 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemographic Probing of Large Language Models Lacks Construct Validity
Jan 26, 2026Demographic probing is widely used to study how large language models (LLMs) adapt their behavior to signaled demographic attributes. This approach typically uses a single demographic cue in isolation (e.g., a name or dialect) as a signal for group membership, implicitly assuming strong construct validity: that such cues are interchangeable operationalizations of the same underlying, demographically conditioned behavior. We test this assumption in realistic advice-seeking interactions, focusing on race and gender in a U.S. context. We find that cues intended to represent the same demographic group induce only partially overlapping changes in model behavior, while differentiation between groups within a given cue is weak and uneven. Consequently, estimated disparities are unstable, with both magnitude and direction varying across cues. We further show that these inconsistencies partly arise from variation in how strongly cues encode demographic attributes and from linguistic confounders that independently shape model behavior. Together, our findings suggest that demographic probing lacks construct validity: it does not yield a single, stable characterization of how LLMs condition on demographic information, which may reflect a misspecified or fragmented construct. We conclude by recommending the use of multiple, ecologically valid cues and explicit control of confounders to support more defensible claims about demographic effects in LLMs.
Real-Time Deadlines Reveal Temporal Awareness Failures in LLM Strategic Dialogues
Jan 19, 2026Large Language Models (LLMs) generate text token-by-token in discrete time, yet real-world communication, from therapy sessions to business negotiations, critically depends on continuous time constraints. Current LLM architectures and evaluation protocols rarely test for temporal awareness under real-time deadlines. We use simulated negotiations between paired agents under strict deadlines to investigate how LLMs adjust their behavior in time-sensitive settings. In a control condition, agents know only the global time limit. In a time-aware condition, they receive remaining-time updates at each turn. Deal closure rates are substantially higher (32\% vs. 4\% for GPT-5.1) and offer acceptances are sixfold higher in the time-aware condition than in the control, suggesting LLMs struggle to internally track elapsed time. However, the same LLMs achieve near-perfect deal closure rates ($\geq$95\%) under turn-based limits, revealing the failure is in temporal tracking rather than strategic reasoning. These effects replicate across negotiation scenarios and models, illustrating a systematic lack of LLM time awareness that will constrain LLM deployment in many time-sensitive applications.
A Concise Agent is Less Expert: Revealing Side Effects of Using Style Features on Conversational Agents
Jan 15, 2026Style features such as friendly, helpful, or concise are widely used in prompts to steer the behavior of Large Language Model (LLM) conversational agents, yet their unintended side effects remain poorly understood. In this work, we present the first systematic study of cross-feature stylistic side effects. We conduct a comprehensive survey of 127 conversational agent papers from ACL Anthology and identify 12 frequently used style features. Using controlled, synthetic dialogues across task-oriented and open domain settings, we quantify how prompting for one style feature causally affects others via a pairwise LLM as a Judge evaluation framework. Our results reveal consistent and structured side effects, such as prompting for conciseness significantly reduces perceived expertise. They demonstrate that style features are deeply entangled rather than orthogonal. To support future research, we introduce CASSE (Conversational Agent Stylistic Side Effects), a dataset capturing these complex interactions. We further evaluate prompt based and activation steering based mitigation strategies and find that while they can partially restore suppressed traits, they often degrade the primary intended style. These findings challenge the assumption of faithful style control in LLMs and highlight the need for multi-objective and more principled approaches to safe, targeted stylistic steering in conversational agents.
Herd Behavior: Investigating Peer Influence in LLM-based Multi-Agent Systems
May 27, 2025Recent advancements in Large Language Models (LLMs) have enabled the emergence of multi-agent systems where LLMs interact, collaborate, and make decisions in shared environments. While individual model behavior has been extensively studied, the dynamics of peer influence in such systems remain underexplored. In this paper, we investigate herd behavior, the tendency of agents to align their outputs with those of their peers, within LLM-based multi-agent interactions. We present a series of controlled experiments that reveal how herd behaviors are shaped by multiple factors. First, we show that the gap between self-confidence and perceived confidence in peers significantly impacts an agent's likelihood to conform. Second, we find that the format in which peer information is presented plays a critical role in modulating the strength of herd behavior. Finally, we demonstrate that the degree of herd behavior can be systematically controlled, and that appropriately calibrated herd tendencies can enhance collaborative outcomes. These findings offer new insights into the social dynamics of LLM-based systems and open pathways for designing more effective and adaptive multi-agent collaboration frameworks.
Uncertainty-Aware Crime Prediction With Spatial Temporal Multivariate Graph Neural Networks
Aug 08, 2024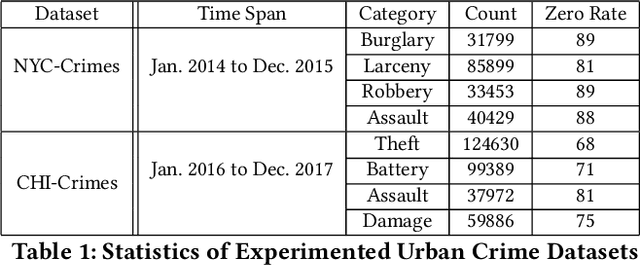
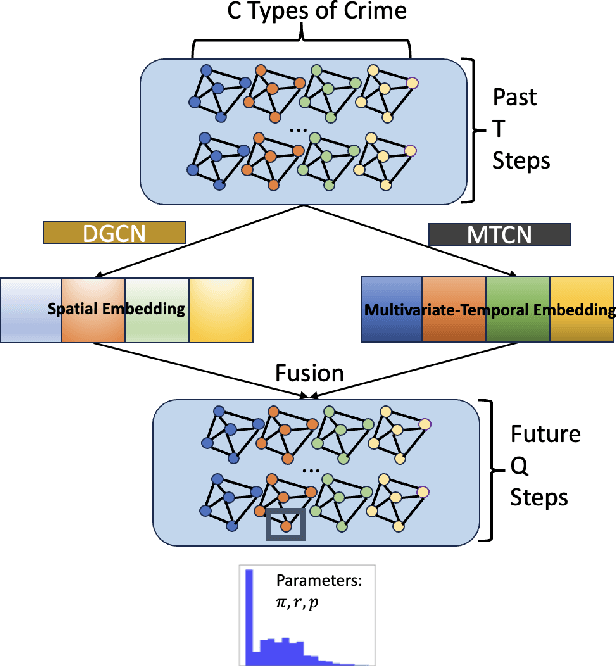
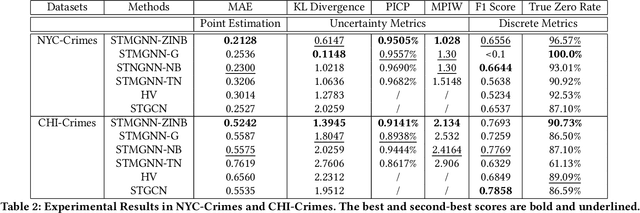
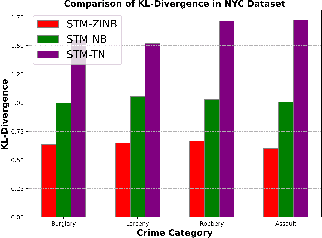
Crime forecasting is a critical component of urban analysis and essential for stabilizing society today. Unlike other time series forecasting problems, crime incidents are sparse, particularly in small regions and within specific time periods. Traditional spatial-temporal deep learning models often struggle with this sparsity, as they typically cannot effectively handle the non-Gaussian nature of crime data, which is characterized by numerous zeros and over-dispersed patterns. To address these challenges, we introduce a novel approach termed Spatial Temporal Multivariate Zero-Inflated Negative Binomial Graph Neural Networks (STMGNN-ZINB). This framework leverages diffusion and convolution networks to analyze spatial, temporal, and multivariate correlations, enabling the parameterization of probabilistic distributions of crime incidents. By incorporating a Zero-Inflated Negative Binomial model, STMGNN-ZINB effectively manages the sparse nature of crime data, enhancing prediction accuracy and the precision of confidence intervals. Our evaluation on real-world datasets confirms that STMGNN-ZINB outperforms existing models, providing a more reliable tool for predicting and understanding crime dynamics.
Building Knowledge-Guided Lexica to Model Cultural Variation
Jun 17, 2024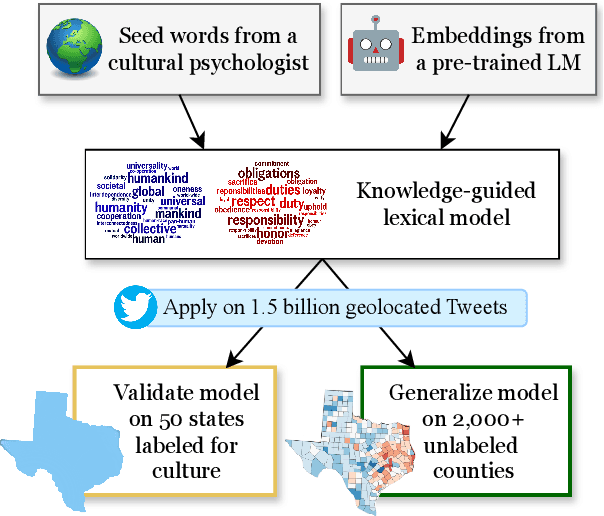

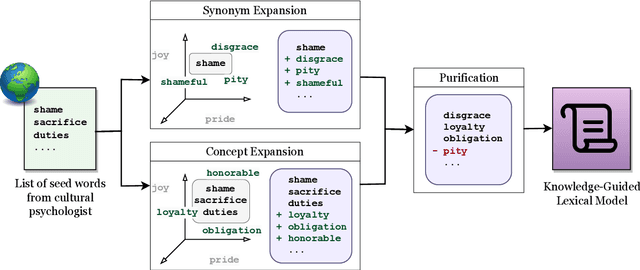
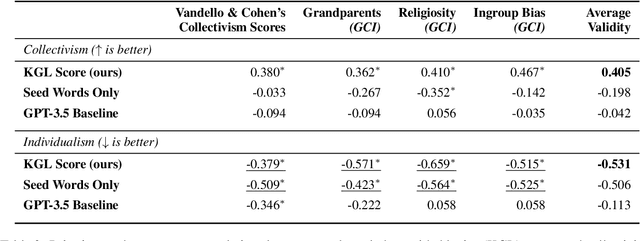
Cultural variation exists between nations (e.g., the United States vs. China), but also within regions (e.g., California vs. Texas, Los Angeles vs. San Francisco). Measuring this regional cultural variation can illuminate how and why people think and behave differently. Historically, it has been difficult to computationally model cultural variation due to a lack of training data and scalability constraints. In this work, we introduce a new research problem for the NLP community: How do we measure variation in cultural constructs across regions using language? We then provide a scalable solution: building knowledge-guided lexica to model cultural variation, encouraging future work at the intersection of NLP and cultural understanding. We also highlight modern LLMs' failure to measure cultural variation or generate culturally varied language.
Language-based Valence and Arousal Expressions between the United States and China: a Cross-Cultural Examination
Jan 11, 2024Although affective expressions of individuals have been extensively studied using social media, research has primarily focused on the Western context. There are substantial differences among cultures that contribute to their affective expressions. This paper examines the differences between Twitter (X) in the United States and Sina Weibo posts in China on two primary dimensions of affect - valence and arousal. We study the difference in the functional relationship between arousal and valence (so-called V-shaped) among individuals in the US and China and explore the associated content differences. Furthermore, we correlate word usage and topics in both platforms to interpret their differences. We observe that for Twitter users, the variation in emotional intensity is less distinct between negative and positive emotions compared to Weibo users, and there is a sharper escalation in arousal corresponding with heightened emotions. From language features, we discover that affective expressions are associated with personal life and feelings on Twitter, while on Weibo such discussions are about socio-political topics in the society. These results suggest a West-East difference in the V-shaped relationship between valence and arousal of affective expressions on social media influenced by content differences. Our findings have implications for applications and theories related to cultural differences in affective expressions.
An Integrative Survey on Mental Health Conversational Agents to Bridge Computer Science and Medical Perspectives
Oct 25, 2023



Mental health conversational agents (a.k.a. chatbots) are widely studied for their potential to offer accessible support to those experiencing mental health challenges. Previous surveys on the topic primarily consider papers published in either computer science or medicine, leading to a divide in understanding and hindering the sharing of beneficial knowledge between both domains. To bridge this gap, we conduct a comprehensive literature review using the PRISMA framework, reviewing 534 papers published in both computer science and medicine. Our systematic review reveals 136 key papers on building mental health-related conversational agents with diverse characteristics of modeling and experimental design techniques. We find that computer science papers focus on LLM techniques and evaluating response quality using automated metrics with little attention to the application while medical papers use rule-based conversational agents and outcome metrics to measure the health outcomes of participants. Based on our findings on transparency, ethics, and cultural heterogeneity in this review, we provide a few recommendations to help bridge the disciplinary divide and enable the cross-disciplinary development of mental health conversational agents.
Historical patterns of rice farming explain modern-day language use in China and Japan more than modernization and urbanization
Aug 29, 2023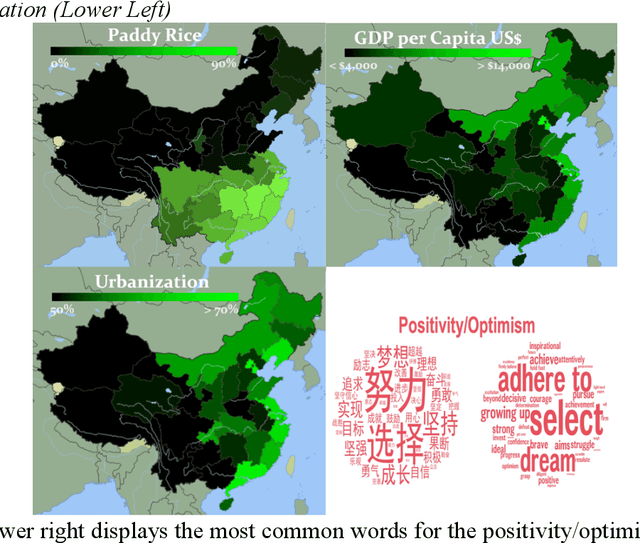


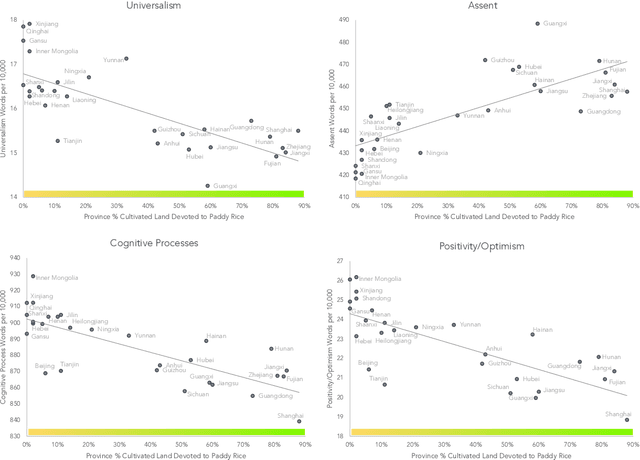
We used natural language processing to analyze a billion words to study cultural differences on Weibo, one of China's largest social media platforms. We compared predictions from two common explanations about cultural differences in China (economic development and urban-rural differences) against the less-obvious legacy of rice versus wheat farming. Rice farmers had to coordinate shared irrigation networks and exchange labor to cope with higher labor requirements. In contrast, wheat relied on rainfall and required half as much labor. We test whether this legacy made southern China more interdependent. Across all word categories, rice explained twice as much variance as economic development and urbanization. Rice areas used more words reflecting tight social ties, holistic thought, and a cautious, prevention orientation. We then used Twitter data comparing prefectures in Japan, which largely replicated the results from China. This provides crucial evidence of the rice theory in a different nation, language, and platform.
Multilingual Language Models are not Multicultural: A Case Study in Emotion
Jul 09, 2023



Emotions are experienced and expressed differently across the world. In order to use Large Language Models (LMs) for multilingual tasks that require emotional sensitivity, LMs must reflect this cultural variation in emotion. In this study, we investigate whether the widely-used multilingual LMs in 2023 reflect differences in emotional expressions across cultures and languages. We find that embeddings obtained from LMs (e.g., XLM-RoBERTa) are Anglocentric, and generative LMs (e.g., ChatGPT) reflect Western norms, even when responding to prompts in other languages. Our results show that multilingual LMs do not successfully learn the culturally appropriate nuances of emotion and we highlight possible research directions towards correcting this.