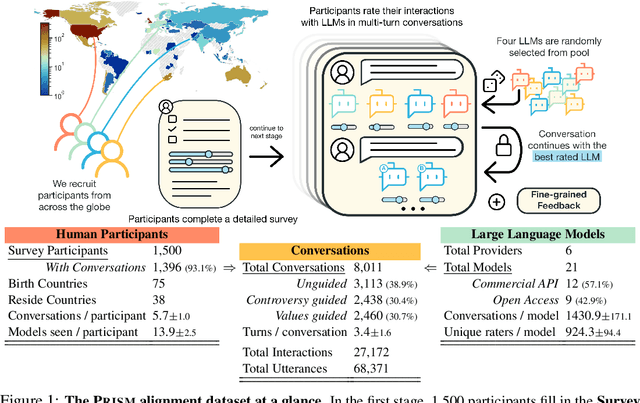
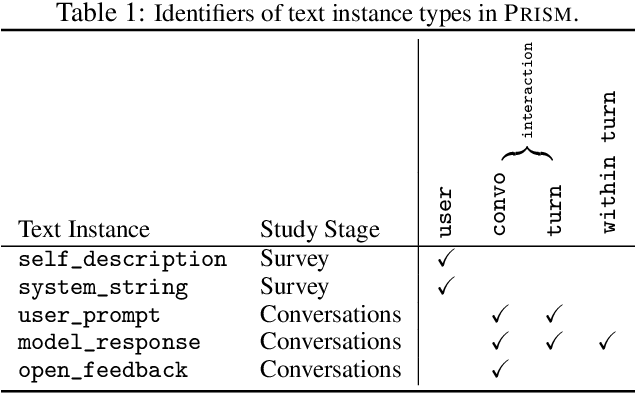
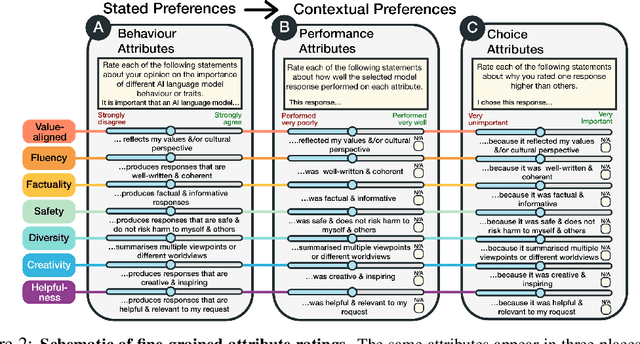

Human feedback plays a central role in the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of human feedback collection. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. PRISM contributes (i) wide geographic and demographic participation in human feedback data; (ii) two census-representative samples for understanding collective welfare (UK and US); and (iii) individualised feedback where every rating is linked to a detailed participant profile, thus permitting exploration of personalisation and attribution of sample artefacts. We focus on collecting conversations that centre subjective and multicultural perspectives on value-laden and controversial topics, where we expect the most interpersonal and cross-cultural disagreement. We demonstrate the usefulness of PRISM via three case studies of dialogue diversity, preference diversity, and welfare outcomes, showing that it matters which humans set alignment norms. As well as offering a rich community resource, we advocate for broader participation in AI development and a more inclusive approach to technology design.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.