 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemographic Probing of Large Language Models Lacks Construct Validity
Jan 26, 2026Demographic probing is widely used to study how large language models (LLMs) adapt their behavior to signaled demographic attributes. This approach typically uses a single demographic cue in isolation (e.g., a name or dialect) as a signal for group membership, implicitly assuming strong construct validity: that such cues are interchangeable operationalizations of the same underlying, demographically conditioned behavior. We test this assumption in realistic advice-seeking interactions, focusing on race and gender in a U.S. context. We find that cues intended to represent the same demographic group induce only partially overlapping changes in model behavior, while differentiation between groups within a given cue is weak and uneven. Consequently, estimated disparities are unstable, with both magnitude and direction varying across cues. We further show that these inconsistencies partly arise from variation in how strongly cues encode demographic attributes and from linguistic confounders that independently shape model behavior. Together, our findings suggest that demographic probing lacks construct validity: it does not yield a single, stable characterization of how LLMs condition on demographic information, which may reflect a misspecified or fragmented construct. We conclude by recommending the use of multiple, ecologically valid cues and explicit control of confounders to support more defensible claims about demographic effects in LLMs.
HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter
Nov 23, 2024
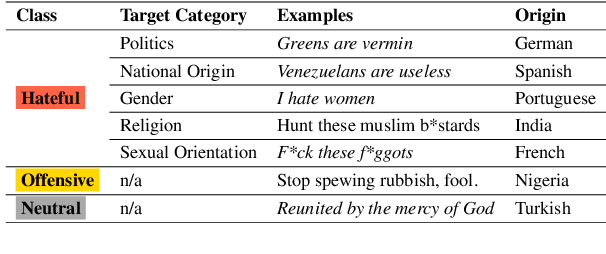
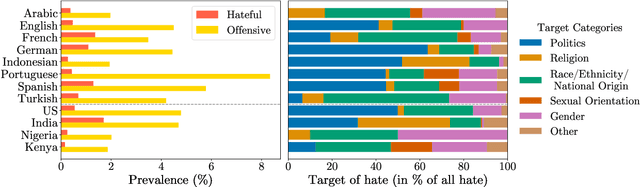

To tackle the global challenge of online hate speech, a large body of research has developed detection models to flag hate speech in the sea of online content. Yet, due to systematic biases in evaluation datasets, detection performance in real-world settings remains unclear, let alone across geographies. To address this issue, we introduce HateDay, the first global hate speech dataset representative of social media settings, randomly sampled from all tweets posted on September 21, 2022 for eight languages and four English-speaking countries. Using HateDay, we show how the prevalence and composition of hate speech varies across languages and countries. We also find that evaluation on academic hate speech datasets overestimates real-world detection performance, which we find is very low, especially for non-European languages. We identify several factors explaining poor performance, including models' inability to distinguish between hate and offensive speech, and the misalignment between academic target focus and real-world target prevalence. We finally argue that such low performance renders hate speech moderation with public detection models unfeasible, even in a human-in-the-loop setting which we find is prohibitively costly. Overall, we emphasize the need to evaluate future detection models from academia and platforms in real-world settings to address this global challenge.